引
本期的PaperWeekly一共分享四篇最近arXiv上发布的高质量paper,包括:情感分析、机器阅读理解、知识图谱、文本分类。人工智能及其相关研究日新月异,本文将带着大家了解一下以上四个研究方向都有哪些最新进展。四篇paper分别是:
-
Linguistically Regularized LSTMs for Sentiment Classification, 2016.11
-
End-to-End Answer Chunk Extraction and Ranking for Reading Comprehension, 2016.10
-
Knowledge will Propel Machine Understanding of Content: Extrapolating from Current Examples, 2016.10
-
AC-BLSTM: Asymmetric Convolutional Bidirectional LSTM Networks for Text Classification, 2016.11
1.Linguistically Regularized LSTMs for Sentiment Classification
作者
Qiao Qian, Minlie Huang, Xiaoyan Zhu
单位
State Key Lab. of Intelligent Technology and Systems, National Lab. for Information Science and Technology, Dept. of Computer Science and Technology, Tsinghua University
关键词
sentiment classification, neural network models, linguistically coherent representations,
文章来源
arXiv, 2016.11
问题
利用语言资源和神经网络相结合来提升情感分类问题的精度
模型
在LSTM和Bi-LSTM模型的基础上加入四种规则约束,这四种规则分别是: Non-Sentiment Regularizer,Sentiment Regularizer, Negation Regularizer, Intensity Regularizer.因此,新的loss function变为:
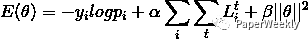
不同的规则约束对应不同的L函数
资源
1、Movie Review (MR)
https://www.cs.cornell.edu/people/pabo/movie-review-data/
2、Stanford Sentiment Tree- bank (SST)
http://nlp.stanford.edu/sentiment/treebank.html
相关工作
1、Neural Networks for Sentiment Classification
Empirical evaluation of gated recurrent neural networks on sequence modeling
Hybrid speech recognition with deep bidirectional lstm
2、Applying Linguistic Knowledge for Sentiment Classification
Sentiment classification of movie reviews using contextual valence shifters
简评
本文提出了一种新的基于语言资源约束和LSTM/Bi-LSTM的模型用于情感分类,并通过在MR和SST数据集上的实验和对RNN/RNTN,LSTM,Tree-LSTM,CNN的效果对比证明了这一模型的有效性。除此之外,本文还基于不同的约束进行了实验,证明的不同的约束在提高分类精度上的作用。本文实验丰富,效果的提升虽不显著,但新的模型确实在不同程度上克服了旧模型的一些不足。
2.End-to-End Answer Chunk Extraction and Ranking for Reading Comprehension
作者
Yang Yu, Wei Zhang, Kazi Hasan, Mo Yu, Bing Xiang, Bowen Zhou
单位
IBM Watson
关键词
Reading Comprehension, Chunk extraction, Ranking
文章来源
arXiv, 2016.10
问题
针对答案非定长的阅读理解任务,本文提出了DCR(dynamic chunk reader)模型,来从给定的文档中抽取可能的候选答案并进行排序。
模型
本文提出的模型结构共分为四部分,
1、Encoder Layer
如图所示,这部分是用双向GRU分别对文档(Passage)和问题(Question)进行编码。
2、Attention Layer
该层采用的方法与相关工作中的mLSTM类似,文档每个时刻的状态hjp都与问题中的每个状态hkq进行匹配得到一个权重向量αk,然后再根据该权重向量对问题的GRU隐层输出hp进行加权求和,得到文档中该时刻状态hjp对应的上下文向量βj,两个向量hjp和βj拼接在一起作为该时刻新的表示vj。最后再将上述与问题相关的新文档表示v通过双向GRU,得到文档最终的表示γ。
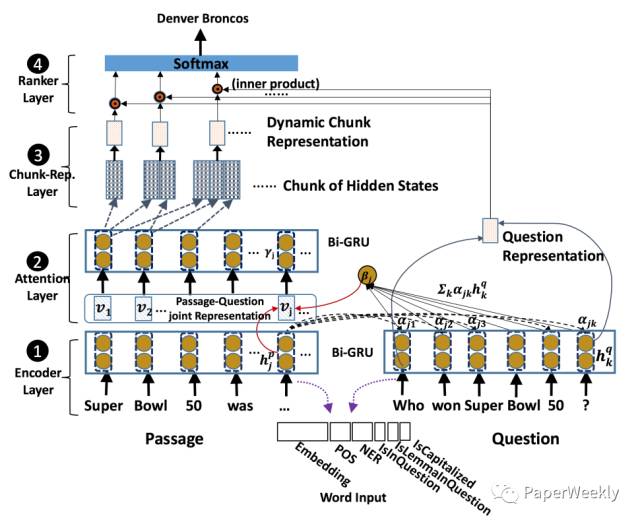
3、Chunk-Representation Layer
上一部分获得了与问题相关的文档表示γ,那么这部分则是考虑如何抽取候选答案,并获得候选答案的表示向量。本文提出了两种候选答案抽取方法,第一种方法是抽取所有满足训练数据中答案对应词性标注模式的候选项,第二种方法则是简单粗暴地确定一个候选项最大长度,然后遍历所有可能的候选项。至于候选答案的表示方式,本文将候选答案前向GRU的最后一个时刻状态和反向GRU第一个时刻状态拼接在一起作为最终候选项的表示。
4、Ranker Layer
已经获得了所有候选项的表示,那么接着就是对所有候选项进行打分排序。本文中打分是采用问题的表示和候选项的表示计算内积的方式得到的,本文训练过程中没有采用常见于排序任务的Margin ranking loss,而是先用softmax对所有候选项计算一个概率值,然后采用交叉熵损失函数进行训练。
本文在SQuAD数据集上进行实验,提出的方法效果比之前两篇SQuAD相关paper的方法有较大的提升。
资源
1、SQuAD
https://rajpurkar.github.io/SQuAD-explorer/
相关工作
1、数据集相关论文
SQuAD: 100,000+ Questions for Machine Comprehension of Text
2、模型相关论文
MACHINE COMPREHENSION USING MATCH-LSTM
简评
在对文档和问题编码阶段,本篇论文提出的模型与之前mLSTM那篇paper有些相似。两篇论文中模型的主要区别在于:mLSTM那篇论文采用预测起始、终止位置的方法来确定答案,而本文则是先采用一些规则或Pattern的方法来抽取一些候选答案,然后再对候选答案进行排序。
联系方式
有DL或者NLP相关话题,欢迎讨论。destin.bxwang@gmail.com
3.Knowledge will Propel Machine Understanding of Content: Extrapolating from Current Examples
作者
Amit Sheth, Sujan Perera, and Sanjaya Wijeratne
单位









