数据分析 粉丝交流群 第三批五个交流群
spss交流群:131233140 ; r与python交流群:275208364 ;
游戏分析交流群:60974760 ; 人工智能群:257972325 ;
机器学习群: 139482724 ;
上篇文章阅读:推荐 :深度学习初学者不可不知的25个术语和概念(上)
人工智能,深度学习和机器学习,不论你现在是否能够理解这些概念,你都应该学习。否则三年内,你就会像灭绝的恐龙一样被社会淘汰。
——马克·库班(NBA小牛队老板,亿万富翁)
6) 输入层/输出层/隐藏层——顾名思义,输入层是接收输入信号的一层,也是该网络的第一层;输出层则是传递输出信号的一层,也是该网络的最后一层。
处理层则是该网络中的“隐含层”。这些“隐含层”将对输入信号进行特殊处理,并将生成的输出信号传递到下一层。输入层和输出层均是可见的,而其中间层则是隐藏起来的。
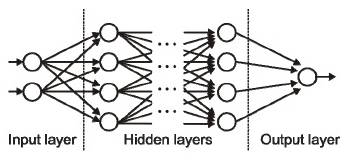
7) MLP (多层神经网络) –——MLP(多层神经网络) – 单一神经元无法执行高度复杂的任务。因此,需要大量神经元聚集在一起才能生成我们所需要的输出信号。
最简单的网络由一个输入层、一个输出层、一个隐含层组成,每一层上都有多个神经元,并且每一层上的神经元都和下一层上的神经元连接在了一起,这样的网络也被称为全互连网络(fully connected networks)。
8) 正向传播(Forward Propagation) –——正向传播指的是输入信号通过隐藏层传递到输出层的传递过程。
在正向传播中,信号仅沿单一方向向前正向传播,输入层将输入信号提供给隐藏层,隐藏层生成输出信号,这一过程中没有任何反向移动。
9) 成本函数(Cost Function) –——当我们建立一个网络后,网络将尽可能地使输出值无限接近于实际值。我们用成本函数(或损失函数)来衡量该网络完成这一过程的准确性。成本函数(或损失函数)将在该网络出错时,予以警告。
运行网络时,我们的目标是:尽可能地提高我们的预测精度、减少误差,由此最小化成本函数。最优化的输出即当成本函数(或损失函数)为最小值时的输出。
若将成本函数定义为均方误差,则可写成:
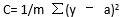
m在这里是训练输入值(training inputs),a 是预计值,y是特定事例中的实际值。
学习过程围绕着如何最小化成本。
10) 梯度下降(Gradient Descent) –——梯度下降是一种优化算法,以最小化成本。想象一下,当你下山时,你必须一小步一小步往下走,而不是纵身一跃跳到山脚。
因此,我们要做的是:比如,我们从X点开始下降,我们下降一点点,下降ΔH,到现在的位置,也就是X-ΔH,重复这一过程,直到我们到达“山脚”。“山脚”就是最低成本点。
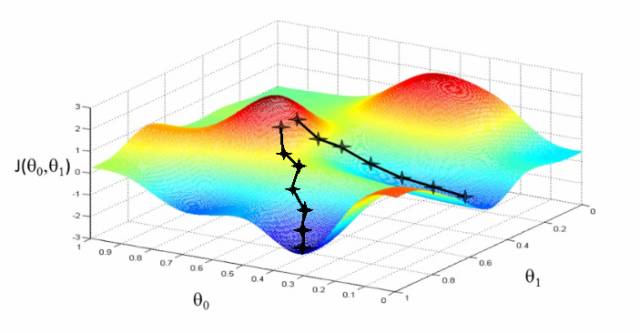
从数学的角度来说,要找到函数的局部极小值,须采取与函数梯度负相关的“步子”,即:梯度下降法是用负梯度方向为搜索方向的,梯度下降法越接近目标值,步长越小,前进越慢。
11) 学习速率 (Learning Rate) –——学习率指每次迭代中对成本函数的最小化次数。简单来说,我们把下降到成本函数最小值的速率称为学习率。选择学习率时,我们必须非常小心,学习率既不应过大——会错过最优解,也不应过小——使网络收敛将需要很多很多步、甚至永不可能。
12) 反向传播(Back propagation) –——在定义一个神经网络的过程中, 每个节点会被随机地分配权重和偏置。
一次迭代后,我们可以根据产生的结果计算出整个网络的偏差,然后用偏差结合成本函数的梯度,对权重因子进行相应的调整,使得下次迭代的过程中偏差变小。
这样一个结合成本函数的梯度来调整权重因子的过程就叫做反向传播。在反向传播中,信号的传递方向是朝后的,误差连同成本函数的梯度从输出层沿着隐藏层传播,同时伴随着对权重因子的调整。
13) 分批 (Batches) —— 当我们训练一个神经网路时,我们不应一次性发送全部输入信号,而应把输入信号随机分成几个大小相同的数据块发送。
与将全部数据一次性送入网络相比,在训练时将数据分批发送,建立的模型会更具有一般性。
14) 周期 (Epochs) —— 一个周期表示对所有的数据批次都进行了一次迭代,包括一次正向传播和一次反向传播,所以一个周期就意味着对所有的输入数据分别进行一次正向传播和反向传播。
训练网络周期的次数是可以选择的,往往周期数越高,模型的准确性就越高,但是,耗时往往就越长。同样你还需要考虑如果周期/纪元的次数过高,那么可能会出现过拟合的情况。
15)Dropout方法 —— Dropout是一个可以阻止网络过拟合的规则化方法。就像它的名字那样,在训练过程中隐藏的某些特定神经元会被忽略掉(drop)。
这意味着网络的训练是在几个不同的结构上完成的。这种dropout的方式就像是一场合奏,多个不同结构网络的输出组合产生最终的输出结果。
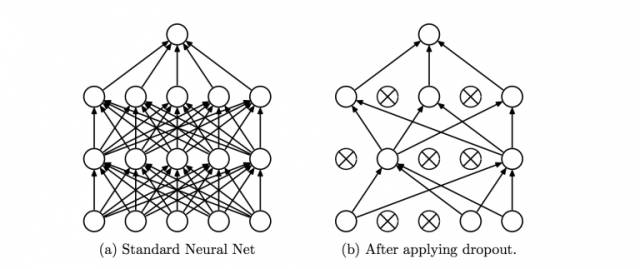
来源:Hinton论文《Improving neural networks by preventing co-adaptation of featuredetectors》
地址:https://arxiv.org/pdf/1207.0580.pdf
16) 分批标准化 (Batch Normalization) –——分批标准化就像是人们在河流中用以监测水位的监察站一样。
这是为了保证下一层网络得到的数据拥有合适的分布。在训练神经网络的过程中,每一次梯度下降后权重因子都会得到改变,从而会改变相应的数据结构。
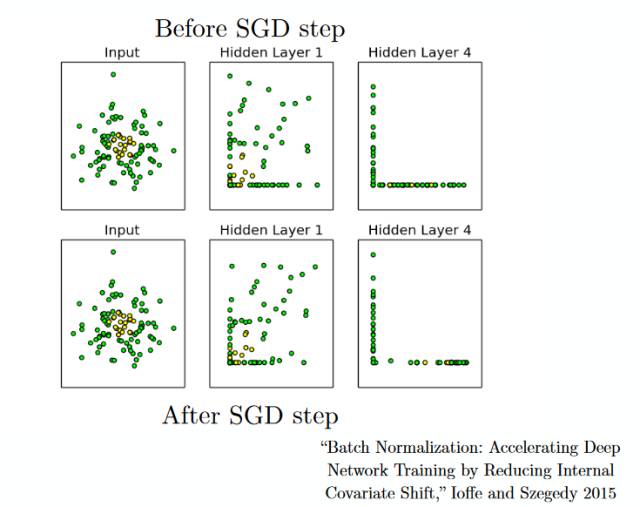
但是下一层网络希望能够得到与之前分布相似的数据,因此在每一次数据传递前都需要对数据进行一次正则化处理。

17) 过滤器/滤波器 (Filters) ——CNN中的滤波器,具体是指将一个权重矩阵乘以输入图像的一个部分,产生相应的卷积输出。
比方说,对于一个28×28的图片而言,将一个3×3的滤波器与图片中3×3的矩阵依次相乘,从而得到相应的卷积输出。
滤波器的尺寸通常比原始图片要小,与权重相似,在最小化成本的反向传播中,滤波器也会被更新。就像下面这张图片一样,通过一个过滤器,依次乘以图片中每个3×3的分块,从而产生卷积的结果。
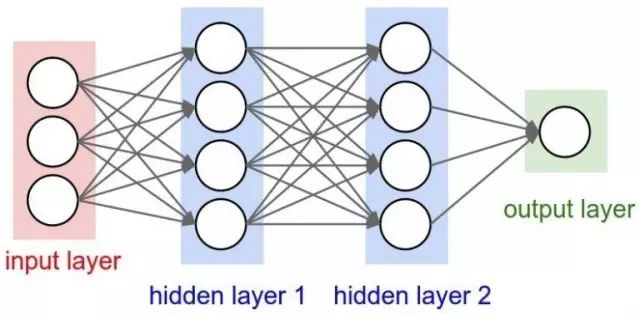
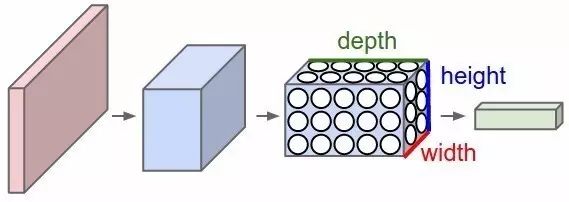
18)卷积神经网络CNN (Convolutional neural network)——卷积神经网络通常用来处理图像数据,假设输入数据的形状。
为28×28×3(28pixels×28pixels×RGBValue),那么对于传统的神经网络来说就会有2352(28×28×3)个变量。随着图像尺寸的增加,那么变量的数量就会急剧增加。
通过对图片进行卷积,可以减少变量的数目(已在过滤器的概念中提及)。随着过滤器沿着图像上宽和高的两个方向滑动,就会产生一个相应的2维激活映射,最后再沿纵向将所有的激活映射堆叠在一起,就产生了最后的输出。
可以参照下面这个示意图。
19) 池化 (Pooling) –为进一步减少变量的数目同时防止过拟合,一种常见的做法是在卷积层中引入池化层(pooling layer)。
最常用的池化层的操作是将原始图片中每个4×4分块取最大值形成一个新的矩阵,这叫做最大值池化(max pooling)。
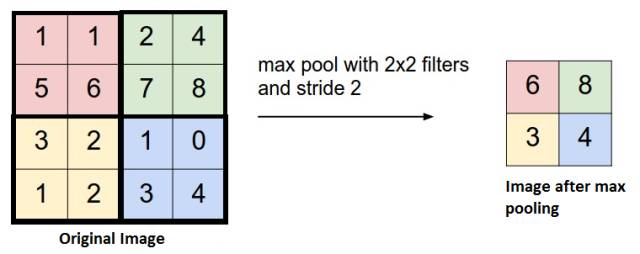
也有人尝试诸如平均池化(average pooling)之类的方式,但在实际情况中最大化池化拥有更好的效果。
20) 补白 (Padding)补白(Padding)通常是指给图像的边缘增加额外的空白,从而使得卷积后输出的图像跟输入图像在尺寸上一致,这也被称作相同补白(Same Padding)。
如应用过滤器,在相同补白的情况下,卷积后的图像大小等于实际图像的大小。
有效补白(Valid Padding)指的是保持图片上每个真实的像素点,不增加空白,因此在经历卷积后数据的尺寸会不断变小。
21) 数据增强 (Data Augmentation) –——数据增强指的是从已有数据中创造出新的数据,通过增加训练量以期望能够提高预测的准确率。
比如,在数字识别中,我们遇到的数字9可能是倾斜或旋转的,因此如果将训练的图片进行适度的旋转,增大训练量,那么模型的准确性就可能会得到提高。
通过“旋转”“照亮”的操作,训练数据的品质得到了提升,这种过程被称作数据增强。

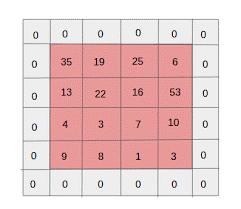
22) 递归神经元 (Recurrent NeuralNetwork) —— 对于递归神经元来说,经由它自己处理过的数据会变成自身下一次的输入,这个过程总共会进行t次。
如下图所示,将递归神经元展开就相当于t个不同的神经元串联起来,这种神经元的长处是能够产生一个更全面的输出结果。
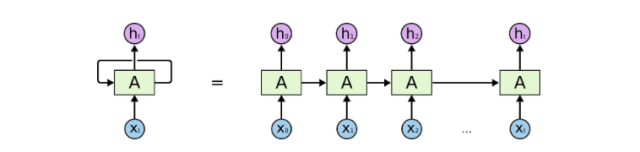
23) 递归神经网络(RNN-Recurrent NeuralNetwork) ——
递归神经网络通常被用于处理序列化的数据,即前一项的输出是用来预测下一项的输入。
递归神经网络通常被用于处理序列化的数据,即前一项的输出是用来预测下一项的输入。递归神经网络中存在环的结构,这些神经元上的环状结构使得它们能够存储之前的数据一段时间,从而使得能够预测输出。
与递归神经元相似,在RNN中隐含层的输出会作为下一次的输入,如此往复经历t次,再将输出的结果传递到下一层网络中。这样,最终输出的结果会更全面,而且之前训练的信息被保持的时间会更久。
隐藏层将反向传递错误以更新权重。这被称为backpropagation through time (BPTT).
24) 梯度消失问题 –——当激活函数的梯度非常小时,会出现梯度消失问题。在反向传播过程中,权重因子会被多次乘以这些小的梯度。
因此会越变越小,随着递归的深入趋于“消失”, 使得神经网络失去了长程可靠性。这在递归神经网络中是一个较普遍的问题,对于递归神经网络而言,长程可靠性尤为重要。
这一问题可通过采用ReLu等没有小梯度的激活函数来有效避免。
25) 梯度爆炸问题 –——梯度爆炸问题与梯度消失问题正好相反,梯度爆炸问题中,激活函数的梯度过大。
在反向传播过程中,部分节点的大梯度使得他们的权重变得非常大,从而削弱了其他节点对于结果的影响,这个问题可以通过截断(即设置一个梯度允许的最大值)的方式来有效避免。
希望你们喜欢这篇文章。
本文对深度学习的基本概念做出了高度的概括,希望各位在阅读这篇文章后,已对这些概念有了初步的了解。 我已尽可能地用最简单的语言来解释这些术语,如有任何疑问或纠正,请随意发表评论。
6) Input/ Output / Hidden Layer – Simply as the name suggests the input layer is theone which receives the input and is essentially the first layer of the network.
The output layer is the one which generates the output or is the final layer ofthe network. The processing layers are the hidden layers within the network.
These hidden layers are the ones which perform specific tasks on the incomingdata and pass on the output generated by them to the next layer.
The input andoutput layers are the ones visible to us, while are the intermediate layers arehidden.
7) MLP(Multi Layer perceptron) – A single neuron would not be able to perform highlycomplex tasks. Therefore, we use stacks of neurons to generate the desiredoutputs.
In the simplest network we would have an input layer, a hidden layerand an output layer.
Each layer has multiple neurons and all the neurons ineach layer are connected to all the neurons in the next layer. These networks canalso be called as fully connected networks.
8)Forward Propagation – Forward Propagation refers to the movement of the inputthrough the hidden layers to the output layers.
In forward propagation, theinformation travels in a single direction FORWARD. The input layer supplies theinput to the hidden layers and then the output is generated. There is nobackward movement.
9) CostFunction – When we build a network, the network tries to predict the output asclose as possible to the actual value.
We measure this accuracy of the networkusing the cost/loss function. The cost or loss function tries to penalize thenetwork when it makes errors.
Ourobjective while running the network is to increase our prediction accuracy andto reduce the error, hence minimizing the cost function. The most optimizedoutput is the one with least value of the cost or loss function.
If Idefine the cost function to be the mean squared error, it can be written as –
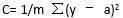 where m is the number of traininginputs, a is the predicted value and y is the actual value of that particularexample.
where m is the number of traininginputs, a is the predicted value and y is the actual value of that particularexample.
Thelearning process revolves around minimizing the cost.
10)Gradient Descent – Gradient descent is an optimization algorithm for minimizingthe cost. To think of it intuitively, while climbing down a hill you shouldtake small steps and walk down instead of just jumping down at once.
Therefore,what we do is, if we start from a point x, we move down a little i.e. delta h,and update our position to x-delta h and we keep doing the same till we reachthe bottom. Consider bottom to be the minimum cost point.
Mathematically,to find the local minimum of a function one takes steps proportional to thenegative of the gradient of the function.
You cango through this article for a detailed understanding of gradient descent.
11)Learning Rate – The learning rate is defined as the amount of minimization inthe cost function in each iteration. In simple terms, the rate at which wedescend towards the minima of the cost function is the learning rate.
We shouldchoose the learning rate very carefully since it should neither be very largethat the optimal solution is missed and nor should be very low that it takesforever for the network to converge.
12)Backpropagation – When we define a neural network, we assign random weights andbias values to our nodes. Once we have received the output for a singleiteration, we can calculate the error of the network.
This error is then fedback to the network along with the gradient of the cost function to update theweights of the network.
These weights are then updated so that the errors inthe subsequent iterations is reduced. This updating of weights using thegradient of the cost function is known as back-propagation.
Inback-propagation the movement of the network is backwards, the error along withthe gradient flows back from the out layer through the hidden layers and theweights are updated.
13)Batches – While training a neural network, instead of sending the entire inputin one go, we divide in input into several chunks of equal size randomly.
Training the data on batches makes the model more generalized as compared tothe model built when the entire data set is fed to the network in one go.
14)Epochs – An epoch is defined as a single training iteration of all batches inboth forward and back propagation. This means 1 epoch is a single forward andbackward pass of the entire input data.
Thenumber of epochs you would use to train your network can be chosen by you. It’shighly likely that more number of epochs would show higher accuracy of thenetwork.
however, it would also take longer for the network to converge. Alsoyou must take care that if the number of epochs are too high, the network mightbe over-fit.
15)Dropout – Dropout is a regularization technique which prevents over-fitting ofthe network. As the name suggests, during training a certain number of neuronsin the hidden layer is randomly dropped.
This means that the training happenson several architectures of the neural network on different combinations of theneurons.
You can think of drop out as an ensemble technique, where the outputof multiple networks is then used to produce the final output.
16) BatchNormalization – As a concept, batch normalization can be considered as a dam wehave set as specific checkpoints in a river.
This is done to ensure thatdistribution of data is the same as the next layer hoped to get.
When we aretraining the neural network, the weights are changed after each step ofgradient descent. This changes the how the shape of data is sent to the nextlayer
But thenext layer was expecting the distribution similar to what it had previouslyseen. So we explicitly normalize the data before sending it to the next layer.
ConvolutionalNeural Networks
17)Filters – A filter in a CNN is like a weight matrix with which we multiply apart of the input image to generate a convoluted output.
Let’s assume we havean image of size 28*28. We randomly assign a filter of size 3*3, which is thenmultiplied with different 3*3 sections of the image to form what is known as aconvoluted output.
The filter size is generally smaller than the original imagesize. The filter values are updated like weight values during backpropagationfor cost minimization.
Considerthe below image. Here filter is a 3*3 matrix which is multiplied with each 3*3 section of the image to form theconvolved feature.
18) CNN(Convolutional neural network) – Convolutional neural networks are basicallyapplied on image data.
Suppose we have an input of size (28*28*3), If we use anormal neural network, there would be 2352(28*28*3) parameters. And as the sizeof the image increases the number of parameters becomes very large.
We“convolve” the images to reduce the number of parameters (as shown above infilter definition).
As we slide the filter over the width and height of theinput volume we will produce a 2-dimensional activation map that gives theoutput of that filter at every position.
We will stack these activation mapsalong the depth dimension and produce the output volume.
You cansee the below diagram for a clearer picture.
19)Pooling – It is common to periodically introduce pooling layers in between theconvolution layers. This is basically done to reduce a number of parameters andprevent over-fitting.
The most common type of pooling is a pooling layer offilter size(2,2) using the MAX operation. What it would do is, it would takethe maximum of each 4*4 matrix of the original image.
You canalso pool using other operations like Average pooling, but max pooling hasshown to work better in practice.
20)Padding – Padding refers to adding extra layer of zeros across the images sothat the output image has the same size as the input. This is known as samepadding.
After theapplication of filters the convolvedlayer in the case of same padding has the size equal to the actual image.
Validpadding refers to keeping the image as such an having all the pixels of theimage which are actual or “valid”.
In this case after the application offilters the size of the length and the width of the output keeps gettingreduced at each convolutional layer.
21) DataAugmentation – Data Augmentation refers to the addition of new data derivedfrom the given data, which might prove to be beneficial for prediction.
Forexample, it might be easier to view the cat in a dark image if you brighten it,or for instance, a 9 in the digit recognition might be slightly tilted orrotated.
In this case, rotation would solve the problem and increase theaccuracy of our model. By rotating or brightening we’re improving the qualityof our data. This is known as Data augmentation.
RecurrentNeural Network
22)Recurrent Neuron – A recurrent neuron is one in which the output of the neuronis sent back to it for t time stamps.
If you look at the diagram the output issent back as input t times. The unrolled neuron looks like t different neuronsconnected together. The basic advantage of this neuron is that it gives a moregeneralized output.
23)RNN(Recurrent Neural Network) – Recurrent neural networks are used especiallyfor sequential data where the previous output is used to predict the next one.
In this case the networks have loops within them. The loops within the hiddenneuron gives them the capability to store information about the previous wordsfor some time to be able to predict the output.
The output of the hidden layeris sent again to the hidden layer for t time stamps. The unfolded neuron lookslike the above diagram.
The output of the recurrent neuron goes to the nextlayer only after completing all the time stamps. The output sent is moregeneralized and the previous information is retained for a longer period.
The erroris then back propagated according to the unfolded network to update theweights. This is known as backpropagation through time(BPTT).
24)Vanishing Gradient Problem – Vanishing gradient problem arises in cases wherethe gradient of the activation function is very small. During back propagationwhen the weights are multiplied with these low gradients, they tend to becomevery small and “vanish” as they go further deep in the network. This makes theneural network to forget the long range dependency. This generally becomes aproblem in cases of recurrent neural networks where long term dependencies arevery important for the network to remember.
This canbe solved by using activation functions like ReLu which do not have smallgradients.
25)Exploding Gradient Problem – This is the exact opposite of the vanishinggradient problem, where the gradient of the activation function is too large.
During back propagation, it makes the weight of a particular node very highwith respect to the others rendering them insignificant. This can be easilysolved by clipping the gradient so that it doesn’t exceed a certain value.
End Notes
I hopeyou enjoyed going through the article. I have given a high level overview ofthe basic deep learning terms. I hope you now have a basic understanding ofthese terms.
I have tried to explain everything in a language as easy aspossible, however in case of any doubts/clarifications, please feel free todrop in your comments.
“转自:灯塔大数据;微信:DTbigdata”;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
数据分析交流群号:spss交流群:131233140 ;r与python交流群:275208364 ;游戏分析交流群:60974760; 人工智能群:257972325; 机器学习群:139482724;!
商务合作|约稿 请加qq:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。











