
我们为什么需要“千人同屏”?
在过去的两年,各式各样的虚拟场景层出不穷,有展厅展馆、有展览与音乐会、有景区古迹,但这些场景中多是寥寥数人穿梭其中,附加站在某个角落的NPC,这样的体验难免给人一种“单机游戏“的既视感,而千人同屏技术能够打破这样的既视感,是带给虚拟世界临场感的基石功能之一!

点击体验千人同屏
灵境大陆-体验入口
音乐空间-体验入口

-
观看虚拟演出和表演,能感受到不亚于现场音乐节的热闹氛围

(光遇欧若拉演唱会)
-
体验虚拟文旅活动,能和更多五湖四海的伙伴同游畅聊,更有现实生活的烟火气

(逆水寒汴京夜市)
-
对于线上峰会、发布会等会议,上千人会议现场更有“人声鼎沸”的热议氛围

-
对于线上社区,大家真实的互动、分享、交流将会直观视觉化激发用户的参与感


千人同屏并不是全新的技术,在数年前的游戏中早以可以实现。但是在虚拟空间中,没有游戏化的APP载体来充分释放性能,没有用户有等待游戏加载的耐心,并且在以网页为主要实现方式的当下,虚拟空间需要快速载入、兼顾性能,并可实现多端兼容(如不同app/浏览器/AR/VR设备...),宛如带着镣铐起舞。

虽有如此难度,但“千人同屏”仍被轻易地附加在各类概念化的描述之后,看似可以被轻易地实现。
这里想分享下我们理解的“千人同屏”:

用户可以在各式各样的虚拟人中无限制地选择自己喜欢的风格。在千人同屏技术的加持下,整个虚拟世界不再是整齐划一的虚拟人,而是像聚集了来自五湖四海的各色人儿,呈现千人千面、缤纷多彩的世界。


在真正的千人同屏里,用户不再是被限制在某个位置坐下或者站立(这样的千人万人同屏毫无意义),而是可以自由地操作自己的虚拟形象,去四处漫游,能做各种社交互动,在热闹的场域下充分感受真实的人与人之间交流,人与物之间的交流。


在虚拟空间中,能够认识新朋友遇见老朋友,是在虚拟世界中难忘的经历,如果此时看上去人山人海,实则只是程序操控下的机器人,那大可不必来到这里享受一个人的狂欢。

当然还有一些文字游戏类的说法,比如“实现千人同屏观看”这样以直接偷换了概念的方式硬套千人同屏技术,无不在说明千人同屏技术真实的难度。

为什么要实现“真·千人同屏”这么难?
在网页端要实现同屏千人流畅的实时互动,不同的环节都有巨大的挑战:后端对于用户位置信息的汇总处理、前后端通信细节的优化、前端渲染开销的控制......
下面具体分享下我们技术处理方案:

说到
渲染性能优化,降低 draw call 数往往是最先想到也最有效的做法
。一个 draw call 是 CPU 向 GPU 发送一次绘制命令,会产生两者间的一次通信开销。一旦 draw call 过多,这些开销积累起来,便导致渲染性能下降。

在以往的项目架构中,每一个角色人物作为一个单独的模型,渲染时都需要一次新的draw call,因此当在线人数大量增加时,draw call 数也就线性地猛增😱。
而实际上角色人物的种类并不多,只有三四个,因此大部分人物都是同一个模型的重复渲染,
如果可以把这些重复的模型同时渲染出来,自然就可以大大降低 draw call 了。
说到重复模型,对于3d渲染有所了解的话,自然就会想到
实例化绘制
(Instanced Drawing), 它可以
将同样的模型以实例化的方式合并成一次 draw call 绘制出来
,是 WebGL 提供的能力,正好可以解决我们的问题。

可事情并没有这么简单🥲。
我们的角色人物由用户操控,
会跑、会跳,实际上是带动作骨骼的蒙皮模型
(Skinned Mesh),这些动作互相独立并受人物当前活动状态控制。而
现有的移动端3d框架并不支持简单地将骨骼模型实例化
,如果只是简单将模型实例化的话,只会得到一堆无法表现任何动作的僵硬实例,在世界中平移。显然这是不可接受的🤯


(正常带动作的人物模型)
为了解决这个问题,可以有多种处理方案,其中
一种是
将动画烘焙到贴图材质
中,这样就可以
在 GPU 代码中通过采样的方式获取数据完成顶点变形
;
另一种是将动画的插值计算放在 CPU 上,再实时将当前动画数据上传至 GPU 处理
。
前一种的优点是性能更优,缺点是需要对动画的特殊处理,而且 GPU 编程限制更多也更复杂
;
后一种方案的优点是与现有的逻辑相适配,代码上也更简单,缺点是如果想要更加优化性能,还需要做其他特殊处理
。
这里,分享下比较简单的处理方案。
如果我们搞清楚现有框架是如何实现
非蒙皮模型的实例化
、以及
单个蒙皮模型的动作变形
,再将这两种能力组合起来,就可以实现带动作蒙皮模型的实例化啦!
😎

具体来说,
骨骼蒙皮模型能够渲染出动作动画,在于它的各个顶点已经绑定了对应哪几块骨头以及它们影响的权重。
当骨骼的位置、旋转、大小变化时(即动作进行中),渲染时便会逐帧去取到最新骨头的变换矩阵并将其作用到顶点位置上以改变原有的位置,这样就形成了动画。
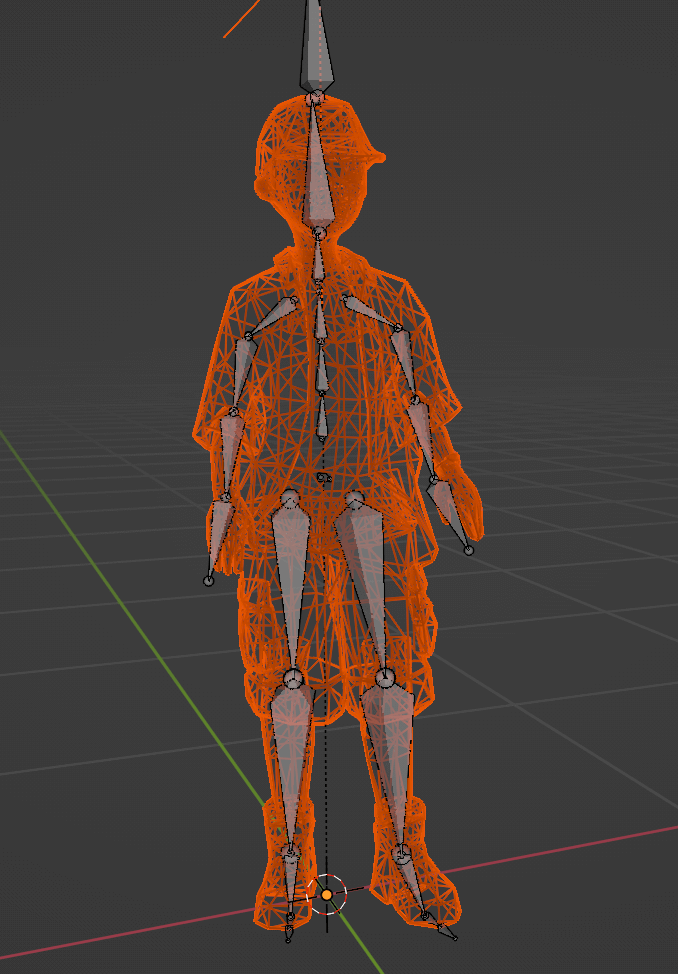
(控制模型动作的骨骼)
要把这些逻辑放入实例化绘制,也需要有同样的操作。
顶点与骨骼的绑定与单个模型是一致的,只需要复用即可,而
不同的地方主要在于之前只需要从一套骨骼中去取骨头的变换矩阵,而实例化后需要从多套骨骼中去取当前实例对应骨骼的变换矩阵。
因为每一个人物都有自己的动作状态,
因此可以
为每一个实例绑定一套骨骼,并由动画控制器去实现动作的计算
。
之后再将这些动作数据以数据贴图(data texture)的形式上传至 GPU,然后在顶点着色器(vertex shader)代码中读取使用即可。💪
当一个模型有20多块骨头时,每块骨头需要4个像素来存储共16个数字的变换矩阵,一套骨骼可用16*16像素的贴图且还有大量空余。即使
实例数量(人物)增加至1000个,贴图大小也不会超过512*512像素
!
🤩
在新的着色器代码中,我们取到新的骨骼变换矩阵便可完成顶点变形。
完成实例化后,当场景中有1000个角色时,draw call 数也不会像之前增加到1000,而仍然仅为1,在渲染层面大大优化了性能
!
🥳

虽然 draw call 已大为降低,
但1000个模型仍是1000个模型,顶点数和模型面数都不会减少,仍然是 GPU 计算中不小的开销 🤔
。
为了减小大量模型渲染时的面数,我们采用了多细节层级(LOD)的技术方案。
简单来说,
依据人物模型与相机的距离,可以选择不同细节层级的模型
。这是因为当角色距离较远,其精细细节本就难以分辨,这个时候再去渲染一个精细的模型也没有必要,完全可以
用一个更加粗糙的类似模型来替代
。
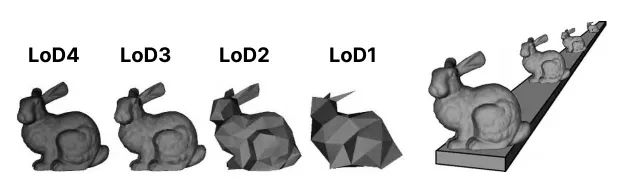
粗糙的模型顶点数可以减少很多,而且还可以有多个层级,以更细化区分距离,达到既减少面数、又在视觉上无差别的效果。
另外,
还可以在角色距离相机一定距离外完全隐藏模型,进一步优化性能
。
因为不同的层级对应不同的模型,所以在实例化绘制时,也需要引入新的实例化模型,同时增加几个 draw call。但这几个 draw call 仍然远小于此前每个实例单独一个 draw call 时的数量,收益远大于开销!🥳

虽然用实例化绘制在渲染能力上支持了1000人同时在线,但实际上在场景中不会始终都有1000人,而且因为采用了多细节层级,
每个角色也可能会在几个实例模型间切换,因此就会有实例显隐的问题 🤯
。
因为底层实现的限制,想要控制实例化模型中实例的显示还是隐藏,无法简单在各个实例上去控制,而
理论上最理想的方式是动态修改 count 属性值
。此时,实
例模型中只有前面 count 这么多个实例会进入渲染流程,而后面的实例因为不参与渲染,因此性能上最优。
我们在一开始也是这样处理的,将场景角色的变换矩阵设定给前n个实例,然后设定好实例化模型的数量,之后当角色退出场景或切换到其他模型时,只需要更新一个实例对应的索引序号、并减小 count 的值即可。这样就可以
保持始终只渲染实际有效的模型🤩
。









