
来源:
雷锋网
概要:
神经网络模块负责一个推理步骤,对于不同的推理任务,动态的组合这些模块,以生成针对不同问题的新网络结构。
深度神经网络虽然在图像,语音,机器人等方面取得了巨大的成功,但是这些成功通常局限在识别任务或者生成任务中,对于推理任务,常规的神经网络通常是无能为力的。伯克利AI实验室近期开通了博客,该博客的第一篇文章针对推理任务,提出了神经模块网络,通过训练多个神经网络模块完成推理任务,每个神经网络模块负责一个推理步骤,对于不同的推理任务,动态的组合这些模块,以生成针对不同问题的新网络结构。
该文章的作者为 Jacob Andreas ,他是伯克利 NLP 四年级博士生,也是 BAIR 实验室成员。他的个人主页上的介绍写着,“我希望能教计算机阅读”,研究方向包括机器学习模型与结构化神经网络方法。同时,他也是一个论文高产者,仅在今年就有多篇论文入选 ICML、ACL、CVPR 等主流国际顶级学术会议。
问题的引入
假设我们正在构建一个家用机器人,并且希望它能够回答有关周围环境的问题。我们可能会问他这些问题:

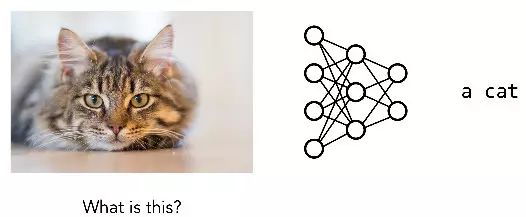
如何确保机器人可以正确地回答这些问题?深度学习的标准方法是收集大量的问题,图像和答案作为数据集,训练一个单一的神经网络,直接从问题和图像映射到答案。如果大多数问题看起来像左边的问题,目前我们已经有相似的图像识别问题的解决方案,这些单一的方法是非常有效的:
但是对于右面的问题,这种单一的神经网络就很难工作了:
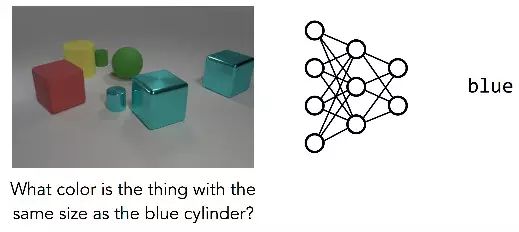
在这里训练好的单一网络已经放弃了,猜测给出了该图像中最普遍的颜色。是什么使得这个问题相比于上一个问题更难?即使图像更清晰简洁,该问题仍需要许多推理步骤:模型必须要首先找到蓝色的圆柱体,找到具有相同大小的另一对象,然后确定其颜色,而不是简单的识别图像中的主要对象。这是一个复杂的计算,同时计算的复杂性与所提出的问题密切相关。不同的问题需要不同的步骤来解决。
深度学习中的主流范式是“一刀切”的方法:对于任何需要解决的问题,设计一个固定的模型架构,希望能够捕获关于输入和输出之间的一切关系,并通过标定好的训练数据学习该模型的各种参数。
但现实世界的推理并不能以这种方式发挥作用:它涉及到各种不同的能力,不同的能力以新的方式结合以解决我们在现实世界中遇到的每一个新挑战。我们需要的是一个模型,它可以动态地确定如何对摆在它面前的问题进行推理——一个可以选择自己的结构的网络。伯克利AI实验室的研究者针对这一问题,提出了一类称为神经模块网络(Neural Module Network, NMN)的模型,它将这种更加灵活的解决方案融入到问题解决过程中,同时也保留了深度学习有效的特性。
如何解决
上面提到的推理问题涉及到三个不同的步骤:找到一个蓝色圆柱找到其他与之相同尺寸的物体,确定其颜色。根据推理过程可以绘制下图:

一个不同的问题可能涉及到不同的步骤,如果问题是“有多少东西与球有相同的大小?”可以会得到下面的推理步骤:

一些基础的操作,例如“比较大小”,在不同的问题中是共享的,但是它们可能会通过不同的方式使用。MNM的关键思路是明确这种共享:使用两个不同的网络结构来回答上面的两个问题,但是在涉及到相同基本操作的网络之间实现共享权重。
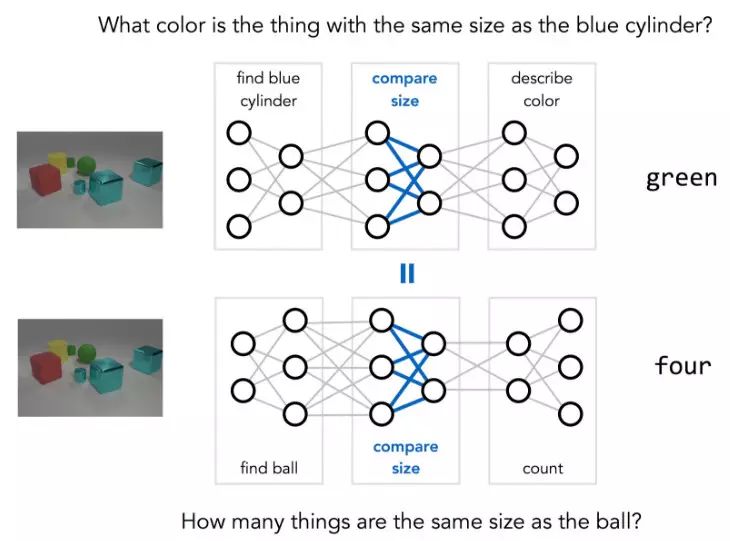
对于这样的新型网络结构,如何进行学习?实际上研究者同时训练了大量的不同的网络,在适当的时候将参数绑在一起,而不是通过许多输入/输出对训练单一的大型网络。
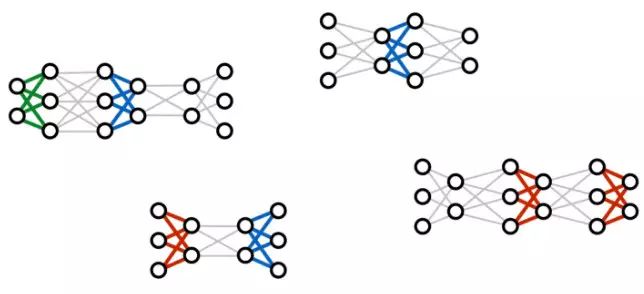
上图为几种常见的深度学习网络结构,包括DyNet 和TensorFlow Fold,通过动态地将它们结合在一起,即可以完成不同的推理任务。
在训练过程结束时所获得的并不是一个单一的深度网络,而是一个神经“模块”的集合,每个模块都实现了一个推理的步骤。当希望在一个新的问题实例上使用训练好的模型时,研究人员可以动态的组合这些模块,以生成针对该问题的新网络结构。
关于这个过程一个值得注意的事情是,训练过程中不需要为单个模块提供任何低级别的监督:模型从来没有看到蓝色对象或者“左侧”关系的孤立示例,模块只能在较大的组合结构中学习,只有(问题,答案)对作为监督,但训练程序能够自动推断结构部件与其负责的计算之间的正确关系:
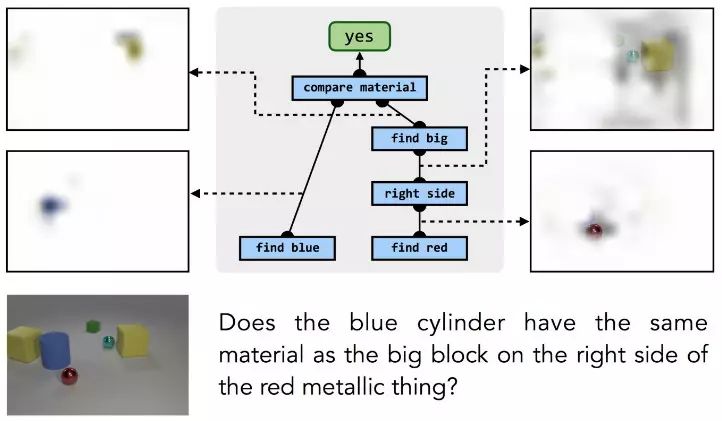
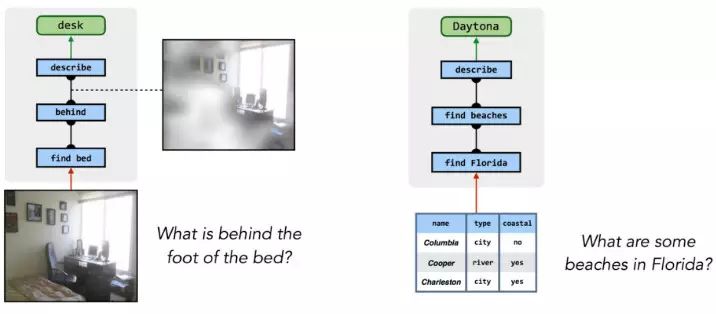
同样的过程也能回答关于现实图片的问题,甚至能够回答其他知识源的问题,例如数据库:
如何从问题得到推理蓝图
这整个过程的关键因素是收集如上所属的高级“推理蓝图”。这些蓝图告诉我们,每个问题的网络应如何布局,以及不同的问题如何互相关联。但是这些蓝图是从哪里来的?
在对参考文献1,2中的模型的初步研究中,研究者在设计特定问题的神经网络和分析语法结构之间找到了惊人的联系。语言学家长期以来一直认为,问题的语法与回答所需要的计算步骤的顺序密切相关。由于自然语言处理方面的最新进展,可以使用现成的语法分析工具来自动提供这些蓝图的近似版本。
但从语言结构到网络结构的准确映射仍然是一个具有挑战性的问题,转换过程中容易出错。在后来的工作中,研究者转向使用由人类专家制作的数据,它们用理想化的推理蓝图直接标注了一系列问题,而没有依靠语言分析。通过学习模仿这些人类专家,该模型能够大大提高预测的质量。最令人惊讶的是,当采用训练好的模型去模仿专家,但允许它自己修改这些专家的预测,它能够在不同的问题中找到比专家更好的解决方案。
总结
尽管近些年来深度学习方法取得了显著的成功,但许多问题仍然是一个挑战,例如few-shot learning和复杂推理。这些问题正是结构化经典方法所闪耀的地方,例如语义解析和程序归纳。神经模块网络结合了经典人工智能方法和深度学习方法两者的优点:离散组合的灵活性和数据高效性,同时结合了深度网络的表征力量。NMN已经在许多视觉和文本推理任务得到了成功。同时,研究者也在尽力将该方法应用到更多的AI任务中。
来源: 雷锋网
欢迎加入未来科技学院企业家群,共同提升企业科技竞争力
一日千里的科技进展,层出不穷的新概念,使企业家,投资人和社会大众面临巨大的科技发展压力,前沿科技现状和未来发展方向是什么?现代企业家如何应对新科学技术带来的产业升级挑战?
欢迎加入未来科技学院企业家群,
未来科技学院将通过举办企业家与科技专家研讨会,未来科技学习班,企业家与科技专家、投资人的聚会交流,企业科技问题专题研究会等多种形式,帮助现代企业通过前沿科技解决产业升级问题、开展新业务拓展,提高科技竞争力。
未来科技学院由人工智能学家在中国科学院虚拟经济与数据科学研究中心的支持下建立,成立以来,已经邀请国际和国内著名科学家、科技企业家300多人参与学院建设,并建立覆盖2万余人的专业社群;与近60家投资机构合作,建立了近200名投资人的投资社群。开展前沿科技讲座和研讨会20多期。
欢迎行业、产业和科技领域的企业家加入未来科技学院
报名加入请扫描下列二维码,
点击本文左下角“阅读原文”报名






