本文根据叶杰平教授在中国人工智能学会AIDL第二期,人工智能前沿讲习班-机器学习前沿所作报告《大规模稀疏和低秩学习》编辑整理而来,在未改变原意的基础上,略有删减。不足之处,望指正。

大家下午好,非常高兴,能够和大家一起,分享低秩和稀疏两种方法,主要会讲解一些在large-scale方面的应用,也会稍微提一下滴滴的一些应用,大部分我讲的很多应用,都会用用在特征约减,与很多问题如滴滴,都会有很多样本,每天都有上千万的大规模数据量不同,很多问题有成千上百万维度的特征,如何对特征进行稀疏和低秩约束,是我们今天要讲的主要内容,今天的报告主要针对模型介绍,具体应用可以下面查阅文献,不会具体讲解。
本次报告主要对一些基础的稀疏模型,以及结构的稀疏模型进行讲解,并会简单介绍低秩的模型,以及一些优化加速算法,最后会给大家讲一下large-scale,以及如何将这些算法用在大规模的数据上。
大家可能都对稀疏的含义比较了解,这里的稀疏,可能表示模型特征的稀疏,也可能表示数据的稀疏,数据稀疏主要是指文件的keyword比较稀疏,这里我们主要是指模型特征的稀疏,比如说一维的线性回归或者矩阵,这里的稀疏就是指模型的特征会比较少。
我们引入一个正则的概念,通过一个简单的线性拟合,建立一条线来拟合样本点,假设有一个M阶的多项式来进行拟合,那么有M+1个参数需要估计,我们希望利用这个方式来进行预测优化,找到一个系数使得误差最小。对于每一点我们有一个预测值y,一个ground truth,通过优化M+1个变量,使得y与ground truth之间差异最小。当M为0的时候我们可以知道这是一条直线,当M等于3的时候就变成了一条曲线,等等。
通过实验结果。我们可以看到训练误差在M很大的时候很小,而测试误差很大,这也就是非常常见的过拟合的问题,M太小的时候,模型太简单,训练误差和测试误差都很大,这也就是欠拟合的问题,M取中间值时才会非常合适,这过拟合和欠拟合也是两个非常常见的机器学习问题。我们对这些系数进行分析,可以看到在,当M等于9的时候,系数非常大,也可以发现,如果overfit的情况,如果稍微抖动的话,会对系数有非常大的影响,自然而然的,我们需要对我们的模型加一个正则项,从而通过控制系数的大小,向可以接受的误差逼近,通过数据拟合项的范式约束,使得模型的误差变小,模型能够更加的拟合数据,再加上一个控制系数的正则项,使得模型的参数更加稳定。超参数λ用来控制稀疏的程度,当超参数λ等于0时,模型也就退化成了一般的线性回归,λ一般需要通过调节参数学习出来,通过实验可以发现,λ比较小的话模型就会容易过拟合,λ比较合适的话模型就会比较稳定。
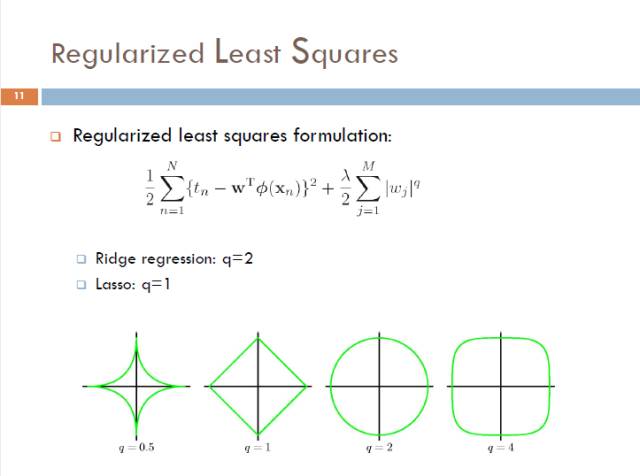
通常,我们利用正则项来控制参数W的大小,这里可以用q norm作为正则项,来保证W比较小,当q=2的时候能够保证W有一个光滑的解析解,q=1时,正则项是一个凸函数,且能够使得W稀疏;q在大于等于1 的时候,该模型仍然是一个凸函数,好处就是能够保证找到最优解,q小于1时,模型就变得非凸了,但是能够找到一个稀疏解。

自然地,我们就要思考为什么L1范式能够得到一个稀疏解,这里我们给出一个简单的例子,前面时loss函数,后面是正则项,可以看到一范式为凸但不可微,会在x=0时取到极值点,二范数在零点可微,但是不一定在零点取得极值点,另外一种对于一范数稀疏的解释是通过等高线的方式,可以发现一范数的约束能够使得loss函数在零点相交,而二范数是一个球,不一定与loss函数在零点相交,从而一范数能够使得解稀疏。
一范数最经典的就是96年的LASSO问题,我们有数据矩阵A,每一行代表样本,列代表特征,有标签y,可以代表分类和回归问题,我们这里用一个简单的线性模型取取预测y,呢么Ax-y就是一个拟合项,一范数就是正则项,使得x的系数稀疏,从而去掉一些无关项,如对疾病不相关的基因,从而增强了模型的可解释性,自动做了特征选择,有效的避免过拟合,这样子,稀疏可以同时选择特征,并且建立了模型。下面我们会讲一些结构性的计算,这个模型能够同时作特征选择和进行回归或分类。这里我们举一个在MRI上面的应用。利用简单的logit回归,加上一个稀疏先验,利用MRI图像进行病人和正常人的分类,并且同时实现了探寻哪一些脑区信号与疾病的相关与否,找到了与疾病相关的一些特征,之前提到的y都是比较简单的,只有一列,但是很多场景下,y可能有很多值,我们特征可能时很多的特征,y可能是1维的比如说有病无病,也可能多维的比如说每个脑区的一些判别,这样不仅每个点都是多维的,label也可能是有很多维,这样就是一个两边都是多维的big data问题,模型也从从一个一列,变成了一个矩阵,扩展了一个平方的关系。如果不增加正则项,这种问题将会非常难以解决。假设有一千个数据,x和y都是一百万维,这个模型就会是一个非常大的矩阵,如果没有正则项,这个模型将几乎无法求解。需要加入很多的假设,如低秩假设,这个模型也就可以对数据矩阵进行分解,也就使得我们的维度降低,最后在假设稀疏,进一步降低了系数的维度,现在的数据量都比较低,特征特别大,我的一个合作者进行了一个比较大的项目,把所有的数据整合在一起,有两三万个数据,但仍然不算很多,未来的数据如果越来越大的话,模型会越来约精确,现有数据不足,所以只能对模型加入很多假设,从而保证模型的有效性,当然,数据还是第一重要的。
系数学习在很多领域中都有很广泛的应用,如生物医学,图像处理,neuroscience,机器学习等等,我们最终的目的是找到一个超参数,一个常用的方法是使用交叉检验,在一个广泛的超参数空间中,选择一个最优的超参数,这种方法可能会存在一种缺陷,一个更好的方法是使用stability selection. 相当于对每个数据进行子采样,然后进行多次筛选,选择最好的参数,具体的可以在文章中查阅,里面有很强的理论证明。它会对问题进行很多子采样,所以会进行很多次的lasso求解,因此需要一个特别快的算法,这也是我们今天主要要讲得,如何在大规模的数据上进行计算。
刚刚对基础进行了讲解,下面我们对几个模型进行讲解,刚刚提到过LASSO可以同时解决提取参数和预测两个任务,并且具有是的提取的特征具有理论可解释性,同时非常容易推广。我们知道,很多特征是有结构的,特征与特征之间并不是独立的,特征之间是可以分组,我们首先介绍一些结构LASSO,这里给出一个例子,特征之间会有光滑性,我们给出了一个所有脑区的特征,我们可以发现向邻近的点会比较类似,特征的光滑性有时间和空间上的光滑性,比如说,相邻时刻之间的数据以及相邻空间的数据是具有相似性的,所以很多问题都是有光滑性的,也会有一些问题具有一些树的结构,以及一些问题可能具有一些网的结构,得到特征值之间的相似性。当我们获得我们的这些特征之间的先验知识之后,如果对lasso进行推广,利用我们的特征之间的信息,结构的lasso也就应运而生。和lasso类似,损失函数可以根据问题相关设计,如logit回归或者最小二乘回归等等,来表示对数据的拟合程度,重点是如何设计我们的penalty,lasso是L1-norm,仅仅是稀疏,特征之间没有任何假设,但是如果我们有特征直接结构的先验知识,那么我们可以在正则项这里进行推广,一般是利用一个凸的方法,来得到我们需要的结构,这里我们根据结构的先验信息,有Fused LASSO(光滑性),Graph LASSO(图结构), Group LASSO(组结构)以及树结构LASSO(树结构)。
原文链接:
http://mp.weixin.qq.com/s/dK7Y1bFfTs1PX3xJYDw4iw






