编译丨Linsa
原作丨John King & Roger Magoulas
概要
在第四版O’Reilly数据科学薪资调查中,我们研究了983名在数据科学领域的工作者,他们来自45个国家和美国45个州的不同行业。通过本次调查的64个问题,我们研究了数据科学家,分析员和工程师所使用的工具,工作内容,以及薪资水平。
主要发现包括:
-
Python和Spark成为了对薪酬贡献最高的两大工具
-
在编程从业者当中,编程时长越久薪资越高
-
SQL,Excel,R和Python是最常用的工具
-
会议参加越多的人,薪资越高
-
在相同的工作量下,女性薪资低于男性
-
各个国家和美国各州的GDP已经成为了预测不同地域薪资的标杆,但这不是最直接的预测指标,而是该模型的额外数据补充
-
在选择和使用工具方面,发现有两组最明显的差异,第一是以Excel,SQL和少量闭源工具为主的职员,另外是使用更多开源工具并投入更多时间编码的职员
-
R是个“跨界”语言,即使不怎么编程或使用开源工具的人也会使用R
-
编程工作者中又区分为两种,第一是主要使用Python的年轻数据科学家/分析师,第二是经验丰富的高级数据科学家/工程师,他们使用的工具更多而且薪资更高
可以参考一下在附录B完整的模型,可以依据个人情况去评估自己的工资(注意别忘了平方最后的结果)
简介
这四年中,我们在O’Reilly Media上收集到数据科学家,工程师及其他数据业内人士的相关信息,包括他们的核心技能,所使用的工具和薪资水平。我们发现很多的关键变量,例如工资中位数、核心技能以及工具间使用的相关性基本没有变化。在本年度分析中,我们收集了从2015年9月到2016年6月的983份数据业内人士的调查问卷。
该报告中,我们采用了不同方法对数据结果进行分析,包括着重对受访者和工具使用进行了分类。为了提高结论的准确度,我们优化了线性模型,在经济的地理变异上应用了平方根变化以及公开信息资源。同时,该研究提出了一些涉及到工作内容和薪资变化的新问题。
薪资
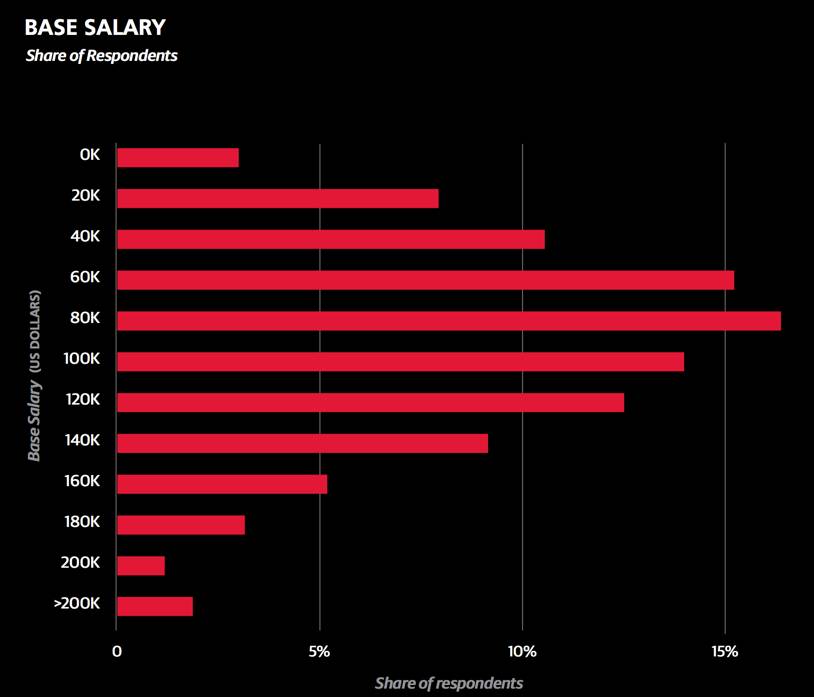
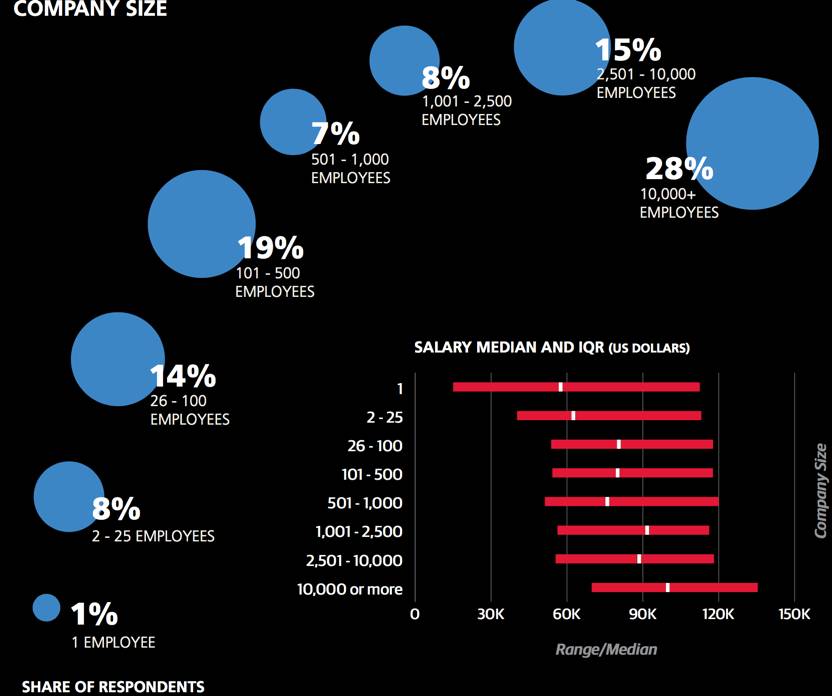
该调查中,研究对象的基本工资中位数是8.7万美元,比去年的9.1万美元低了不少,但这是由于样本中基本统计变量差异导致的。今年样本有了更多非美国的受访者和30岁及以下的年轻人。有五分之三的样本来自美国,他们的薪资中位数为10.6万美元。
什么是四分位距(IQR)
通过一系列问题,我们都会做出相应的图表和统计出受访者的工资中位数。虽然中位数可以用来比较来自不同组的工资,但却无法显示样本的薪资范围与区间变化,因此IQR也被划分在这次研究范围内。IQR包括了样本中间的50%薪资区间,但该范围不是置信区间,也不是以标准偏差为基础的。
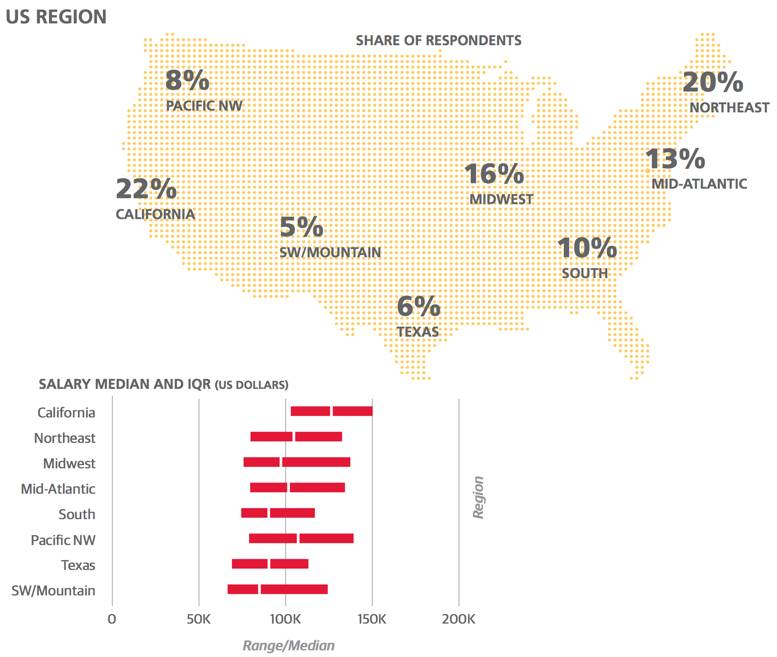
举例来说,美国受访者的IQR是8万到13.8万美元之间,这代表四分之一的美国受访者工资是低于8万的,而有四分之一受访者的工资是高于13.8万美元。在美国东北和中西地区的对比中可以明显发现,东北区相对有更高的工资中位数(10.5万vs 9.8万)。但是东北地区薪资的第三分位数是13.3万美元,而中西地区为18.8万美元,这表示中西地区的薪资变化差距更大,而且在最高收入人群中,中西地区的薪资甚至是高于东北地区的。
薪资变化因素
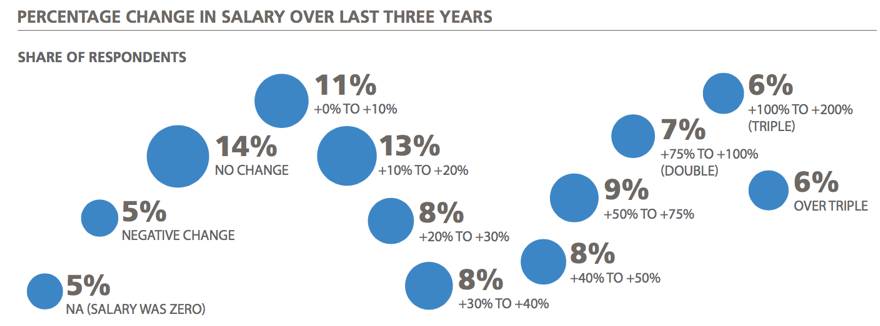
我们收集了过去三年里薪资变化的数据。
根据数据显示,接近一半受访者表示薪资有20%的变化,而有12%的受访者表示工资增加了一倍。
我们尝试建立薪资变化和其他变量的模型,但R方只有0.221,所以这个模型并没有很大的建设性。在薪资回归模型上我们发现了影响薪资变化的因素,例如使用Spark/Unix系统,长时间的会议,长时间的编程和原始模型的建立,上述这些因素对薪资预测有正面影响。然而使用Excel,性别上的差异,在落伍公司工作则对薪资预测起到负面影响。同时,地理差异也相对影响着薪资变化,因为在一个经济更发达的地方,工资不太可能止步不前。
评估你的薪水
你可以利用模型去预估自己的薪水,在附录B就能参见完整的模型,记得加上适用自己的系数,然后算出所得结果的平方就是你最后预估的薪资(注意系数不是以美元为单位的)。某一特定系数对最终薪酬估算的影响也会依赖于其他系数,而且薪资越高,每个系数的影响就越大。举例来说,对初级数据科学家和高级架构师来说,他们在高收入国家薪资差异明显比较低收入国家的要大。
影响薪酬的因素:回归模型
在今年报告中,把我们2015年报告中原来的基本线性模型做了两处调整,包括:1)外部地理数据(美国各州和全国GDP)2)平方根变换。该模型需要把薪资影响因素的系数加起来,再把结果平方得出最后的预估薪资。而这两处的调整都有效提高了薪资预估的准确性。
该模型解释了薪资样本有四分之三的方差(R平方为0.747),大致有一半的方差是跟地理位置和工作经验有关。还有一些重要因素无法通过调查中得出,例如,我们不能评估出受访者的工作质量,因此部分方差无法得到合理解释也是很正常的。
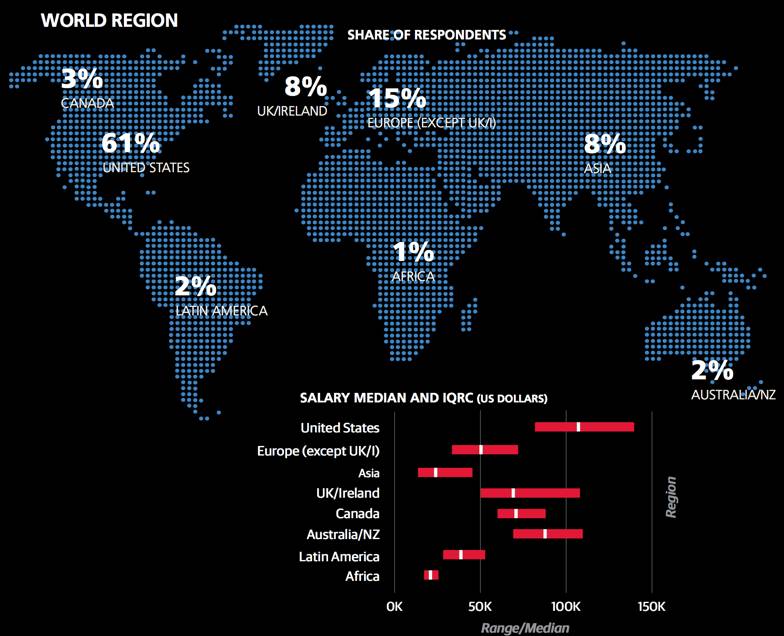
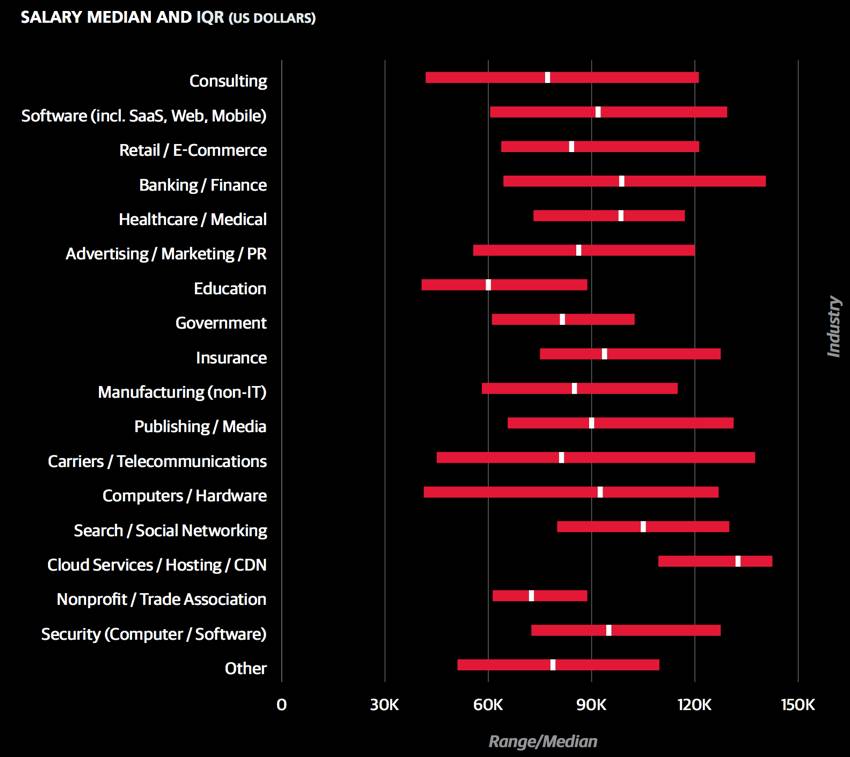
地理因素影响
地理因素对薪资变化有着明显的影响,但由于样本数受限,该因素不能精确地从样本中体现出来。例如,如果一个国家的受访对象只有一到两个,就不能充分判断出该国的系数。因此,我们扩张到一个更大的范围,例如以亚洲,东欧作为系数,但在这些区域内的各个国家,他们之间也有一些经济差异,所以这也使模型的准确性也受到了一定影响。
为解决上述问题,我们采用了各个国家和美国各州公开的人均GDP。然而GDP本身不能直接转换为薪资,但却可以成为薪资差异的地域性标杆。在这里,我们使用的人均GDP是以国家和各州为单位的,因此该模型对于更小的地理单位会预估得不够到位。
在GDP纳入模型之前,我们在两处做了调整。其一,华盛顿特区人均GDP是18.1万美元,远高于邻州维吉尼亚州的5.7万美元和马里兰州的6万美元。许多维吉尼亚州和马里兰州的数据科学岗位都位于华盛顿州都会区内,但从调查数据中显示,在这三个地区数据科学家的平均薪资没有明显差异。所以用18.1万美元去代表华盛顿特区会高估他们薪资水平,所以华盛顿特区GDP就被调整为马里兰州的6万美元。
另一处对加利福尼亚州进行了调整。因为在所有薪资调查中发现,即使加利福尼亚州6.2万美元的人均GDP排名并不是很高,至少低于九个州以及瑞士,挪威两个国家,但工资中位数在美国各州和各个国家中是最高的。我们发现这种异常现象是由于旧金山湾区8到9万美元人均GDP所导致的。作为一个主要的科技中心,湾区在某种程度上拉高了加州的人均GDP,因此我们将加州的数据调整到7万美元。
性别因素
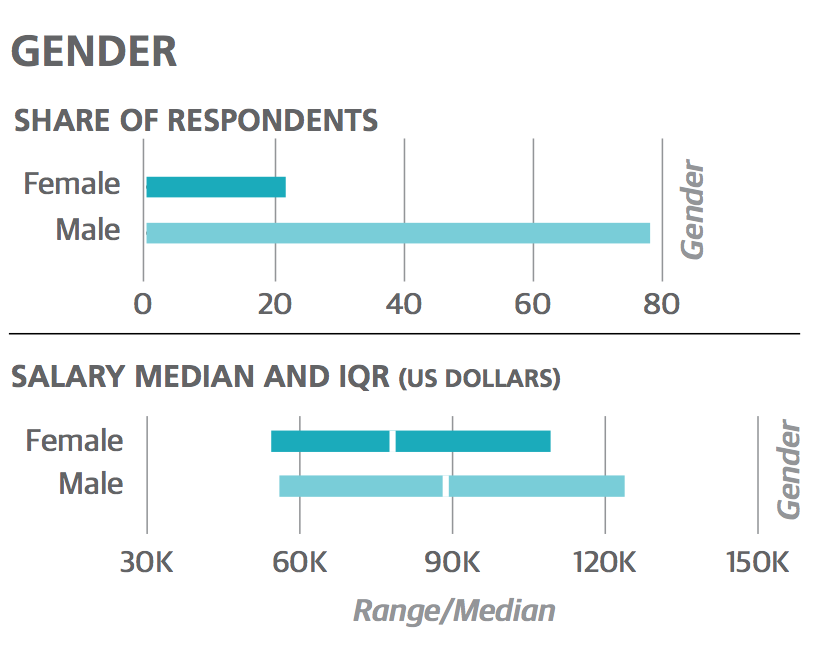
据调查显示,男性和女性的薪资中位数有1万美元的差距。在所有变量保持一致的情况下,例如一样的职能和技能,女性薪资往往比男性要低。
年龄,经验和行业因素
研究表明,经验和年龄是影响工资的两大因素。
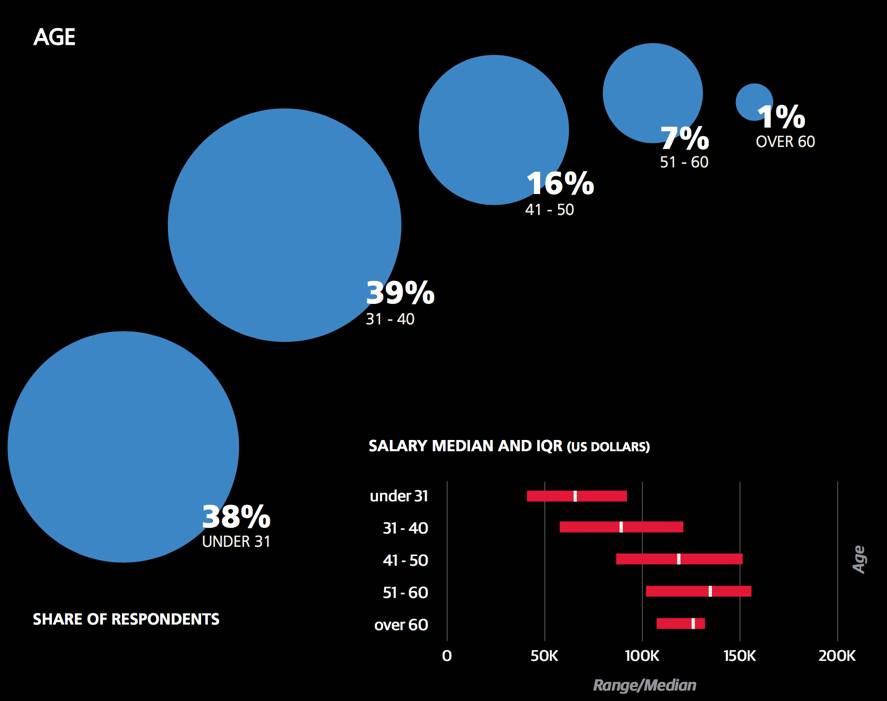
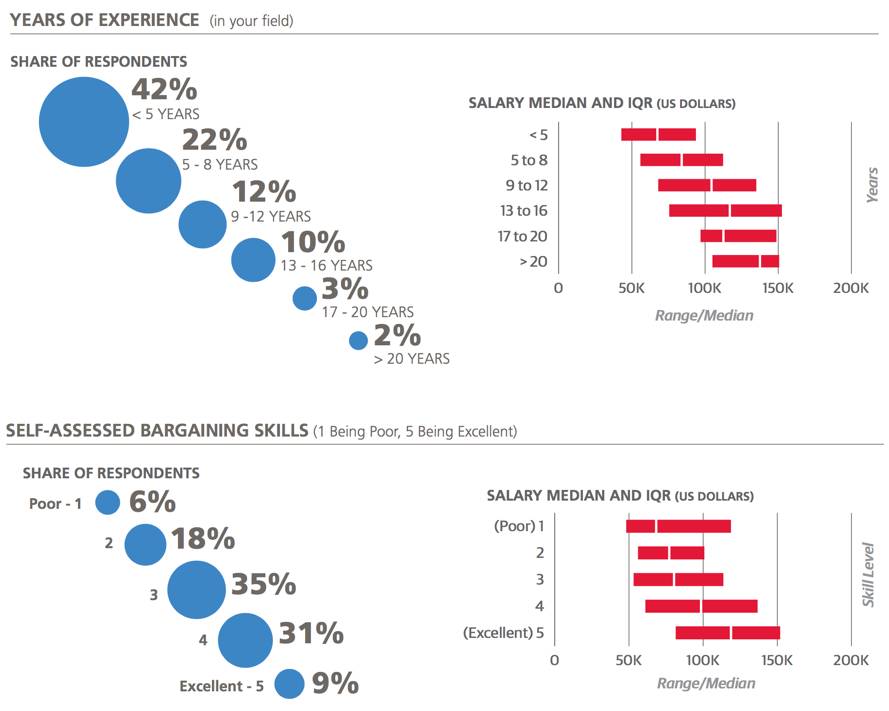
以年为单位来计算经验系数(+3.8)来说,每多一年经验,薪资就会平均涨2到2.5千美元。从年龄方面来看,最大的差异是20岁初到20岁末之间,其次是31至65岁和65岁以上的差距。同时我们也让受访者用1到5分去评估他们的谈判技巧,那些自我评估较高的人倾向有更高的薪资。在同一行业内和拥有相同技能的前提下,给自己打5分的数据科学家比打1分的工资多出1到1.5万美元。
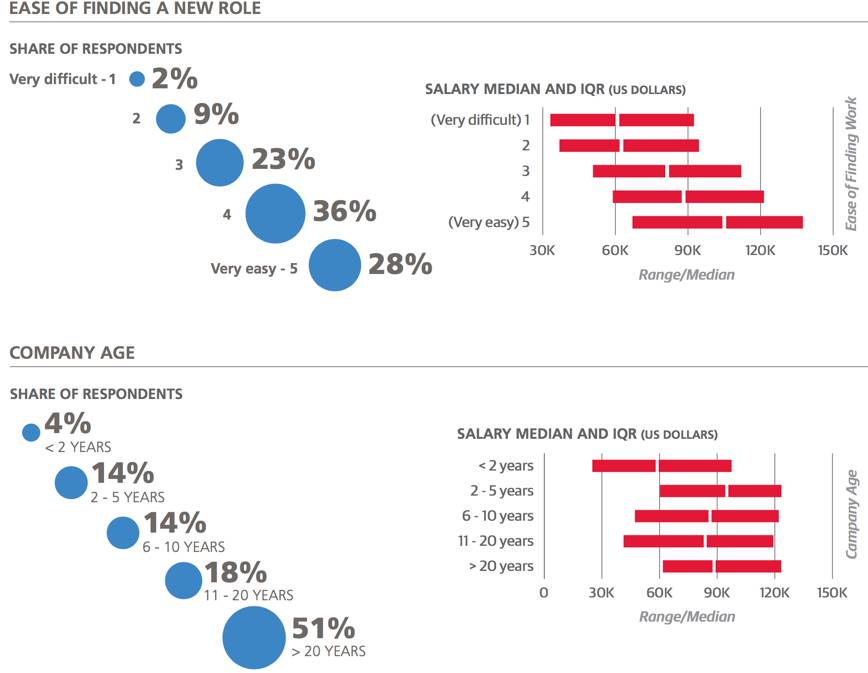
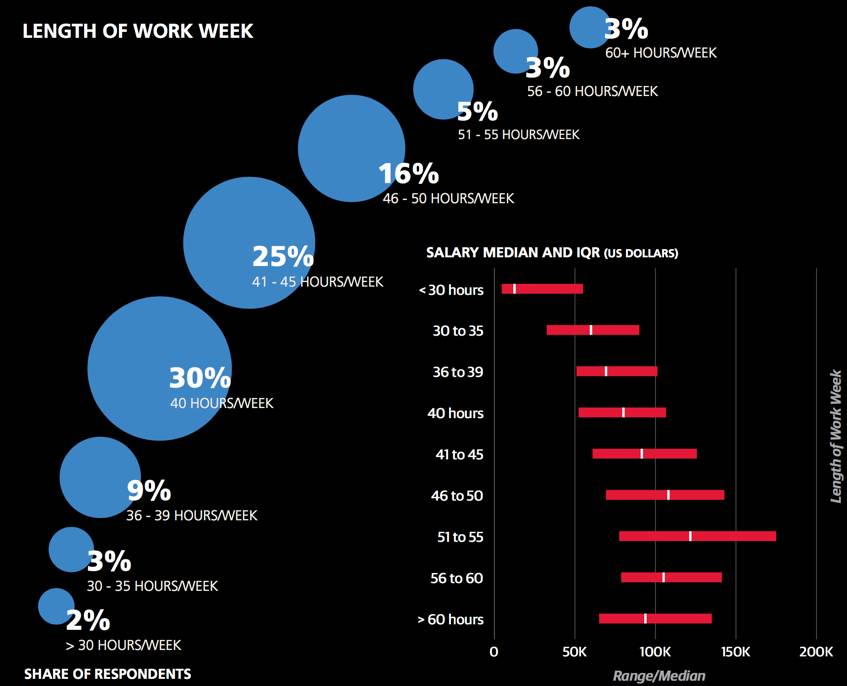
最后,考虑到工作与生活之间的平衡,数据显示当工作超过60个小时,薪资就会呈下滑趋势。
如何分配时间:
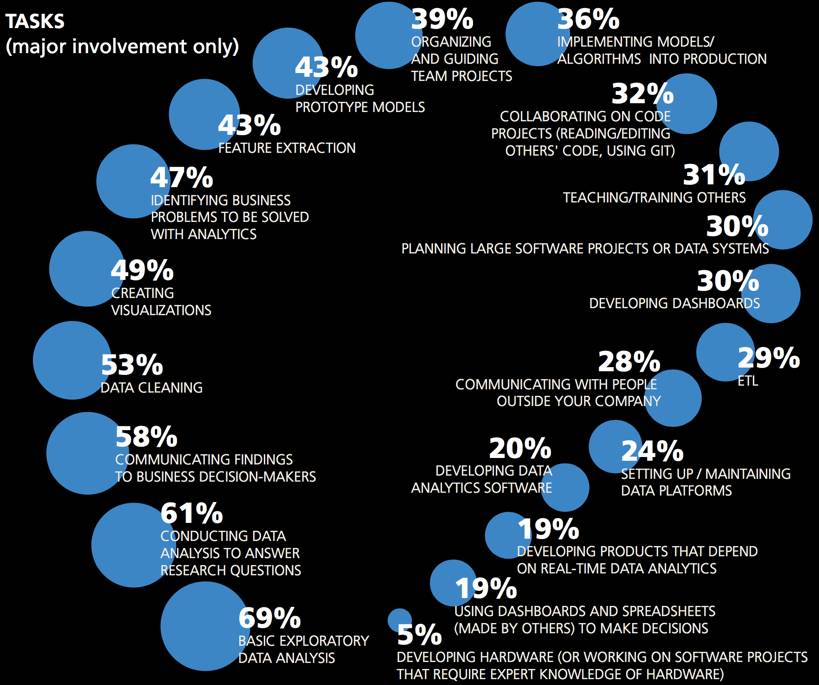
任务的重要性
我们通过四个不同类型问题去了解受访者的工作内容:
对于每项任务,受访者可以选择以下三个级别:不参与,少量参与,主要参与。
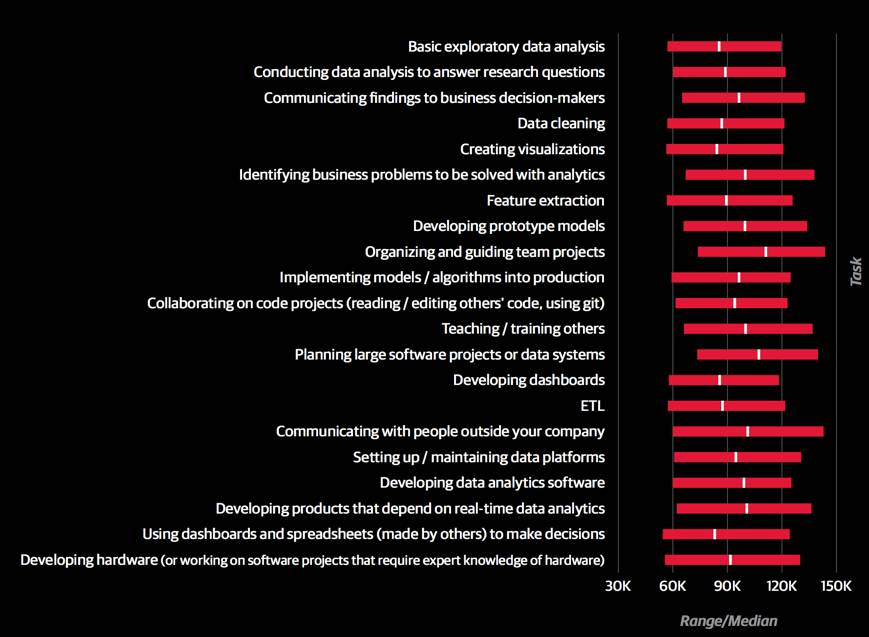
对工资影响最大(系数最大)的工作内容是原始模型研发。该模型中,主要参与研发的受访者薪资平均增加了7.4千美元。甚至少量参与的也有+4.4的系数。
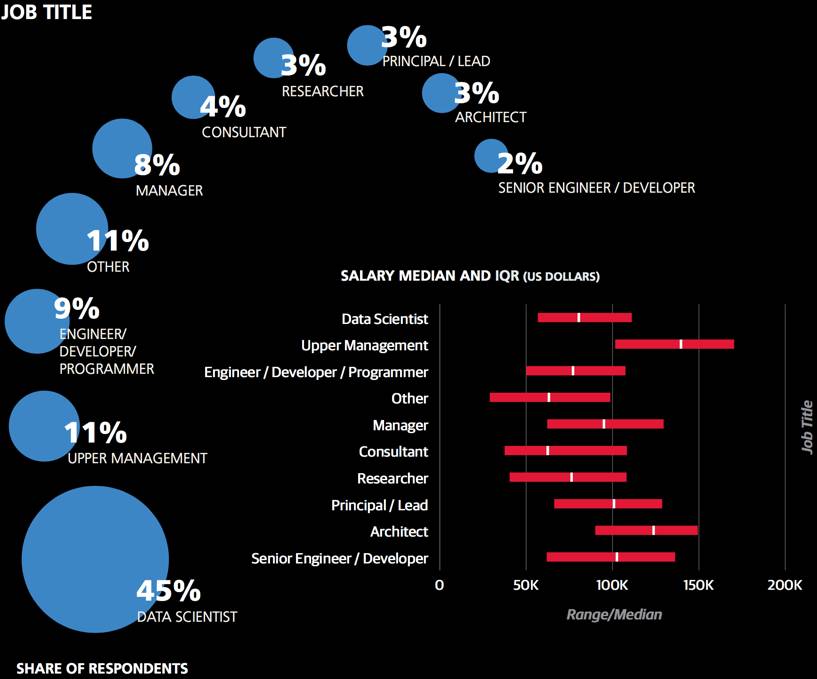
职称的相关性
相比于具体工作内容,职称也许是个更好的工资预测因素,尽管职称本身也无法准确体现出工作内容。例如,在软件架构师中,只有70%的人主要参与了大型软件项目,所以职称并不代表具体工作内容。虽然这存在一定的差异,还是可以利用职称来预测薪资,因为“架构师”可能也是一种资历的象征。在这个模型中,“高层管理人员”的系数为+20.2,特别是在规模较小的公司高管,或是董事和副总裁。“中层管理人员”系数为+9.7,“商业问题分析并解决”的系数为+1.5/+ 6.7,和“公司外部谈判”的系数为+5.4。
会议所用的时间
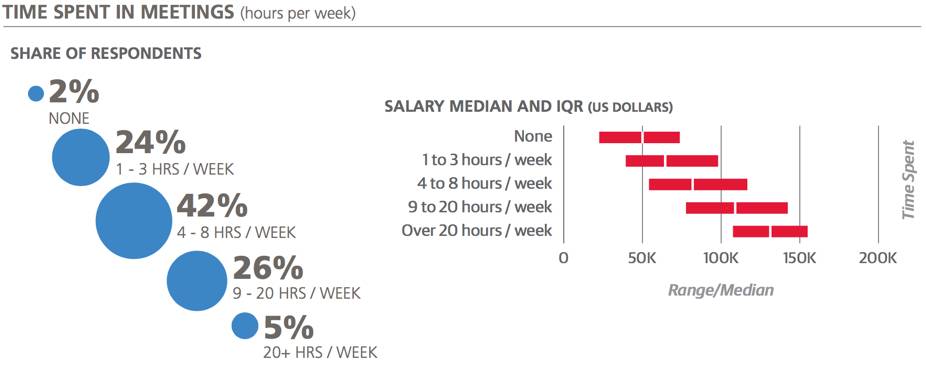
据数据显示,在会议中花时间越多的人一般薪资越高。当然这没有必然的因果关系,而且在所有因素保持不变的情况下(比如工作内容,工具的使用,等),开始积极参加会议似乎也无法给薪资带来增涨。(当然,我们现阶段还未对此进行验证)
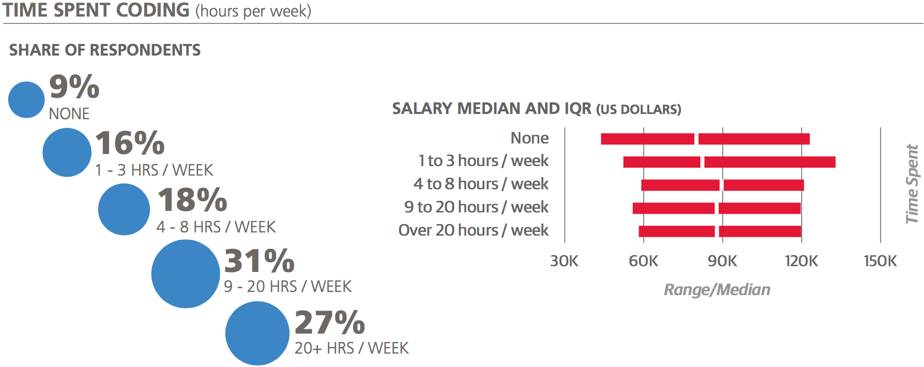
编程的工作角色
每星期花4-8个小时来编程的人工资中位数最高,而完全不编程的人工资中位数最低。
在本次样本中只有8%的人完全不编程,和去年的20%比有了明显的下降,这说明了编程是数据科学工作者的大势所趋。
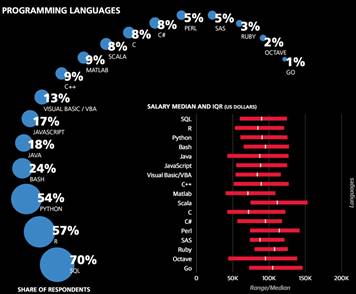
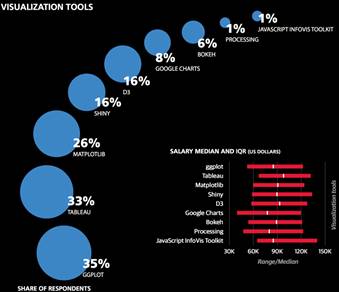
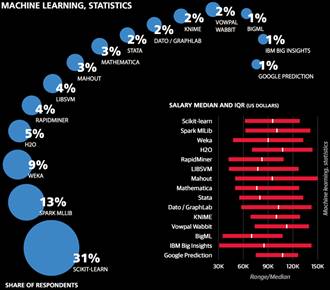
不同工具选择带来的影响
数据显示,样本中最常用的工具为Excel(69%)、SQL(69%)、R(57%)和 Python(54%)。与去年相比,Excel和R的使用率分别获得了10%和5%的提升,SQL及Python仅比去年有小幅度提升。
超过90% 的受访者表示工作中有一部分时间是编程,且80%的人表示用过至少Python, R, 和Java其中一种,但只有8%的受访者表示三者都用过。该模型中,把除操作系统以外最常用的工具作为单独系数,其中Python, JavaScript, 和Excel 的系数比较显著,分别为+4.6,-2.2和-7.4。我们将比较不常用的工具归类,其中对薪资影响最大的5类集群,他们的系数可以根据每类中掌握的工具数量进行累加。(集群内系数的累加是有规定个数上限的,因为仅有小部分受访者累加超过该个数,而且即使超过也不代表会影响薪资水平。)拥有最高系数的集群是以Spark和Unix为核心,其中每项工具均有+3.9系数。Spark使用率从去年的3%提高到了20%,而且样本显示高薪的受访者中使用Spark的更多。第二大集群包括了Tableau, Teradata, Netezza, Microstrategy, Aster Data, 和Jaspersoft,其系数均为+2.4。在去年的报告中,Tableau也有一个较大的正系数。另外三个较大的集群主要是由开源数据挖掘工具构成的。
数据分析工具选择的顺序
虽然这个模型可以基于使用工具的数量而估算出一个人的薪资水平,但这并不能推断出到底哪个工具是你一下个学习的目标。其实问题的关键在于该工具是否有助于完成你日常的工作。如果你不需要分析比电脑本地内存还大的数据量,那么即使用分布性系统的工具也无法提高你的薪资。
在以下工具排列中,学会第一个工具的人往往会把第二个设为下一个学习目标,而且这每一环节都存在着较大的薪酬差距。所以如果你已经学会序列中的第一个工具,不妨可以考虑学习第二个,以此类推。


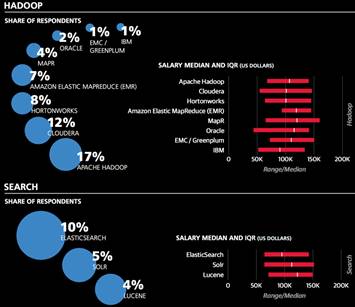
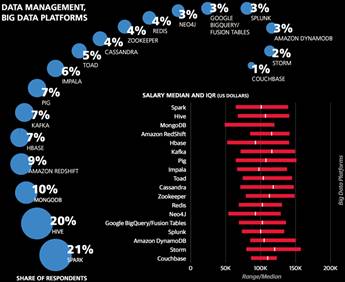
工具与工作之间的关系:受访者的分类
对于数据业内人士并不能一概而论,尽管根据职称区分是很常见,但根据工具及工作内容加以区分会更为稳妥。基于每个受访者的工具使用和工作内容,他们都会被归在以下四类中的其中之一。 这四类群体在样本中人数比例依次为29%,31%,23%和17%。下面分别描述了这四类群体。
种类1:使用少量工具的分析师和数据科学家,里面也包括了一些程序开发员。
种类2:会使用较多微软工具的分析师和工程师
种类3:以使用Python为主的编程分析师和数据科学家
种类4:以使用开源集群工具为主的数据工程师和架构师
接下来的报告会描述工具使用的比例,完整数据请参见附录A。
操作系统
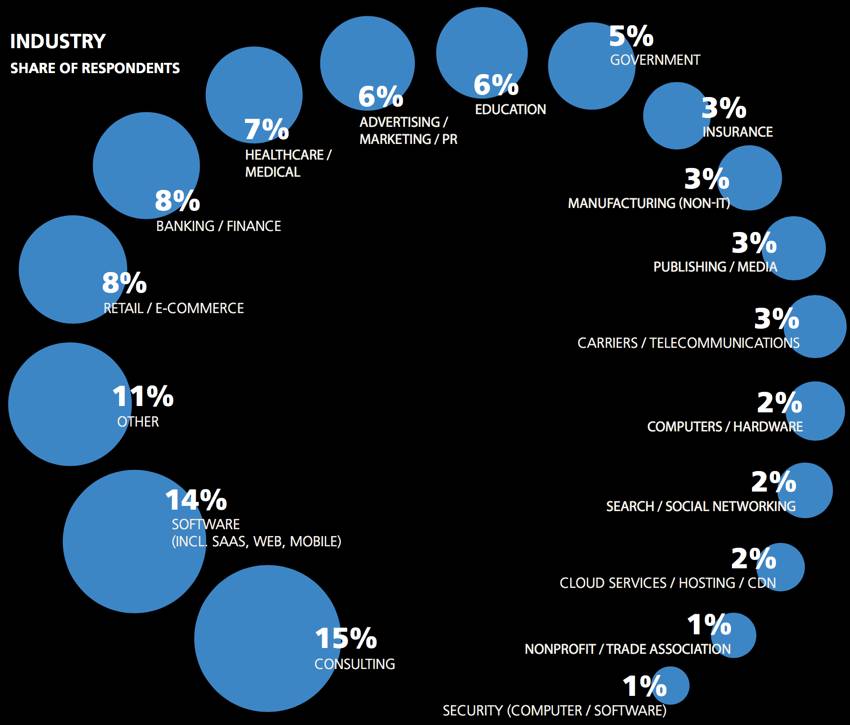
在之前三篇数据科学薪资调查报告中,有两个比较明显差异的工具组,分别是开源工具(较少GUI类工具)和专有软件/微软大型开发软件。在开源集群的工具中,最常用的工具包括Linux,Python,Spark,Hadoop和Java。而在闭源集群的工具中,常用工具包括Windows, Excel, Visual Basic和MS SQL Server。同样这种明显的区分也出现在受访者的分类中,下表的操作系统的分类也能说明这一点。
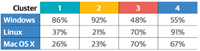
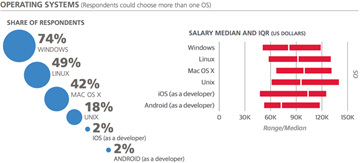
通过下表中一系列任务体现出了1/2组及3/4组之间的区别,下表是主要参与到任务的受访者比例。
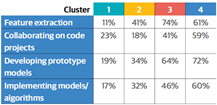
对于以上任务,3/4组数据比1/2组要高。
Python,Matplotlib,Scikit-Learn










