
原文来源:arXiv
作者:El Mahdi El Mhamdi、Rachid Guerraoui、Sébastien Rouault(瑞士洛桑联邦技术研究所)
「机器人圈」编译:嗯~阿童木呀、多啦A亮
 导语:2016年8月3日,IBM官方宣布了首个人造神经元,可用于制造高密度、低功耗的认知学习芯片。IBM瑞士苏黎世研究中心制成了世界上第一个人造纳米尺度随机相变神经元。同时,谷歌也在瑞士成立了美国本土之外最大的工程师办公中心,专注于机器学习。可以说,瑞士已经成为欧洲在机器学习领域最重要的阵地之一。近日,来自EPFL(瑞士洛桑联邦技术研究所)的三名研究员就针对神经网络、神经元芯片,以及其鲁棒性展开了论证和研究。我们一起来看看。
导语:2016年8月3日,IBM官方宣布了首个人造神经元,可用于制造高密度、低功耗的认知学习芯片。IBM瑞士苏黎世研究中心制成了世界上第一个人造纳米尺度随机相变神经元。同时,谷歌也在瑞士成立了美国本土之外最大的工程师办公中心,专注于机器学习。可以说,瑞士已经成为欧洲在机器学习领域最重要的阵地之一。近日,来自EPFL(瑞士洛桑联邦技术研究所)的三名研究员就针对神经网络、神经元芯片,以及其鲁棒性展开了论证和研究。我们一起来看看。

现如今,随着基于神经网络的机器学习的迅速发展及其在关键任务应用中的广泛使用,关于神经网络黑箱方面的质疑越来越多,这主要是因为了解其局限和功能变得至关重要。随着神经元硬件的兴起,了解神经网络作为分布式系统是如何容忍其在计算节点、神经元及其通信通道和突触的故障变得更为关键。在实验中,我们对神经网络的鲁棒性进行的评估,在所有可能的输入中,对所有可能的故障进行测试的不切实际性,这最终会在第一个的组合爆炸中产生;以及在第二步中收集所有可能输入的不可能性。
在本文中,当神经元的一个子集崩溃时,我们证明出了输出的预期误差的上限。这个上限涉及对网络参数的依赖性,在平均情况下可以将其看作是太过悲观。它涉及对神经元激活函数的Lipschitz系数的多项式依赖性,以及对发生故障的层深度的指数依赖性。我们通过实验证明了我们的理论成果:我们的预测与网络参数和鲁棒性之间的依赖关系相匹配。我们的研究结果表明,神经网络对平均崩溃的鲁棒性是可以估计出来的,而不需要对所有故障配置进行网络测试,也不需要访问用于训练网络的训练集,而这两者也几乎都是不可能的要求。
介绍
在V. Mnih和K. Kavukcuoglu等人所著的《通过深度强化学习进行人为控制》中提到的在围棋比赛中击败世界冠军;在K. He和X. Zhang等人所著的《在整流器中的深入研究:在imagenet分类中超越人类性能》中提及的用超人类精确识别图像;或者最近,A. Esteva和B. Kuprel等人所著的《用深度神经网络进行皮肤癌的皮肤科—皮肤科分级》中提及的用皮肤科医师的精度诊断皮肤癌,在过去十年中,之所以能够在机器学习和人工智能领域取得如此多令人印象深刻的进展都是因为神经网络的使用。最初,这一点是从F. Rosenblatt所著的《感知器:大脑信息存储和组织的概率模型》中提及的自然神经系统工作原理获得的启发,一个神经网络是一个数学对象,它具有突出但尚不十分了解的计算能力。
今天,大多数实现都将神经网络视为一个软件,一个仅能在图灵机进行数学抽象模拟。无疑,这导致了一个计算瓶颈,因为从离散的数字计算到连续的模拟计算,每次软件(模拟一个神经网络)都会查询硬件并得到结果。
扩展机器学习范畴的途径之一就是使用一种不受上述瓶颈影响的新型硬件。神经元硬件的最新进展带来了这样的解决方案,它超越了冯•诺依曼范式(依靠逻辑电路)并且使用本身就是神经网络的电子芯片。一年前,IBM团队报告了一个成功的关于神经网络的神经元实现,它需要运行功率低至从25 mW至275 mW,只有这样才能在一台经典电脑上执行需要数量级的图像识别任务。

IBM苏黎世研究中心制成了世界上第一个人造纳米尺度随机相变神经元
现如今,神经网络被认为是关键和安全敏感领域的应用,如飞行控制、雷达或自动驾驶。如果一个人还不能阐明神经网络的所有工作原理,那么至少应该保证他们对故障的鲁棒性,以便安全地使用它们。
为了实现鲁棒性,我们可以将整个神经网络视为一个单一的软件,在几台机器上复制这一部分,并使用经典的状态机复制机制来增强副本的一致性。在这种情况下,没有一个神经元被认为是独立的:出现故障的单位是承载网络的整个机器。这种粗粒度的方法是最近关于机器学习中鲁棒性研究的成果之一。然而,强制整个网络在单个机器上运行显然妨碍了如上所述的可扩展性。其实,我们还可以将神经网络的严格子集视为不同的软件,每个软件都在一个图灵机上运行。在这种情况下,仍然可以应用经典复制方案,但是必须面对常见的分布式计算问题,例如,处理在网络子集之间交换消息的同步性问题,甚至分布在机器上的网络子集,其计算仍然会面临上述的冯•诺依曼瓶颈问题:仍然使用布尔电路模拟神经网络的模拟和连续计算。
神经元硬件的可扩展性如果想要进一步发展,就需要将每个神经元考虑为可以独立出现故障的单个物理实体,即真正分布式神经网络。在这种情况下,故障单位是单个神经元或突触,而不是整个机器。
事实上,关于围绕神经元硬件效率的热情探讨并不是一种未来主义的炒作。这种类型的硬件已经在敏感应用中使用,其中,单个神经元故障的鲁棒性具有至关重要的作用。截至2017年1月,美国空军承认使用IBM脑芯片,这种芯片的功耗比传统的军用应用计算机低20到30倍。这一点毫不奇怪,因为该芯片是由神经形态电路制成的。
现在,为了举例说明这个问题,我们想在卫星上发送一个由150个神经元(相当小的数量)组成的神经元芯片,并且我们希望它(至少)运行10年。那么我们假设,由于太阳辐射,我们预计在未来这10年里,最多有50个神经元的损失。
显然,遭到损失的神经元将通过某些输入相关算法函数,以改变每个输入的芯片输出,而且如果对于某些输入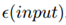 来说,如果太大,那么出于其应用目的考虑,芯片可能变得没有用处或是相当危险。因此,在确定芯片有用性或安全性之前,我们必须获得每个可能的输入的,或至少用max函数来获得这些的上限结果。在没有理论保证的情况下,我们将不得不对150个神经元和每个可能的输入之间的50个神经元的可能组合进行测试。在我们的示例中,这代表
来说,如果太大,那么出于其应用目的考虑,芯片可能变得没有用处或是相当危险。因此,在确定芯片有用性或安全性之前,我们必须获得每个可能的输入的,或至少用max函数来获得这些的上限结果。在没有理论保证的情况下,我们将不得不对150个神经元和每个可能的输入之间的50个神经元的可能组合进行测试。在我们的示例中,这代表 个不同的神经网络,然后将必须用于测试每一个可能的输入。如果对上述IBM芯片执行安全评估,其中包含一百万个神经元,测试将需要比可观察宇宙中的原子更多的执行操作还多(10的80次方级)。这促使需要有一个理论上可靠的鲁棒性保证,不需要不切实际的测试。
个不同的神经网络,然后将必须用于测试每一个可能的输入。如果对上述IBM芯片执行安全评估,其中包含一百万个神经元,测试将需要比可观察宇宙中的原子更多的执行操作还多(10的80次方级)。这促使需要有一个理论上可靠的鲁棒性保证,不需要不切实际的测试。
传统上,我们认为神经网络是具有鲁棒性的,因为神经元的故障常常会地降低其精度,并且这种降低可以通过额外的学习阶段来进行补偿。据我们所知,在单个神经元水平上的故障研究主要是实验性的,或者当包含理论分析时,它侧重于界定单个神经元的损失或考虑到附加学习时的成本所带来的影响。
众所周知,通过额外的学习阶段,神经元的故障性是可以容忍的。然而,对于关键的实时应用来说,停止一个神经网络并启动额外的学习阶段是不可想象的。其实我们还可以预先考虑特定的学习计划(先验),使其能够容忍故障(后验),例如在学习期间关闭部分网络,以便应对运行时的dropout。然而,没有理论结果来预测dropout对鲁棒性的影响。其实我们提出的问题可以实际上进行如下表述:如果(a)我们不对学习方案做任何假设,并且(b)我们排除在计算开始之后添加学习阶段的可能性,一个神经网络可以容忍的有缺陷的神经元的最大数量是多少?
正如我们在《当神经元出现故障时的并行与分布式处理研讨》中所指出的那样,这个问题的答案根本就没有。事实上,如果一个神经网络没有专门设计这个目的,为什么会容忍故障的出现呢?更具体地说,如果一些神经元的故障不会影响整体的结果,那么在最初的设计中就可以将这些神经元淘汰掉。事实上,这个问题的关键在于过度供应。神经网络很少用最少数量的神经元来进行计算。如果想要准确估计这个最小的数字,我们需要知道网络应该近似的目标函数,而根据定义来看,这是未知的。事实上,通过实验可以观察到,过度供应会导致鲁棒性。在最近的研究成果中,基于一个给定的过度供应的预算,我们为神经网络的鲁棒性提供了第一个理论保证。然而,我们关注的是最坏的情况,相较于实际的平均情况,这种情况可能过于悲观。
在本文中,我们证明了一个实用的神经网络鲁棒性估计器可以直接从网络参数中计算出来,而无需对所有可能的输入和所有崩溃情况进行昂贵的比较,并且平均情况受到类似依赖性的影响。通过实验验证我们的方程,并展示了每个参数的预测依赖关系如何反映在实践中。
我们在随机生成的小尺寸神经网络(可以测试所有可能的崩溃情况是可能发生的情况下)以及识别手写数字的实际神经网络(我们测试到了一定数量的故障),建立了这种关系,并提供了神经网络每个关键参数所起的作用的实验证据。为此,我们考虑了多层感知器的经典模型和一般模型,这是数学抽象现代深层学习中使用的拓扑的最通用模型,如流行的卷积方案。
通过实验研究这种预测方法,我们发现诸如图像识别等实际任务的平均情况。为此,我们引入两个量:可以使用所有可能的输入和所有可能的崩溃情况(昂贵的计算)计算的Ω,以及只能由网络的一些常数(廉价计算)计算的Erf。通过实验显示了当改变网络的关键常数时,Ω如何变化,然后提供实验证据,证明Erf是Ω的安全估值。
实验表明,激活函数的利普希茨(Lipschitz)系数的值、大型突触权重的分布,以及网络的深度是控制误差如何在神经网络中传播的关键参数。
简而言之,鲁棒的神经网络是(1)具有低均匀分布的突触权重,(2)如果Lipschitz系数小于1,则较浅,如果该系数大于1,则为深;(3)当深度为一个要求,可以使用低Lipschitz系数的激活函数。
如果选择这样的激活函数是不可能的(实际上并不是所有的激活函数都不能使网络以相同的效率学习),替代方案是Lipschitz行为被限制在一个狭窄区域的功能。
最后,最重要的是,我们的发现了一种方法,当我们考虑所有可能的崩溃时,可以以一种很容易计算的数量来评估网络的鲁棒性,而不需要昂贵的测试,而不需要与网络可能的输入和子网络的组合可能性一样多的计算。有兴趣的读者可以在以下资料库中找到我们实验的源代码和原始数据。
结论
在实际重新获得深度学习的兴趣之前,对神经网络的兴趣在90年代中期逐渐减弱,对单个神经元失败的耐受性也引起了人们的兴趣。随着现代神经元硬件的增长,单个神经元失效的鲁棒性问题变得至关重要。而最近关于鲁棒性的大多数工作都是由粗粒度视图驱动的,其中故障单位是机器,而不是单个神经元。
实际上,从传统观点来看,故障单位是一台机器,将神经网络作为软件抽象托管到更细粒度的视图,其中单个神经元是故障单元,有点像在Borkar的一篇论文中所采取的方法(“从不可靠的组件设计可靠的系统:晶体管变化和退化的挑战”)关于单晶体管故障的文章,或Constantinescu在VLSI电路上的论文(“深度亚微米技术对vlsi电路可靠性的影响”)。在所有这些情况下,失败的单位不是整机,而只是其微观部分(神经元、晶体管等)。
我们的论文表明,神经网络的鲁棒性可以仅根据网络的常数进行评估,而不需要分析网络在其生命周期中可以处理的大量输入,或者测试给定大小的每个可能的神经元子集的关闭情况。
更准确地说,我们提供了理论证据和实验证据,即由于神经元故障而传播到输出的误差是随着K(激活函数的Lipschitz系数)多项式增长的函数,甚至在平均情况下。这种对K的多项式依赖度具有等于发生故障的层深度的程度(因此,误差对深度具有指数依赖性)。我们还表明,输出的传播误差与网络上所有层的乘积成正比,每层权重的平均绝对值。这是对由Lipschitz因子创建的依赖关系加起来的深度的又一指数依赖。基于这些观察,我们得出结论,具有较陡激活函数(Lipschitz系数较高)的神经网络与温和激活函数对应的神经网络相比,鲁棒性较差。抓住这个鲁棒性是以学习为代价:对于一个神经网络学习,Lipschitz系数应该足够高,然而,理论上评估这个系数应该是多高,仍然是一个具有挑战性的开放问题。
感谢:这项工作得到了瑞士国家基金会的支持。
有关更多信息,点击此处查看论文原文。
回复「转载」获得授权,微信搜索「ROBO_AI」关注公众号
 欢迎加入
欢迎加入

中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展

关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册





