人民的名义热播,成了一部国民现象剧,36大数据特意整合了一下有关这部剧的数据分析。让人惊呆了的是,被提到频次最多的竟然不是“人民”,而是“钱”!而人物热度分析上,达康书记竟然真的是第二男主角,
出现频次次数780,仅低于侯亮平1355次
;在人物性格分析上,祁同伟的性格标签中频次最高的是“强大”、“聪明”、“珍惜”、“疯狂”、“激动”。
相对于普通的观众的玩法,我们是工程师嘛,当然要用性冷淡一样的技术手段来好好分析一下《人民的意义》。(
高能
预警:内含jieba模块、TF-IDF算法、TextRank算法等具体技术分析法,太容易激动的亲看到这里可以点一下转发再把文章关掉了
)
首先我们提出几个问题作为本次数据分析的目标:
1. 这部戏主要讲的内容是什么,有哪些主要的角色?
2. 这部戏为什么会这么火呢?
3. 观众都有怎样的评论呢?
4. 这些评论观众的地区分布情况?
为此,我们找到了两个最重要的数据源:
1. 从书本网上,爬去《人民的名义》这本小说,然后对它做了一些简单的文本分析
2. 从豆瓣网上,爬去观众的评论,从评论数据中去发现问题,寻找答案,并启发我们去思考一些社会问题。
到今天为止豆瓣上共有十三万多观众参与了评价,相比于国产片目前评分排名第一的《大明王朝》与《走向共和》,《人们的名义》的参与评论观众人数远大于它们,这在豆瓣堪称史无前例。
先讲豆瓣的部分:
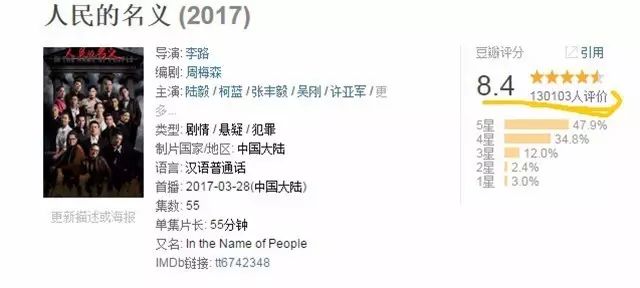

十三万多观众的数据是如何统计的呢, 豆瓣将数据分为三大类:
看过(collections),想看(wishes),在看(doings)。
每一类数据,豆瓣会随机更新呈现出200条评论,为了抓取这些不重复的数据,我开始保存在.txt文件中,发现每次只能抓取200条观众评论数据,当数据再次更新时再爬去数据时,如果改保存的文件名话,这样会导致两个文件保存的数据可能会重复。
为了方便处理与保存这些数据,自己决定把它们保存在MySQL数据库中,通过python爬去数据,每次插入新的数据时,
使用“insert ignore into table_name values( )”命令与定义数据库的键
,这样只要我每运行一次程序就可以得到最新的数据。
分别爬去了每个观众的网址、昵称、地址、评论时间、评论星级,评论内容。如下数据只获取了最近三天的数据,一共有
1345
条数据,其中由于collections这类观众的数据更新较快,爬去的数据也比较多。

在爬去过程中,发现有些观众没有地址,没有评语,或者没有评论星级,
这给爬去数据带来了一些麻烦(主要通过BeautifulSoup,re模块解决)
, 具体的代码后续给出。
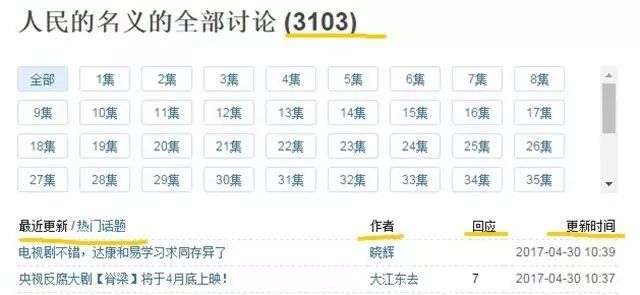
为了关注观众的热门讨论话题,在豆瓣上有一个讨论区,
到目前为止已有3100+讨论话题。同样把这些数据保存在MySQL数据库中,分别抓取了每个热门话题的标题、发起者,回应条数,更新时间与话题对应的网址,
如下表:

再讲一讲用jieba模块做原著的文本分析具体方法与过程:
我们都知道进行自然语言处理的第一步就是分词,下面使用jieba模块对最近比较热的电视剧《人民的名义》进行分词,并对它进行一些简单的文本分析。
jieba模块中常用的方法说明(github):
1.分词:
-
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
-
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细
-
待分词的字符串可以是 unicode 或 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8
-
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator,可以使用 for 循环来获得分词后得到的每一个词语(unicode),或者用
-
jieba.lcut 以及 jieba.lcut_for_search 直接返回 list
-
jieba.Tokenizer(dictionary=DEFAULT_DICT) 新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
最近学习python爬虫,为了练习一下,在书本网上爬去《人民的名义》,代码如下:
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 16 16:24:32 2017
python爬去小说--人民的名义
@author: whb
"""
import urllib2 as p
import re
from bs4 import BeautifulSoup
#得到每个章节的url与标题
def find_html(url):
html=p.urlopen(url).read()
reg=re.compile(r'
(.*?)
')
cont=re.findall(reg,html)
url=[x[0] for x in cont]
name=[x[1] for x in cont]
return [name,url]
# 提取小说正文
def search_content(url_list):
html=p.urlopen(url_list).read()
soup=BeautifulSoup(html)
content=soup.find_all('p')
return content
#将内容保存文件中。
def save_content(url):
name,url=find_html(url)
for i in xrange(len(url)):
try:
print u'正在下载:'+str(name[i])
f=open(str(name[i])+'.txt','w')
url_list='http://www.bookben.com/'+str(url[i])
content=search_content(url_list)
print dir(content)
for x in xrange(len(content)-1):
txt=content[x].string
f.write(txt.encode("gbk",'ignore'))#
f.close()
except IOError:
print 'open error'+str(name[i])
if __name__=='__main__':
url='http://www.bookben.com/read/107_107305/'
save_content(url)
python爬去小说--人民的名义
下面使用jieba.cut()方法对小说进行分词,结果发现一些小说中的名词的分词不如愿,例如如下:
print '/'.join(jieba.cut("str"))
/侯亮/平/代表/反贪/总局/发出/的/抓捕/令/不能/忽视/,/万一出/问题/,/责任/在/我们/省/反贪局/啊/!/季/昌明/却/坚持/向/省委/副/书记/兼/政法委/书记/高育良/汇报/。
原因在于:在分词原理是按照最大概率法来分词,因为单字有一定概率,而“没有侯亮平,季昌明”等这些名词不含词典中,所以会被切割成单字。
提高分词的精准度的方法:自定义添加词典:
jieba.load_userdict(file_name)
注:file_name的格式:
-
每一行有三部分组成:1词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
-
2.file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码(在保存user_dict.txt文件时,另存为UTF-8编码格式即可)。3.词频省略时使用自动计算的能保证分出该词的词频。
1.单变量的分析
首先考虑的是统计评论者的地区分布情况(假定每个评论者的地址正确),直至目前为止共统计了
1658
条数据,发现有
226
个城市参加了评论,我们只给出评论数大于3的城市,如下图所示:
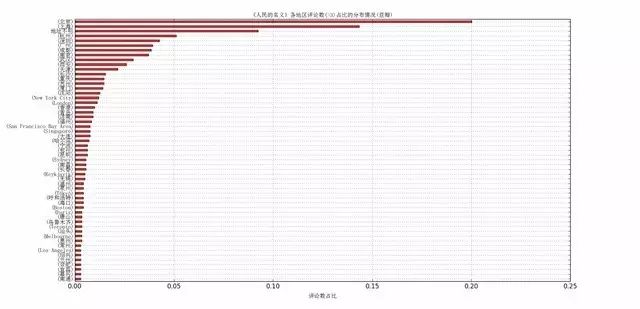
图中“不明地址”表示评论者没有给出自己所在地址,大约有130左右。从图中,我们可以发现
大部分评论者主要分布在北京,上海,杭州,深圳,广州,成都,南京
。我们可以分析一下这数据背后的一些东西,假定评论者越多的城市,说明该城市顾客的参与度越高,商品潜在的需求量就越大,创业成功率就高;所以如果你有一颗创业的心,就多去这些大城市,万一就实现了呢。 除北上广深外,我们发现杭州、成都,南京的评论观众占比也很大;所在国外的评论者数目排名前四是:
纽约,伦敦,旧金山,新加波;从这个角度是否可以说明这四个城市相对其他海外城市中国人较多呢?
下面我们分析一下观众的评星状况,豆瓣评分系统给出,力推(5五颗星),推荐(4颗星),很差(1颗星),未评星,这六种选择。豆瓣是如何处理这些不给评星的数据? 如何打出最后得分?(条目的评分是将豆瓣成员的评价数据加权平均计算后的结果,通过算法的调校,使得海量用户主观喜好的聚合能够更客观准确地反映条目本身的价值。)google发现豆瓣如何具体计算评分不仅仅使用的IMDB评分规则,它其实是个很复杂的过程。因此,在这里只给出了最近四天的统计数据,如下图:
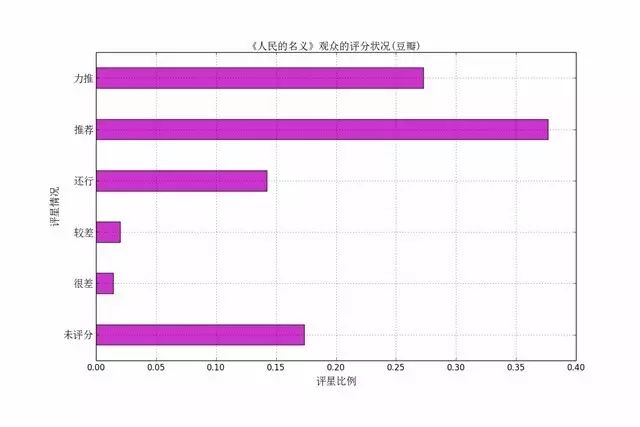
这与豆瓣网上给出的数据有些差别,自己分析主要的原因是:
1、统计的数据不全,只统计了最近四天的数据;
2、有些观众未评分。
下面我们看看,这些评论观众是如何给出评语的?看如下云词图:

从这里我们可以看到,相比大主角侯亮平,大家会关心老戏骨与演技。果然我达康书记一出,灭杀所有小鲜肉。
这里我们介绍一下有关 TF-IDF 算法的部分。
1.基于 TF-IDF 算法
基本原理:提取重要的词条,过滤常见的词语。
TF(team frequency)表示词频=(词语在文章中出现的次数之和)/(文章中的词语之和)
;IDF(Inverse document frequency)反文档频率=log((语料库中总文档之和)/(语料库中包含该词语的文档之和 )).最后它们的乘积为该词条的权重。
优点:简单易实现,但有时精度不高。缺点:不能区分词条的位置信息,在一篇文章中,有时往往是首段与尾段的权重比中间的词条权重大一些。没有反映词条的分布情况。
import jieba.analyse
-
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
-
sentence 为待提取的文本
-
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
-
withWeight 为是否一并返回关键词权重值,默认值为 False
-
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
-
jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件
关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
1 content = open(file_name, 'rb').read()
2 jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
3 tags = jieba.analyse.extract_tags(content, topK=topK)
4 print(",".join(tags))
关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
1 content = open(file_name, 'rb').read()
2 jieba.analyse.set_stop_words("../extra_dict/stop_words.txt")
3 jieba.analyse.set_idf_path("../extra_dict/idf.txt.big");
4 tags = jieba.analyse.extract_tags(content, topK=topK)
5 print(",".join(tags))
2.基于 TextRank 算法
-
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=(‘ns’, ‘n’, ‘vn’, ‘v’)) 直接使用,接口相同,注意默认过滤词性。
-
jieba.analyse.TextRank() 新建自定义 TextRank 实例
基本思想:
-
将待抽取关键词的文本进行分词
-
词性标注
-
以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
-
计算图中节点的PageRank,注意是无向带权图
1 import jieba.posseg as pseg
2 words = pseg.cut("我爱北京天安门")
3 for word, flag in words:
4 ... print('%s %s' % (word, flag))
5 ...
6 我 r
7 爱 v
8 北京 ns
9 天安门 ns





