Hello,大家好,我是阿粉~
不知道大家最近有没有刷过 Java 面试题,有没有发现几乎所有面试题或多或少都会包括 HashMap 面试题。
为什么 Java 中小小的一个 HashMap,值得在面试中被反复提到?
阿粉认为是因为 HashMap 太重要了,大家回看一下自己的业务代码,是不是都有在使用 HashMap ?
即使你真的没有直接使用,但是你使用的一些中间件,或者一些开源框架,这些代码肯定使用 HashMap 完成相关逻辑。
而 HashMap 包含很多核心知识点,从这些知识点可以考察出一个面试者基本知识掌握情况。
其实就算没有面试,我们也应该或多乎或少去了解 一下 HashMap 基本实现原理。因为如果使用 HashMap 不当,很容易写出一连串 Bug,而且可能还不容易排查。
HashMap 面试题网上很多,但是其实怎么问他都离不开这些核心知识点。
这就像我们以前解答数学题一样,背后答案都是围绕核心数学公式。
所以我们只要掌握 HashMap 核心知识点,就不用再怕面试中再问到。
这里阿粉整理一下,HashMap 涉及核心知识点如下:
底层数据结构
数据结构与算法是最近面试越来越注重考查的一方面,尤其是对于校招来讲,这一块百分百会涉及。
而 HashMap 底层结构一下子就涉及三大数据结构,数组、链表、红黑树。
数组
HashMap 中元素实际保存在一个个
Node
中,而
Node
类保存在底层数组中。
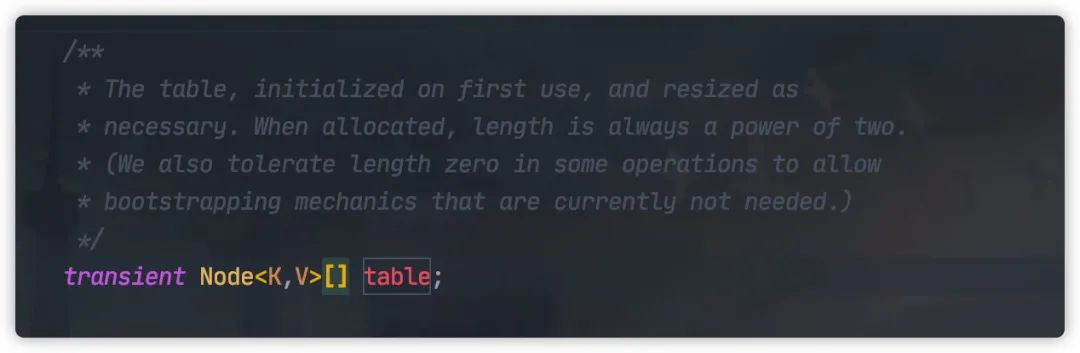
以上代码来自 JDK1.8,JDK1.7 为 Entry 类型。
实际上 Node 为 Entry 类的子类
链表
我们观察一下
Node
类的数据结构,
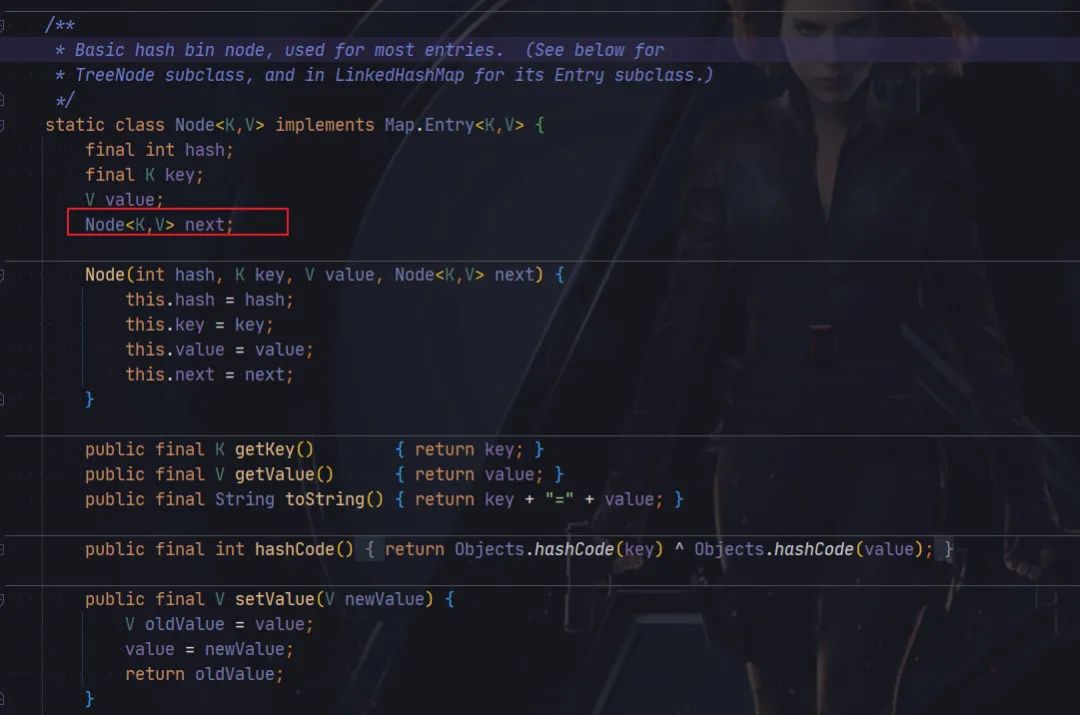
可以发现
Node
类中有一个 next 字段,用于保存下一个
Node
元素,通过这种方式就形成一个单向的链表。
那为什么需要链表那?
这可能与下面说道 Hash算法有关,因为再好的
Hash
算法,都有可能导致不同输入产生相同的输出。
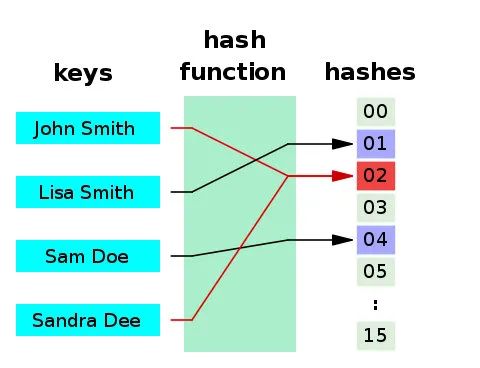 来自:阮一峰的博客
来自:阮一峰的博客
如果不同的输入得到了同一个哈希值,就发生了"哈希碰撞"(collision)。
哈希碰撞解决办法很多,这里 HashMap 就采用拉链法,即使用一个链表保存碰撞的元素的。
其他办法还有:
红黑树
由于链表查找元素复杂度为 O(N),如果 HashMap 哈希碰撞很厉害,从而导致大部分元素落在同一个链表上,这就会导致 HashMap 性能会下降,极端一点 HashMap O(1) 查询复杂度退化成 O(N)的复杂度。
JDK1.8 中引入红黑树数据结构,当链表元素等于 8 时,链表转化为红黑树,这样查找复杂度就可以为 O(logn)。
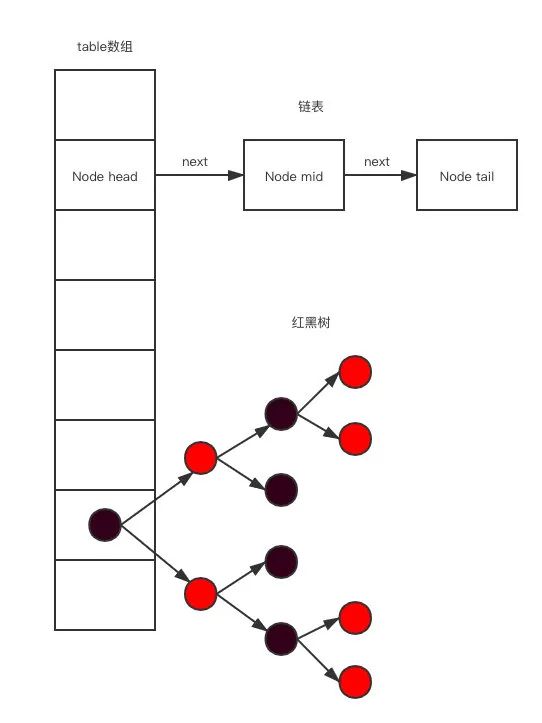 图片来自网络
图片来自网络
那为什么使用红黑树,而不是使用其他二叉树,?
这是因为红黑树对于新增与删除的操作也都能保持O(logn) 新增,这样就完美兼顾了查找与新增性能。
面试题
看完这个知识点,其实可以提很多相关数据结构面试题,比如数组与链表区别。
所以看完这个,我们就需要去整理学习数据结构相关知识。
Hash 算法
这里我们仅仅介绍一下 JDK1.8 Hash 算法。

它使用 key 的 hashcode 高低 16 位异或的方式计算产生。
通过这种方式,在后面寻址算法计算时候,降低碰撞的可能性。
寻址算法
当我们计算得到 Hash 值以后,我们还需要计算这个 Hash 值在数组中的位置。
简单的方式我们可以直接使用求模的方式定位,比如
hash=1000
table.size=16
n=hash%table.size=8
但是 HashMap 采用的是另外一种更为精妙的算法:
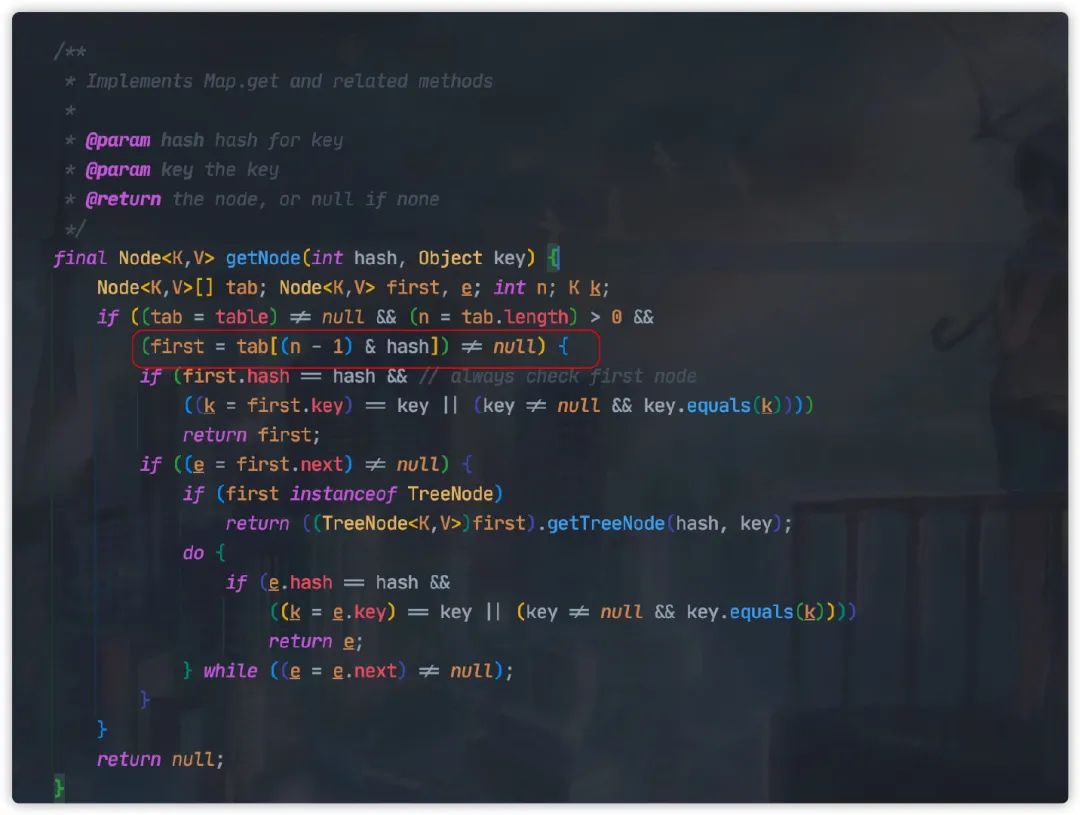
这种方式等同求模法,但是计算性能会更好,但是这里我们需要注意了,
这种方式前提为 n 也就是数组的长度必须为 2 的幂次方
。
这里阿粉就不具体计算了,感兴趣的同学可以网上查找一下推导过程
面试题
为什么 HashMap 扩容都是 2 的幂次方?
看完这个,大家这个面试题了吧。





