近日,analyticsvidhya 上出现了一篇题为《30 Questions to test a data scientist on Natural
Language Processing [Solution: Skilltest – NLP]》的文章,通过 30
道题的测试,帮助数据工程师了解其对自然语言处理的掌握水平。同时文章还附上了截至目前的分数排行榜,最高得分为 24(超过 250
人参与了测试)。如果你也是一名数据工程师,或者相关爱好者,不妨也来比试一下。
人类具有社交属性,语言是人与社会交流信息的主要工具。但是,如果机器也能理解我们的语言并采取相应行动呢?自然语言处理(NLP)是一门教授机器如何理解人类语言的科学。
我们最近推动了一项 NLP 技巧测试,获知你对 NLP 知识的了解,共有 817 人注册。如果你错过了这项测试的机会,没关系,本文中有所有的测试问题和解答。
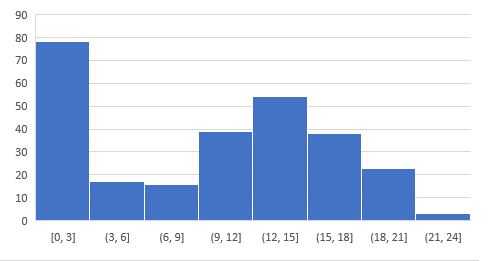
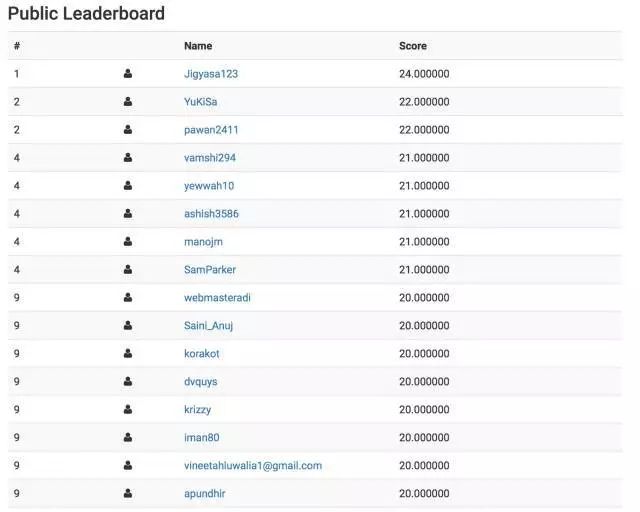
下面是所有人的得分,你可以通过它进行自我评估。超过 250 人参与了该项测试,最高得分是 24。
得分排行榜:https://datahack.analyticsvidhya.com/contest/skilltest-text-mining/lb
下面的资源有助于你对 NLP 有一个更深入的了解。
自然语言处理简单学——通过 SpaCy ( Python):https://www.analyticsvidhya.com/blog/2017/04/natural-language-processing-made-easy-using-spacy-%E2%80%8Bin-python/
终极指南:自然语言处理的理解与实现(附 Python 代码):https://www.analyticsvidhya.com/blog/2017/01/ultimate-guide-to-understand-implement-natural-language-processing-codes-in-python/
1)下面哪项技巧可用于关键词归一化(keyword normalization),即把关键词转化为其基本形式?
1. 词形还原(Lemmatization)
2.Levenshtein
3. 词干提取(Stemming)
4. 探测法(Soundex)
A) 1 和 2
B) 2 和 4
C) 1 和 3
D) 1、2 和 3
E) 2、3 和 4
F) 1、2、3 和 4
答案:C
词形还原和词干提取是用于关键词归一化的技术;Levenshtein 和探测法是用于字符串匹配的技术。
2)N-gram 被定义为 N 个关键词组合在一起。从给定的句子可以产生多少二元组短语(Bigram):
「Analytics Vidhya is a great source to learn data science」
A) 7
B) 8
C) 9
D) 10
E) 11
答案:C
二元组短语: Analytics Vidhya, Vidhya is, is a, a great, great source, source to, To learn, learn data, data science
3)在执行了以下的文本清理步骤之后,可从下面的语句中生成多少三元组短语(trigram):
停用词移除
使用单一空格替换标点符号
「#Analytics-vidhya is a great source to learn @data_science.」
A) 3
B) 4
C) 5
D) 6
E) 7
答案:C
在执行了停用词移除和标点符号替换之后,文本变成:「Analytics vidhya great source learn data science」
三元组短语——Analytics vidhya great, vidhya great source, great source learn, source learn data, learn data science
4)以下哪个正则表达式可用于标识文本对象中存在的日期:「The next meetup on data science will be held on 2017-09-21, previously it happened on 31/03, 2016」
A) \d{4}-\d{2}-\d{2}
B) (19|20)\d{2}-(0[1-9]|1[0-2])-[0-2][1-9]
C) (19|20)\d{2}-(0[1-9]|1[0-2])-([0-2][1-9]|3[0-1])
D) 没有一个
答案:D
问题背景 5-6:
你已经搜集了 10,000 行推特文本的数据并且没有其他信息。你想要创建一个推特分类模型,可以把每条推特分为三类:积极、消极、中性。
5)下面哪个模型可以执行问题背景中提及的推特分类问题?
A) 朴素贝叶斯
B) 支持向量机
C) 以上都不是
答案:C
由于你被给定了推特数据并且没有其他信息,这意味着不存在目标变量,所以不可能训练一个监督学习模型,支持向量机和朴素贝叶斯都是监督学习技巧。
6)通过把每个推特视为一个文档,你已经创建了一个数据的文档词矩阵。关于文件词矩阵以下哪项是正确的?
1. 从数据中移除停用词(stopwords)将会影响数据的维度
2. 数据中词的归一化将会减少数据的维度
3. 转化所有的小写单词将不会影响数据的维度
A) 只有 1
B) 只有 2
C) 只有 3
D) 1 和 2
E) 2 和 3
F) 1、2 和 3
答案:D
1 和 2 是正确的,因为停用词移除将会减少矩阵中特征的数量,词的归一化也将会减少不相关的特征,并且把所有的词变成小写也会减少数据维度。
7)下面哪个特征可以用来提升分类模型的精度?
A) 词频计数
B) 语句的向量符号
C) 语音标签部分
D) 依赖度(Dependency)语法
E) 以上所有
答案:E
8)关于主题建模,总体语句占比多少才是正确的?
1. 它是一个监督学习技巧
2. 线性判别分析(LDA)可用于执行主题建模
3. 模型中主题数量的选择不取决于数据的大小
4. 主题术语的数量与数据的大小成正比
A) 0
B) 25
C) 50
D) 75
E) 100
答案:A
LDA 是无监督学习模型,但 LDA 代表的是隐狄利克雷分布,而不是线性判别分析。模型中主题数量的选择直接与数据的大小成正比,而主题词条的数量并不直接与数据大小成正比。因此没有一个陈述是正确的。
9)在用于文本分类的隐狄利克雷分布(LDA)模型中,α 和 β 超参数表征什么?
A) α :文档中的主题数量,β:假主题中的词条数量
B) α :主题内生成的词条密度,β:假词条中生成的主题密度
C) α :文档中的主题数量,β:假主题中的词条数量
D) α :文档中生成的主题密度,β:真主题内生成的词密度
答案:D
10)根据语句「I am planning to visit New Delhi to attend Analytics Vidhya Delhi Hackathon」解方程。
A = (名词作为语音标签的一部分)
B = (动词作为语音标签的一部分)
C = (频率计数大于 1)
下面哪个是A、B、 C 的正确值?
A) 5、5、2
B) 5、5、0
C) 7、5、1
D) 7、4、2
E) 6、4、3
答案:D
名词:I, New, Delhi, Analytics, Vidhya, Delhi, Hackathon (7)
动词:am, planning, visit, attend (4)
频率计数大于 1 的词:to, Delhi (2)
因此,选项 D 正确。
11)在包含 N 个文档的语料库中,随机选择一个文档。该文件总共包含 T 个词,词条「数据」出现 K 次。如果词条「数据」出现在文件总数的数量接近三分之一,则 TF(词频)和 IDF(逆文档频率)的乘积的正确值是多少?
A) KT * Log(3)
B) K * Log(3) / T
C) T * Log(3) / K
D) Log(3) / KT
答案:B
TF 的公式是 K/T
IDF 的公式是 log
= log(1 / (⅓))
= log (3)
因此正确答案是 Klog(3)/T
12 到 14 的问题背景:
参阅以下的文档词矩阵
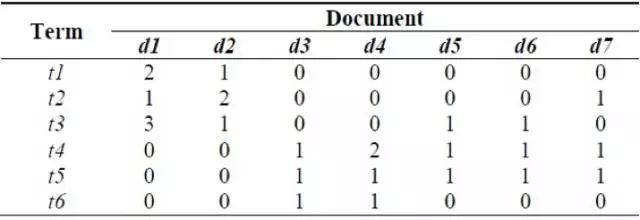
12)下面哪个文档包含相同数量的词条,并且在整个语料库中其中一个文档的词数量不等同于其他任何文档的最低词数量。
A) d1 和 d4
B) d6 和 d7
C) d2 和 d4
D) d5 和 d6
答案:C
文档 d2 和 d4 包含 4 个词条并且不是词条最低数量 3。
13)语料库中最常见和最稀少的词条分别是什么?
A) t4、t6
B) t3、t5
C) t5、t1
D) t5、t6
答案:A
T5 是最常见的词条,出现在 7 个文档中的 5 个,T6 是最稀疏的词条,只在 d3 和 d4 中出现。
14)在该文件中使用最多次数的词条的频次是多少?
A) t6 – 2/5
B) t3 – 3/6
C) t4 – 2/6
D) t1 – 2/6
答案:B
t3 在整个语料库中的使用的最大次数是 3,t3 的 tf 是 3/6
15)下列哪种方法不是灵活文本匹配的一部分?
A)字符串语音表示(Soundex)
B)语音发声散列(Metaphone)
C)编辑距离算法(Edit Distance)
D)关键词哈希算法(Keyword Hashing)
答案:D
除了关键词哈希算法,其它所有方法都用于灵活字串匹配
16)正误判断:Word2vec 模型是一种用于给文本目标创建矢量标记的机器学习模型。Word2vec 包含多个深度神经网络
A)正确
B)错误
答案:B
Word2vec 也包含预处理模型(preprocessing mode),它不属于深度神经网络。
17)下列关于 Word2vec 的说法哪些是正确的(不定项选择)?
A)word2vec 的结构仅包括两层——连续性词包和 skip-gram 模型
B)连续性词包是浅层神经网络模型
C)Skip-gram 是深度神经网络模型
D)CBOW 和 Skip-gram 都是深度神经网络模型
E)以上表述全部正确
答案:D
Word2vec 包含连续性词包和 skip-gram 模型,都是深度神经网络
18)关于无语境依赖关系图(context-free dependency graph),句子里有多少子决策树(sub-trees)?

A)3
B)4
C)5
D)6
答案:D
依赖关系图中的子决策树可以被看做是拥有外部连接的节点,例如:Media, networking, play, role, billions, 和 lives 是子决策树的根。
19)文本分类模型组成部分的正确顺序是:
1. 文本清理(Text cleaning)
2. 文本标注(Text annotation)
3. 梯度下降(Gradient descent)
4. 模型调优(Model tuning)
5. 文本到预测器(Text to predictors)
A) 12345
B) 13425
C) 12534
D) 13452
答案:C
正确的文本分类模型包含——文本清理以去除噪声,文本标注以创建更多特征,将基于文本的特征转换为预测器,使用梯度下降学习一个模型,并且最终进行模型调优。
20)多义现象可以被定义为在文本对象中一个单词或短语的多种含义共存。下列哪一种方法可能是解决此问题的最好选择?
A)随机森林分类器
B)卷积神经网络
C)梯度爆炸
D)上述所有方法
答案:B
CNN 是文本分类问题中比较受欢迎的选择,因为它们把上下文的文本当作特征来考虑,这样可以解决多义问题。
21)下列那种模型可以被用于文本相似度(document similarity)问题?
A)在语料中训练一个由词到向量(word 2 vector)的模型来对文本中呈现的上下文语境进行学习
B)训练一个词包模型(a bag of words model)来对文本中的词的发生率(occurrence)进行学习
C)创建一个文献检索词矩阵(document-term matrix)并且对每一个文本应用余弦相似性
D)上述所有方法均可
答案:D
word2vec 模型可在基于上下文语境的情况下用于测量文本相似度。词包模型(Bag Of Words)和文献检索词矩阵(document term matrix)可以在基于词条的情况下用来测量相似度。
22)下列哪些是语料库的可能性特征?
1. 文本中词的总数
2. 布尔特征——文本中词的出现
3. 词的向量标注
4. 语音标注部分
5. 基本依赖性语法
6. 整个文本作为一个特征
A) 1
B) 12
C) 123
D) 1234
E) 12345
F) 123456
答案:E
除了全部文本作为特征这个选项,其余均可被用作文本分类特征,从而来对模型进行学习。
23)
当在文本数据中创建一个机器学习模型时,你创建了一个输入数据为 100K 的文献检索词矩阵(document-term matrix)。下列哪些纠正方法可以用来减少数据的维度——
1. 隐狄利克雷分布(Latent Dirichlet Allocation)
2. 潜在语义索引(Latent Semantic Indexing)
3. 关键词归一化(Keyword Normalization)
A)只有 1
B)2、3
C)1、3
D)1、2、3
答案:D
所有的这些方法都可用于减少数据维度。
24)谷歌搜索特征——「Did you mean」,是不同方法相混合的结果。下列哪种方法可能是其组成部分?
1. 用协同过滤模型(Collaborative Filtering model)来检测相似用户表现(查询)
2. 在术语中检查 Levenshtein 距离的模型
3. 将句子译成多种语言
A)1
B)2
C)1、2
D)1、2、3
答案:C
协同过滤可以用于检测人们使用的是何种模式,Levenshtein 用来测量术语间的距离。
25)在处理自然结构的新闻性句子的时候,哪种基于语法的文本句法分析方法可以用于名词短语检测、动词短语检测、主语检测和宾语检测。
A)部分语音标注
B)依存句法分析(Dependency Parsing)和选取句法分析(Constituency Parsing)
C)Skip Gram 和 N-Gram 提取
D)连续性词包
答案:B
依存句法分析和选取句法分析可从文本中提取这些关系。
26)社交媒体平台是文本数据最直观的呈现形式。假设你有一个推特社交媒体完整语料库,你会如何创建一个建议标签的模型?
A)完成一个主题模型掌握语料库中最重要的词汇;
B)训练一袋 N-gram 模型捕捉顶尖的 n-gram:词汇和短语
C)训练一个词向量模型学习复制句子中的语境
D)以上所有
答案:D
上面所有的技术都可被用于提取语料库中最重要的词条。
27. 在从文本数据中提取语境时,你遇到两个不同的句子:The tank is full of soldiers. The tank is full of nitrogen。下面哪种措施可被用于句子中词意模糊的问题?
A)对比模糊词汇与近义词在词典上的定义
B)同指(Co-reference) 解决方案,使用先前句子中包含的正确词意解决模糊单词的含义。
C)使用句子的依存解析理解含义
答案:A
A 选项被称为 Lesk 算法,被用在词意模糊问题上,其他选择不对。
28)协同过滤和基于内容的模型是两种流行的推荐引擎,在建立这样的算法中 NLP 扮演什么角色?
A 从文本中提取特征
B 测量特征相似度
C 为学习模型的向量空间编程特征
D 以上都是
答案:D
NLP 可用于文本数据相关的任何地方:特征提取、测量特征相似度、创造文本的向量特征。
29)基于检索的模型和生成式模型是建立聊天机器人的两个主流技术,下面那个选项分别包含检索模型和生成式模型例子?
A. 基于辞典的学习和词向量模型
B. 基于规则的学习和序列到序列模型
C. 词向量和句子到向量模型
D. 循环神经网络和卷积神经网络
答案:B
选项 B 最佳诠释了基于检索的模型和生成式模型的例子。
30)CRF(条件随机场)和 HMM(隐马尔可夫模型)之间的主要区别是什么?
A.CRF 是生成式的,而 HMM 是判别式模型;
B.CRF 是判别式模型,HMM 是生成式模型。
C.CRF 和 HMM 都是生成式模型;
D.CRF 和 HMM 都是判别式模型。
答案:B





