本文是大数据杂谈5月4日社群分享内容整理。
我先自我介绍一下,我叫罗韵,是深圳极视角科技有限公司联合创始人,我们公司是一家做人工智能和计算机视觉应用的创业公司,我们平台目前服务各个细分领域,其中包括零售行业、工业、智能家居、餐饮、安防等,提供图像处理和视频分析的服务。作为一家创业公司,极视角荣登"2016 中国人工智能创业公司 Top50"以及入选"2017 国内最值得关注的 AI 视觉创业项目 Top20"。当前我们正在做的事情就是希望让计算机视觉变成一种可以服务于各行各业的服务平台——极市平台 cvmart.net。
今天给大家介绍内容包括四个部分(如上图),其中是一环扣一环步步递进的,从两个算法 (并非原创算法) 切入,我们看一个算法如何被应用,然后基于各种应用的需求,算法又如何转化成为一个服务去服务更多的社会需要。

我的分享总体来说会更偏应用性,因为我们主要就是做 CV 应用。
首先,给大家介绍一个很常见而非常有应用前景的算法应用案例:识别一个图片或者画面、视频里面可能有什么东西?例如如图:

要实现这样识别算法,当前我们可以结合深度学习的目标检测算法,例如有 R-CNN,SPP-Net,Fast R-CNN,Faster R-CNN,以及在 PASCAL VOC、MS COCO、ILSVRC 数据集上取得领先的基于 Faster R-CNN 的 ResNet 等。
以上的方法都可以归纳为一个基本都流程:proposal 候选框 + 分类器,只是有的候选框从原图就定位了,而有的 bounding box 候选框则是通过 feature map 来定位。而这样的流程在运行速度上会存在着比较大的局限。当然,大家也在不断的往更快的速度去优化。
而我们今天先不讨论上述的方法,而是讨论两个运行速度更快的目标检测模型。
第一个是,YOLO(You Only Look Once),YOLO 是一个可以一次性预测多个 Box 位置和类别的卷积神经网络,能够实现端到端的目标检测和识别,其最大的优势就是速度快。目标检测的本质其实也是回归,因此一个实现回归功能的 CNN 并不需要复杂的设计过程。
YOLO 没有选择滑窗或提取 proposal 的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用 proposal(选定候选集) 训练方式的 Fast-R-CNN 常常把背景区域误检为特定目标。
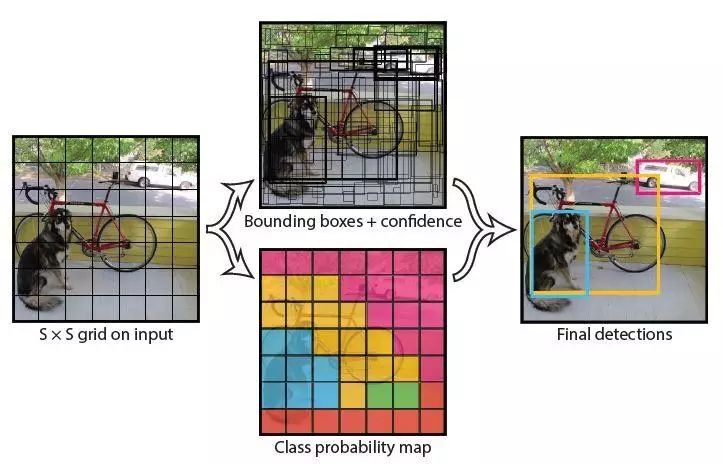
YOLO 的设计理念遵循端到端训练和实时检测。YOLO 将输入图像划分为 S*S 个网络,如果一个物体的中心落在某网格 (cell) 内,则相应网格负责检测该物体。
在训练和测试时,每个网络预测 B 个候选区域,每个候选区域对应 5 个预测参数,分别是候选区域 (bounding box) 的中心点坐标 (x,y), 宽高 (w,h) 和置信度评分。
这里的置信度评分:
(Pr(Object)*IOU(pred|truth))
综合反映基于当前模型候选区域内存在目标的可能性 Pr(Object) 和候选区域 (bounding box) 预测目标位置的准确性 IOU(pred|truth)。
如果候选区域内不存在物体,则 Pr(Object)=0。如果存在物体,则根据预测的候选区域 (bounding box) 和真实的区域 (bounding box) 计算 IOU,同时会预测存在物体的情况下该物体属于某一类的后验概率 Pr(Class_i|Object)。
假定一共有 C 类物体,那么每一个网格只预测一次 C 类物体的条件类概率 Pr(Class_i|Object), i=1,2,...,C; 每一个网格预测 B 个候选区域 (bounding box) 的位置。即这 B 个候选区域 (bounding box) 共享一套条件类概率 Pr(Class_i|Object), i=1,2,…,C。
基于计算得到的 Pr(Class_i|Object),在测试时可以计算某个候选区域 (bounding box) 类相关置信度:
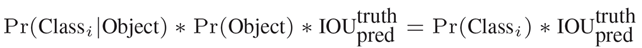
如果将输入图像划分为 7*7 网格(S=7),每个网格预测 2 个 bounding box (B=2),有 20 类待检测的目标(C=20),则相当于最终预测一个长度为 S*S*(B*5+C)=7*7*30 的向量,从而完成检测和识别任务。
第二个同样是目标检测的算法,SSD(Single Shot MultiBox Dectector)。这是另一个基于深度学习的物体检测模型,他的特点主要是检测的速度在能保证精度下保持非常快的速度,除此之外,该物体检测算法在大目标的检测下有比较好的效果。
而我们发现,往往我们的照片中,大目标比比皆是。SSD 比原先最快的 YOLO: You Only Look Once 方法,还要快,还要精确。保证速度的同时,其结果的 mAP 可与使用 region proposals 技术的方法(如 Faster R-CNN)相媲美。
SSD 方法的核心就是预测物体,以及其归属类别的得分;同时,在 feature map 上使用小的卷积核,去预测一系列候选区域的位置。
SSD 为了得到高精度的检测结果,在不同层次的 feature maps 上去 预测物体类别和物体位置。
SSD 这些改进设计,能够在当输入分辨率较低的图像时,保证检测的精度。同时,这个整体端到端的设计,训练也变得简单。在检测速度、检测精度之间取得较好的平衡。
然而,以上的仅仅是一个照片内容识别的算法,还没有真正的成为到了一个解决实际问题的应用,接下来,我们将讲解的就是利用这样的识别技术,我们进一步可以解决的问题就是:
在印刷行业或者快照行业,会陆续推出一项产品——电子相册。
而电子相册从技术层面主要是要解决两个问题,1. 照片裁剪,2. 相框的匹配。
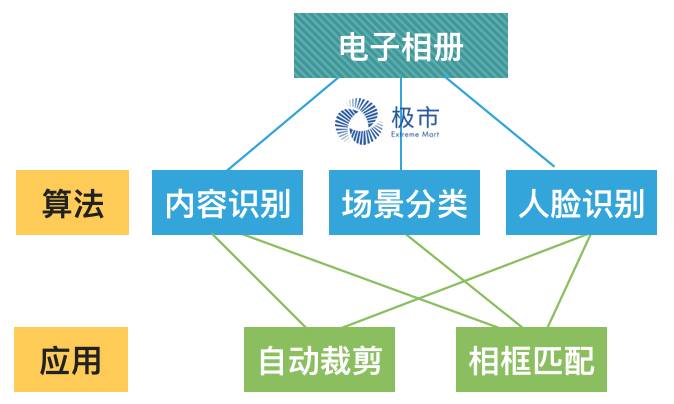
而当前,这些工作都是人工去完成,随着日益增长的电子图片的需求量,制作电子相册的人力成本越来越大,而这个时候,利用之前所述的内容识别算法,我们可以帮助电脑自动实现图片的裁剪,因为自动裁剪最大的担忧可能是担心把照片内的人裁剪掉了。
另一方面,我们进而可以结合图片场景分类和人脸识别等算法技术,使用标签匹配方法去自动匹配与照片本身更搭配的相框。
如上,我们就以快照印刷行业的电子相册作为一个行业应用的例子,但其实还有很多行业内容其他的应用例子不胜枚举。
算法本身我们可以做出很多技术,例如使用物体检测我们可以实现内容识别、除此之外我们还实现场景分类、人脸的识别、颜色的分类、人物表情等等。
而技术项目的组合,可以帮助我们是去实现更多行业内的目前人工完成的工作,例如实现自动裁剪、通过根据图片的内容、场景的分类、人脸信息等,匹配出合适的相框作为推荐,根据不同颜色的印刷材料做不同的印刷批次排序等等。
于是,一个简单的印刷快照行业的升级,我们可以归纳为如图:
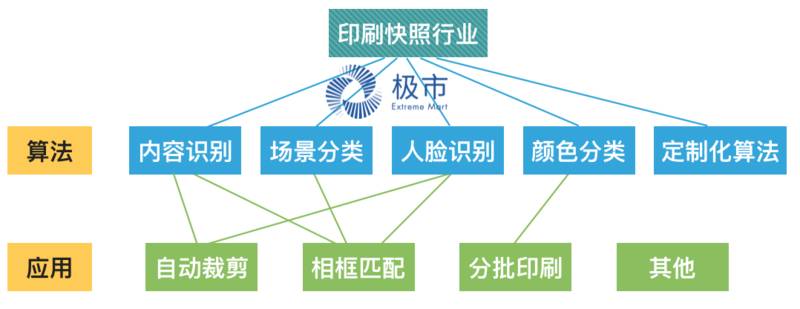
而由图中,我们可以看到,技术和应用本质上是完全可以分开做横向拓展的,于是我们可以看到同样的技术可以用在不同的行业,也可以有很多不同行业特定的算法技术,如图:
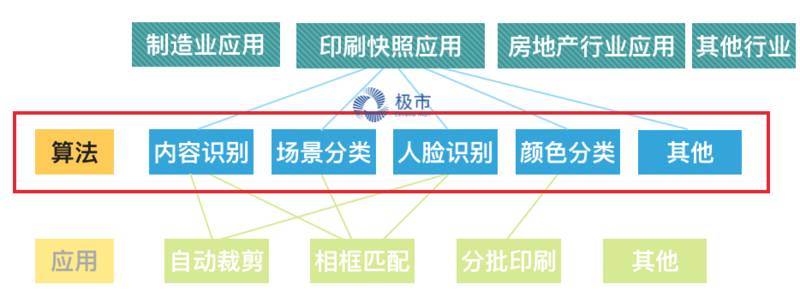
CVaaS 是我概括出来的一个词语,第一次介绍给大家,意思就是计算机视觉算法即服务的意思,在过往,我们可能听说过,IaaS(Infrastructure as a Service),PaaS(Platform as a Service),SaaS(Software as a Service), 大家都把不同层次的标准化模块变成一种服务在提供。
而 CVaaS 就是 Computer Vision as a Service, 我们把 CV 的部分标准化成为了一种服务,而每一个行业可以在这里找到自己行业需要的和图像处理、视频处理、计算机视觉相关的算法服务,然后他们可以整合这些算法服务成为他们需要的应用。
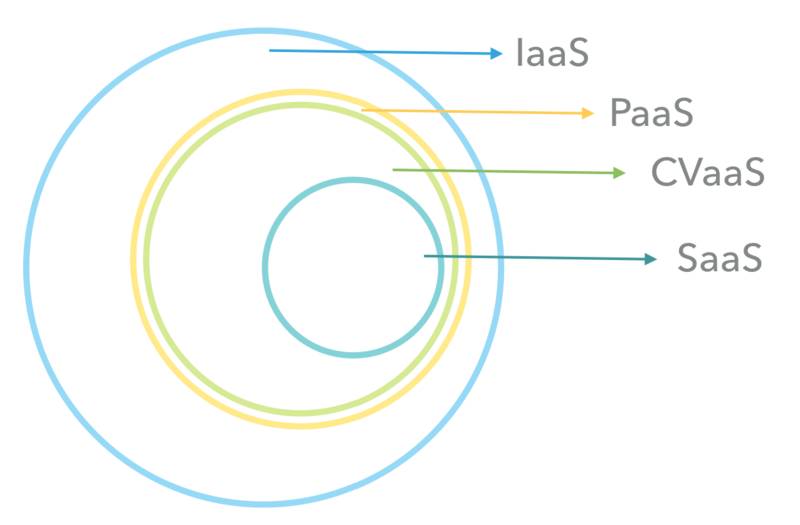
而 CV 算法更接近于一种平台运行的服务,提供运算性能的横向拓展,提供运算的底层开发环境,甚至乎直接提供可开发测试的 sandbox, 所以,CVaaS 也是 PaaS 的一种。
各行各业都有他需要的和 AI 取代的工作,从而提升行业的效率,正如李开复老师说的,50% 的工作会被 AI 取代,而评判的标准就是“五秒钟准则”。
“五秒钟准则”:一项本来由人从事的工作,如果人可以在 5 秒钟以内对工作中需要思考和决策的问题做出相应的决定,那么这项工作就非常大的可能被人工智能技术全部或部分取代。
而 CVaaS 的目的,就是让各行各业可以以最快的形式和方式完成这要的一些工作的转变。
例如,在零售行业,我们选择可以选择人脸识别做 VIP 识别,选择行人识别做客流统计,选择性别、年龄识别做顾客分类或者顾客肖像。
在安防行业,我们选择动作 (打架) 识别、行人跟踪、姿态识别等做安全的防范和预警。
再例如,在房地产领域做场景图片的分类 (例如哪些图片是卧室,客厅,厨房),优质 (封面) 图片的挑选;印刷行业根据图片的内容做自动裁剪;等等。

极市 CVaaS 平台主要面向三个群体,具有算法服务开发能力的开发者,需要使用算法服务的行业用户以及海量和我们对接的硬件厂商。对于开发者,平台设计基于 Gitlab 的代码 (SDK) 管理,版本管理,Gitlab 是目前比较流行的开源类 Github 代码管理平台。
开发者可以提交自己认为满意的版本,对于不想提供源码的,可以提供 SDK 即可。对自己的算法的数据输入端,使用平台提供的输入 SDK 对接,可以对自己的算法进行场景使用和介绍做详细的描述,就想我们去 APP Store 提交一个 APP 一样。
此外,开发者拥有自己的管理后台,每天可以查询到自己的算法被使用和应用的情况,以及最新的收入。
我们也知道,对于 CV 或者 AI 类算法,最重要的莫过于数据集,所以,在平台设计中,我们增加了海量测试数据的模块,可以提供给不同应用的开发者测试集。
而每一个算法服务的运行,则基于 docker 的隔离运行,docker 用来隔离应用还是很方便的,一来本身的操作较为简单,二来资源占用也比虚拟机要小得多,三来也较为安全,因为像数据库这样的应用不会再全局暴露端口,同时应用间的通信通过加密和端口转发,更加安全。
基于海量硬件与我们系统的无缝链接,每一个在平台上的算法应用,即可面向近百万摄像机用户的使用可能。
所有平台的设计最终都是为了服务社会和个人,而 AI 作为当前的与社会紧密相同的技术,我们希望使得更多不同的行业用更轻松简单的方法与技术相结合,而我们这些懂技术的人,也可以有更多的方式去贡献我们的能力,这个就是我们极视角和我们的产品“极市”的初衷。
Q1: “我是一位机器学习爱好者,对机器学习平台比较感兴趣,也希望能够参与开源社区,看到您是 Tensorflow Contributor 感觉很厉害,请问我应该如何努力才能也成为 Tensorflow Contributor。”
罗韵
:开源社区其实有非常多非常优秀的项目,一开始如果能力不够,可以从看别人的代码开始,如果渐渐能读懂别人的代码,一般成熟的开源项目都有开发计划的,而且是公开的,有些功能是专门公开给社区去实现的,那就可以自己去实现,还有一种情况就是你发现了项目本身存在的问题或者 bug,然后你去完善好。
Q2: “请师从港科大哪位大牛呀?是杨强教授吗?”
罗韵
:是的。
Q3:“对工作一段时间的软件工程专硕来说,如何申请名校深度学习的 PHD?没有论文,本硕名校,BAT 工作背景。”
罗韵
:首先先确定你是有耐心和恒心愿意去读 PhD,毕竟也是好几年光阴,其次就是我觉得还是个人需要有自己的一点点小成果或者做出一点可以打动导师的东西,最后就是,工作中的积累也是很有用的,个人愚见,这个问题因人而异的。
Q4: “如何在嵌入式平台,比如 ARM Cortex A73 四核平台上部署机器视觉,应用到图像识别分类?”
罗韵
:这个问题有点太泛了,具体还要看图像识别分类,做的是什么分类,分多少类,整体的项目程序的复杂度等,一般如果部署成功了,很多时候也要看具体场景的要求,例如场景要求实时,但是速度上就是无法支持,这个也是其中一些难点所在。
Q5:“对美女讲师提到的 CVaas 蛮好奇的~ 请问这个有什么优势吗”
罗韵
:优势有几个方面,第一,作为一个 CVaaS 其实就是一个连接技术与需求的桥梁,所以,我们首先已经拥有了大量的场景的硬件(摄像头)作为用户,所以,在这里的所有 Service 都不基本不用担心是否有人使用的问题,只要是好的 CV Service,都有对应的潜在用户。










