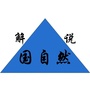
寻常型银屑病
(Psoriatic vulgaris ,PsV)
是一种常见的慢性、复发性、炎症性皮肤 病,严重影响患者的生活质量。银屑病的确切病因和发病机制尚不清楚, 银屑病在世界各地不同人群中的患病率有明显差异,以北欧为最高,白人发病率较亚洲人高。银屑病发生可从出生到 90 岁以上任何年龄, 发病高峰在 15 ~30 岁。
银屑病的病因虽然至今仍不清楚, 但越来越多的证据表明遗传因素和环境因素在银屑病的发病中起到重要作用。其中银屑病与遗传相关的研究已经有近100年的历史了,如在双胞胎中,单卵双生胎共患银屑病的概率是异卵双生胎的 3 倍。
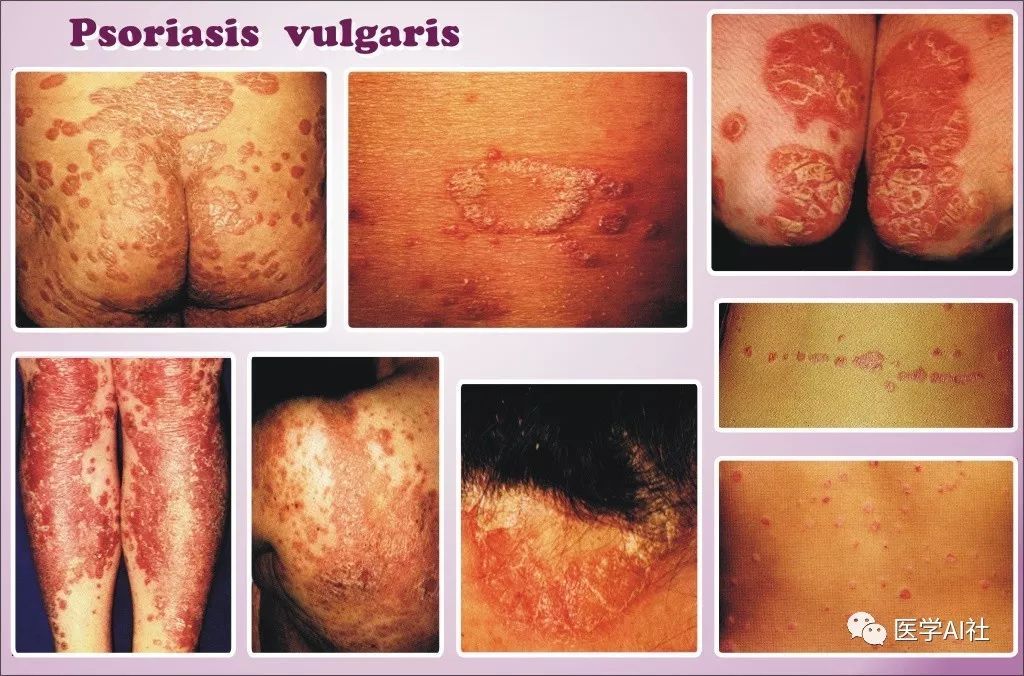
银屑病关节炎(Psoriatic arthritis ,PsA)
是一种与寻常型银屑病相关的慢性炎症性肌肉骨骼疾病,影响全世界人群。 虽然PsA的患病率在一般人群中很少见(<0.5%), 但是在PsV人群中越有
30%
会出现PsA,且其症状通常在出现皮肤病变已经诊断为PsV之后出现,主要的临床表现是:
关节疼痛、肿胀、畸形和运动受限。
PsA使得患者生活质量下降,并与合并症相关,增加死亡率,从而给社会带来了重大的社会和经济负担。 早期诊断对于有效管理至关重要,PsA诊断之前症状持续时间越长,病变导致的关节侵蚀和炎症越重,预后通常越差。
由于疾病表现方式的变化及其发展方式的变化,PsA的早期诊断比较困难,有研究表明有15%接受皮肤病治疗PsV患者估计有未确诊的PsA。
目前的PsA诊断方法基于临床、实验室和放射学特征,包括使用诸如银屑病性关节炎的ClASsication标准之类的标准和MAdrid超声粘附炎指数。 然而,目前为止几乎没有能够为患者在关节症状出现之前,提供PsA风险定量评估的系统策略。
导 语
银屑病关节炎(PsA)
是一种复杂的慢性肌肉骨骼疾病,约占PSV患者的30%。 目前,尚无利用PsA和仅皮肤银屑病(Cutaneous-only psoriasis ,PsC)之间
遗传结构的差异的
系统来评估症状出现前PsA的风险。 在我们要介绍的这项研究中,研究者引入了一个用于
预测银屑病患者发生PsA的计算程序
。
使用来自六个群组的数据,其中包括> 7000基因型PsA和PsC患者。 研究者鉴定了PsV和PsV亚型的9个新基因位点,并且在使用200个遗传标记时区分PsA与PsC准确率达到了0.82。 在银屑病患者中预测PsA,实现> 90%的精确度,100%的特异性和16%的回忆率。 结合统计学和机器学习技术,表明PsV亚型之间潜在的遗传差异可用于个体化亚型的风险评估。

图片来自诺华制药。
研 究 简 介
研究标题:
Genetic signature to provide robust risk assessment of psoriatic arthritis development in psoriasis patients
发表杂志:
Nature Communication (IF:12.353)
在线日期:
2018-10-09
研究者及单位:
第一作者为美国密歇根大学医学院皮肤病学系Matthew T. Patrick,其他还有加拿大、德国、瑞典等多个皮肤病相关单位(具体见原文)
研 究 小 结:
结合
统计学
和
机器学习
技术,发现银屑病亚型之间潜在的遗传差异可用于个体化亚型风险的评估。
结合统计学和机器学习技术,预测PsV患者发生PsA的风险。
(1)患者来源:使用来自六个群组的数据,其中包括> 7000名基因型明确的PsA和PsC患者。
(2)数据处理: 将PsC亚型定义为PsV患者,且患病超过10年,但未被诊断为PsA。 所有PsV患者均由皮肤科医生诊断,并且PsA状态由风湿病学家(和/或具有PsA诊断专业培训的皮肤科医生)评估。
(3)分阶段和估算: 使用ShapeIT45确定定相,通过基于图的计算来提高估算的准确性和速度,所述统计单倍型估计与样品和标记的数量线性地成比例。
(4)关联分析:逻辑回归测试。
(5)Meta分析:METAL逆方差法。
(6)机器学习的培训:子类型的预测和风险评估。
(7)代码:Github
https://github.com/cutaneousBioinf

图1:a,预测PSV亚型的计算程序。程序概述,通过质量控制、定相和插补、关联分析、Meta分析和逐步条件分析。 b,机器学习过程包括将数据随机分成训练(交叉验证以优化模型)和测试(保持)集,以及使用和不使用PAGE Immunochip数据集评估结果。 QC质量控制。
(1)每个基因型队列中的患者人数和标志物。

(2)鉴定PsV和PsV亚型的新基因位点。

图 2:Meta分析的结果。该研究所确定的新基因位点以红色突出显示,而在此研究中未在全基因组中显着的基因位点以蓝色突出显示,基于以下比较的Meta分析结果:a PsV与对照; b PsA与对照; 和c PsC vs.对照.

图3:调节元素的富集,使用H3K27预测的激活增强子富集累积。
(3)PsA风险预测:

图4:风险预测和评估。 在交叉验证集上,对26个MLR分类中的最高分类(penalized.ridge logistic ridge regression; lda linear discriminant analysis; earth multivariate adaptive regression splines; randomForest random forest; cforest conditional inference forest)的完整基准性能。 b .Classier性能(在CV和测试集上),使用接AUC下的面积计算。 c.当预测不同比例的样本在保持测试集中具有PsA时,在精确度和召回之间进行权衡。 d.评估分类校准,在PsA的不同先验概率下(在PsA / PsC 3:7 比率测试集上),随后用于预测尚未确诊的PsV亚型患者发生PsA的风险。
该工作将机器学习技术与迄今为止最多基因型的PsA和PsC样本相结合,全面揭示PsV的遗传特征(通过结合参考小组进行统计学估算)并预测PsA的风险, 发现了9个PsV和PsV亚型的新基因位点,并建议仅使用遗传数据就可以实现对PsA和PsC的稳健预测。