对于规模小、爬取数据量小、对爬取速度不敏感的爬虫程序, 使用
Requests
能轻松搞定。这些爬虫程序主要功能是爬取网页、玩转网页。如果我们需要爬取网站以及系列网站,要求爬虫具备爬取失败能复盘、爬取速度较高等特点。很显然
Requests 不能完全满足我们的需求。因此,需要一功能更加强大的第三方爬虫框架库 —— Scrapy
1 简介 Scrapy
Scrapy 是一个为了方便人们爬取网站数据,提取结构性数据而编写的分布式爬取框架。它可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中。因其功能颇多,所以学会它需要一定的时间成本。
1.1 Scrapy 的特性
Scrapy 是一个框架。因此,它集一些各功能强大的 python 库的优点于一身。下面列举其一些特性:
-
HTML, XML源数据 选择及提取 的内置支持
-
提供了一系列在spider之间共享的可复用的过滤器(即 Item Loaders),对智能处理爬取数据提供了内置支持。
-
通过 feed导出 提供了多格式(JSON、CSV、XML),多存储后端(FTP、S3、本地文件系统)的内置支持
-
提供了media pipeline,可以 自动下载 爬取到的数据中的图片(或者其他资源)。
-
高扩展性。您可以通过使用 signals ,设计好的API(中间件, extensions, pipelines)来定制实现您的功能。
-
内置的中间件及扩展为下列功能提供了支持:
-
cookies and session 处理
-
HTTP 压缩
-
HTTP 认证
-
HTTP 缓存
-
user-agent模拟
-
robots.txt
-
爬取深度限制
-
健壮的编码支持和自动识别,用于处理外文、非标准和错误编码问题
-
针对多爬虫下性能评估、失败检测,提供了可扩展的 状态收集工具 。
-
内置 Web service, 使您可以监视及控制您的机器。
1.2 安装 Scrapy
Scrapy
是单纯用 Python 语言编写的库。所以它有依赖一些第三方库,如lxml,
twisted,pyOpenSSL等。我们也无需逐个安装依赖库,使用 pip 方式安装 Scrapy 即可。pip 会自动安装 Scrapy
所依赖的库。随便也说下 Scrapy 几个重要依赖库的作用。
-
lxml:XML 和 HTML 文本解析器,配合 Xpath 能提取网页中的内容信息。如果你对 lxml 和 Xpath 不熟悉,你可以阅读我之前介绍该库用法的文章。
-
Twisted:Twisted 是 Python 下面一个非常重要的基于事件驱动的IO引擎。
-
pyOpenSSL:pyopenssl 是 Python 的 OpenSSL 接口。
在终端执行以下命令来安装 Scrapy
pip install Scrapy
# 如果出现因下载失败导致安装不上的情况,可以先启动 ss 再执行安装命令
# 或者在终端中使用代理
pip --proxy http://代理ip:端口 install Scrapy
你在安装过程中也许会报出安装 Twisted 失败的错误:
running build_ext
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
----------------------------------------
Failed building wheel for Twisted
Running setup.py clean for Twisted
Failed to build Twisted
原因是
Twisted 底层是由 C 语言编写的,所以需要安装C语言的编译环境。对于Python3.5来说,可以通过安装 Visual C++
Build Tools 来安装这个环境。打开上面报错文本中的链接,下载并安装 visualcppbuildtools_full
。等安装完成,再执行 安装 Scrapy 命令。
安装成功之后如下图:
点击查看大图
2 初探 Scrapy
2.1 Scrapy 项目解析
Scrapy 新建项目需通过命令行操作。在指定文件夹中,打开终端执行以下命令:
scrapy startproject 项目的名字
我新建一个名为 scrapy_demo,执行结果如下。

点击查看大图
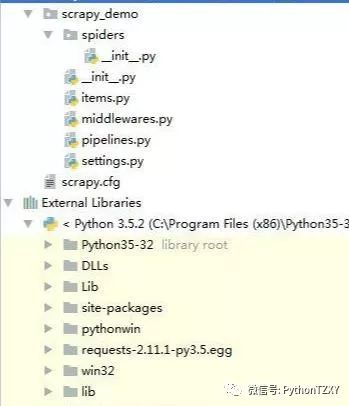
使用 Pycharm 打开该项目,我们会发现项目的层级架构以及文件。
私信小编007即可获取数十套PDF的获取方式哦!
点击查看大图
这些文件的作用是:
-
scrapy.cfg:项目的配置文件,开发无需用到。
-
scrapy_demo:项目中会有两个同名的文件夹。最外层表示 project,里面那个目录代表 module(项目的核心)。
-
scrapy_demo/items.py:以字段形式定义后期需要处理的数据。
-
scrapy_demo/pipelines.py:提取出来的 Item 对象返回的数据并进行存储。
-
scrapy_demo/settings.py:项目的设置文件。可以对爬虫进行自定义设置,比如选择深度优先爬取还是广度优先爬取,设置对每个IP的爬虫数,设置每个域名的爬虫数,设置爬虫延时,设置代理等等。
-
scrapy_demo/spider: 这个目录存放爬虫程序代码。
-
__init__.py:python 包要求,对 scrapy 作用不大。
2.2 Scrapy 的架构
我们刚接触到新事物,想一下子就熟悉它。这明显是天方夜谭。应按照一定的顺序层次、逐步深入学习。学习
Scrapy 也不外乎如此。在我看来,Scrapy 好比由许多组件拼装起来的大机器。因此,可以采取从整体到局部的顺序学习 Scrapy。下图是
Scrapy 的架构图,它能让我们对 Scrapy 有了大体地认识。后续的文章会逐个介绍其组件用法。
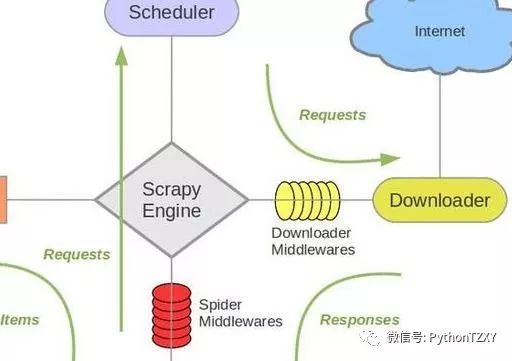
我按照从上而下,从左往右的顺序阐述各组件的作用。










