本次推送的文章将介绍并评估一种自动提取新闻报道的叙事框架的方法。其中,“框架”是指新闻报道对某些元素的重要性的突出和强调。文章提出一种方法来识别关于核电的新闻报道中所使用的新闻叙事框架,并研究框架的流行度及其情感的时序变化。具体而言,聚类分析可以根据文本的用词进行分组。如果文本中包含同样的词语,很可能也会强调同样的争议元素,因此聚类分析技术可以揭示出一组具有相似框架的文本。情感分析则是一种通过自动化的方式确定文本语气的方法。这两种技术结合在一起,为研究社会和政治问题的新闻动态提供了一个强大的工具。Burscher等人首次将这两者结合起来研究新闻框架。
为了考察聚类分析和情感分析在框架研究中的应用,文章选择了被众多文献深入讨论的“核电”议题为研究对象,以便比较聚类分析所得到的框架与之前研究发现的框架进行比较。表1是根据现有文献所整理出来的与”核能”议题相关的新闻框架。
表1 已有文献中的核能框架
核武器发展风险 放射性废物的健康和环境风险 |
核能利用的社会进步和经济发展 |
恐怖主义威胁和核事故风险 |
核能生产的经济风险,不具有成本效益 |
减少温室气体排放,防止气候变化的核能 |
核能满足能源需求,提供能源独立 |
可再生能源替代核能 |
数据和方法
数据:文章分析数据是关于核能议题的英文新闻报道,具体而言包括1992至2013年间发表在纽约时报、华盛顿邮报和卫报所有的英文报道。Burscher等人使用LexisNexis搜索引擎搜索这三个来源的文章,入选的准则包括:(1)关键词“核电”或“核能”至少在新闻报道中出现2次;(2)关键词在标题中至少出现一次。严格的限制有助于确保报道的主题是“核能”。最终有4286篇报道符合上述条件。
聚类分析:基准分析过程如下:第一,将文本分词得到一系列的词元,并删除数字和常用的英文单词。删除规则如下:出现在不到五个文本或超过40%的文本中的词元,因为这些低频词和高频词在新闻报道的不同聚类之间缺乏区别度。
第二,将得到的词元列表转化为TF-IDF文档向量,该向量同时反映了每个单词在文档中出现的次数(TF)以及每个单词在多大程度上仅出现在有限数量而不是众多的文档中(IDF)。TF-IDF加权的目的在于强化单词对文档的区分度,其中罕见的词被认为具有更大的区分度,被赋予了更高的权重。此外,文章还使用L2归一化来标准化文档向量。
第三,通过“拐点法”来选择聚类数,并使用k-means聚类分析方法对向量化的文本进行聚类。在操作上,通过使用不同数量的聚类(1-15)重复进行分析,将每个K值对应的解释方差量画成一个碎石图(图1),并根据碎石图选择7个聚类作为最终的聚类模型。
第四,在每个文档聚类中识别出具有最高TF-IDF均值的15个核心特征词来描述该文档聚类的关键新闻框架。
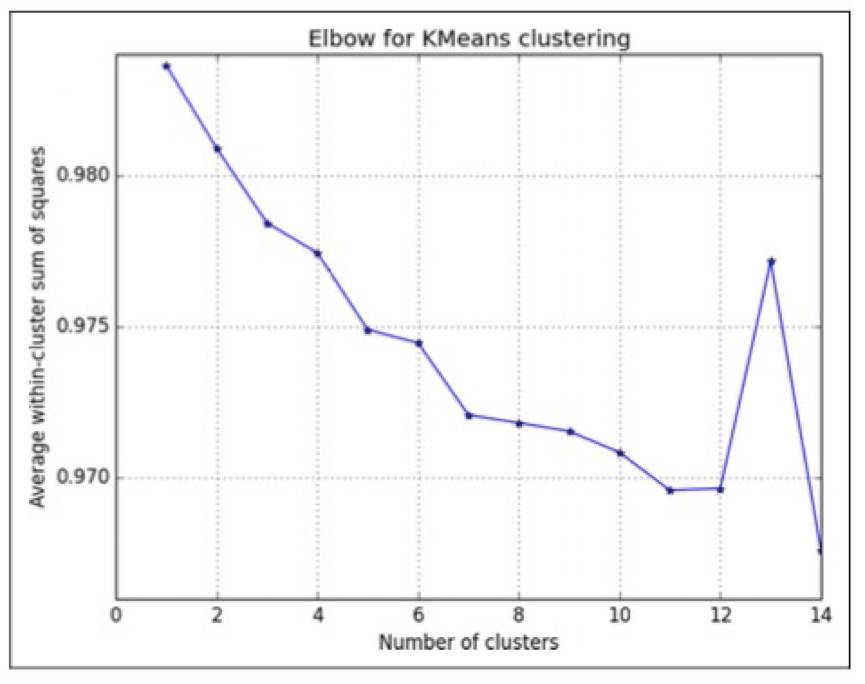
图1.基准方法中解释方差的碎石图
Burscher等人提出了一种改进的聚类分析方法来提高提炼新闻框架的效度,即在上述第一和第二步之间增加了特征选择的步骤,包括(1)删除没有出现在标题或引语中的单词,或仅使用标题和导语;(2)仅保留词性为名词、形容词、副词的单词;和(3)删除带人、组织和国家名称的实体命名词。通过比较,作者将评估基准分析方法和特征选择方法的优劣。
情感分析:运用SentiWords工具来测度每个文档聚类的语气。SentiWords是一个包含155000个单词的情感字典,每个词的情感得分在-1到1之间。使用SentiWords词典中相应的情感分数计算出每篇文章中所有带标注的单词的平均分数,该分数将反映出新闻报道的语气。
人工内容分析:文章还从每个聚类中随机抽取出若干文档进行人工编码,通过比对聚类分析结果和人工编码结果来评估自动化文本分析技术的效度。
分析结果
新闻框架的识别:文章使用了基准方法和特征选择方法对文本进行k-means聚类,并从中抽取反映每个聚类核心新闻框架的关键词(见表2和3),这些结果进一步归纳为表4的新闻框架。
表2.基准方法的聚类结果
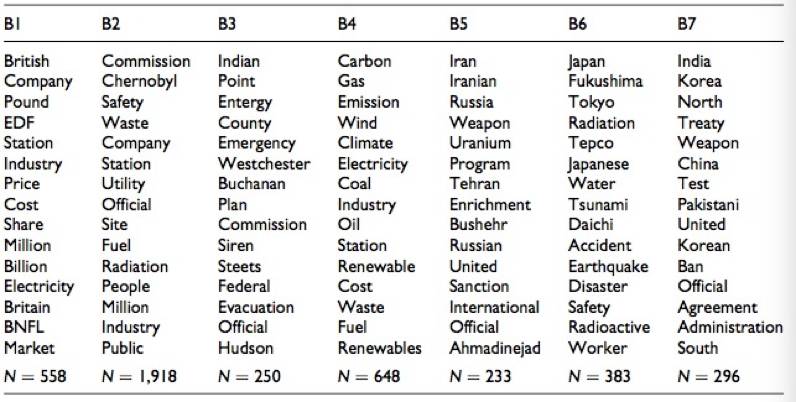
表3.选择方法的聚类结果
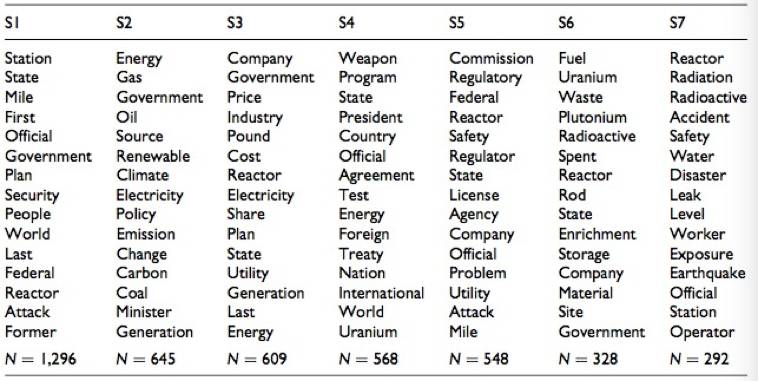
表4. 基准方法和选择方法所识别出来的新闻框架
基准方法 |
框架1 核能生产的经济方面 |
框架2 核电站、核废料、核电事故和辐射风险的安全 |
框架3 核能和核武器发展 |
框架4 核电在电力生产中的作用以及对气候变化的影响 |
框架5 核反应堆的疏散 |
选择方法 |
框架1 核电站的安全 |
框架2 核电在电力生产中的作用和对气候变化的影响 |
框架3 核能生产 |
框架4 核能和武器的发展 |
框架5 核材料和核废料的处理 |
框架6 核能事故和辐射风险 |
比较基准方法和特征选择方法的结果可以发现,基准方法所识别的多个新闻框架指向类似的内容,比如B5和B7、B2和B6的内容均比较相似。此外,B3则讨论一个具体的事件而不是新闻框架。相比之下,特征选择方法得到一个更加清晰的聚类结构(见表3):7个集类中有6个具有一致和独特的聚类中心,它们均讨论核电争议的不同要素;集类之间的内容几乎没有重叠;集类的中心包含了大量的词汇,并且没有地理、人员或组织名称,因此更易于解释。
交叉验证分析:文章从三个角度对选择方法所识别的新闻框架进行交叉验证。首先,比较手工编码的结果和聚类分析结果,并使用Krippendorrf alpha信度系数来衡量一致性的衡量标准。结果显示,基准方法的Krippendorrf apha信度系数为0.52,而选择方法的信度系数为0.71,表明特征选择方法更好。其次,对不同新闻框架的流行度的时序变化分析显示(图2),框架流行度较高的时期与历史上重要的核事故具有对应关系。最后,对不同框架的情感分析显示(图3),与风险相关的框架具有负面的情感和语气,与机会相关的框架则具有正面的情感,与现有文献一致。










