点击上方
“小白学视觉”,选择加"星标"或“置顶”
异常检测(也称为离群点检测)是检测异常实例的任务,异常实例与常规实例非常不同。这些实例称为异常或离群值,而正常实例称为内部值。
异常检测可用于多种应用,例如:
① 欺诈识别
② 检测制造中的缺陷产品
③ 数据清理——在训练另一个模型之前从数据集中去除异常值。
你可能已经注意到,一些不平衡分类的问题也经常使用异常检测算法来解决。例如,垃圾邮件检测任务可以被认为是一个分类任务(垃圾邮件比普通电子邮件少得多),但是我们可以用异常检测的方法实现这个任务。
一个相关的任务是奇异值检测(Novelty Detection)。它与异常检测的不同之处在于,假设该算法是在干净的数据集(没有异常值)上训练的。它被广泛应用于在线学习中,当需要识别一个新实例是否是一个离群值时。
另一个相关任务是密度估计。它是估计数据集生成的随机过程的概率密度函数的任务。密度估计通常用于异常检测(位于低密度区域的实例很可能是异常)和数据分析。通常使用基于密度(高斯混合模型或 DBSCAN)的聚类算法来解决。
统计方法
检测离群值最简单的方法是尝试统计方法,这是很久以前开发出来的。其中最流行的一种方法被称为离群值检测Tukey方法(或四分位数距离IQR) 。
它的本质是计算百分位数和四分位数之间的范围。位于Q1-1.5 * IQR之前和Q3 + 1.5 * IQR之后的数据点被认为是异常值。下面你可以看到一个使用人的身高数据集的例子。高度低于54.95英寸(139厘米)和高于77.75英寸(197厘米)被认为是异常值。
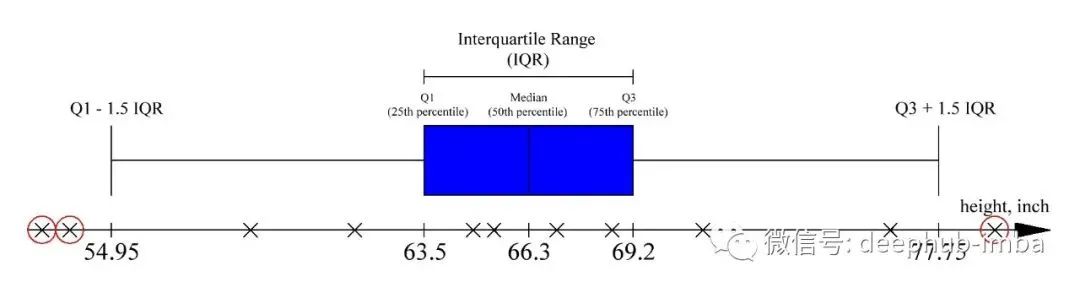
这种和其他统计方法(用于检测异常值的 z-score 方法等)通常用于数据清理。
聚类和降维算法
另一种简单、直观且通常有效的异常检测方法是使用一些聚类算法(如高斯混合模型和 DBSCAN)来解决密度估计任务。那么,任何位于低密度区域的实例都可以被认为是异常,我们只需要设置一些密度阈值。
此外,可以使用任何具有 inverse_transform() 方法的降维算法。这是因为异常的重建误差总是比正常实例的重建误差大得多。
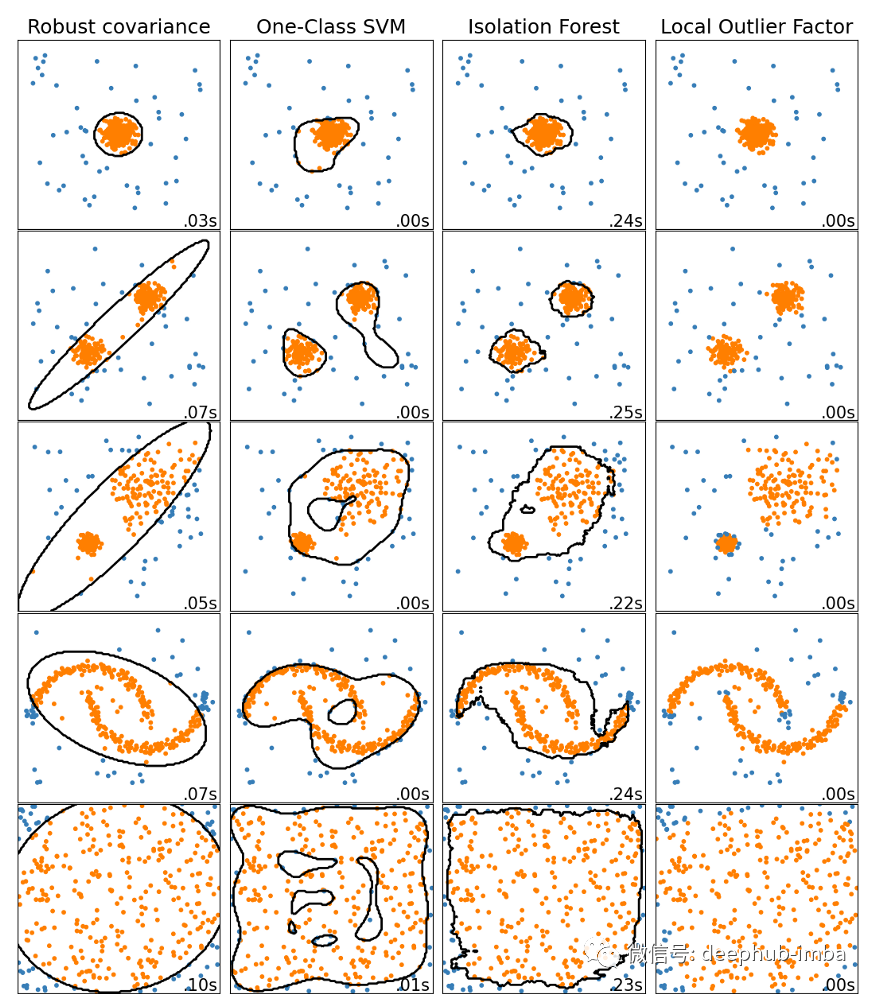
孤立森林和 SVM
一些监督学习算法也可用于异常检测,其中最流行的两种是孤立森林和 SVM。这些算法更适合奇异值检测,但通常也适用于异常检测。
孤立森林算法构建了一个随机森林,其中每个决策树都是随机生长的。每走一步,这片森林就会隔离越来越多的点,直到所有点都变得孤立。由于异常位于远离通常数据点的位置,因此它们通常比正常实例以更少的步骤被孤立。该算法对于高维数据表现良好,但需要比 SVM 更大的数据集。
SVM(在我们的例子中是一类 SVM)也广泛用于异常检测。内核化 SVM 可以构建一个有效的“限制超平面”,它将正常点与异常点分开。像任何 SVM 修改一样,它可以很好地处理高维或稀疏数据,但仅适用于中小型数据集。
局部异常因子
局部异常值因子 (LOF) 算法基于异常位于低密度区域的假设。它不只是设置密度阈值(就像我们可以用 DBSCAN 做的那样),而是将某个点的密度与其最近邻居的 k 的密度进行比较。如果这个特定点的密度比它的邻点低得多(这意味着它离它们很远),它被认为是一个异常。
该算法既可用于异常检测,也可用于奇异值检测。由于其计算简单且质量好,会被经常使用。
最小协方差行列式
最小协方差行列式(MCD 或其修改型 Fast-MCD)可用于异常值检测,尤其是在数据清理的时候。它假设内点是从单个高斯分布中生成的,而离群点不是从这个分布中生成的。由于许多数据具
有正态分布(或可以简化为正态分布),因此该算法通常表现良好。在 sklearn 中EllipticEnvelope类就是它的实现。
如何选择异常检测算法?
如果你需要清理数据集,你应该首先尝试经典的统计方法,比如 Tukey Method for Outlier Detection。如果知道数据分布是高斯分布 则可以使用Fast-MCD,。
如果你做异常检测不是为了数据清理,首先试试简单快速的LOF。如果它不能很好地工作(或者如果你出于某种原因需要分离超平面)——根据你的任务和数据集尝试其他算法:
作者:Dmytro Nikolaiev
来源:DeepHub IMBA
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目









