本文会通过 Keras 搭建一个深度卷积神经网络来识别一张图片是猫还是狗,在验证集上的准确率可以达到99.6%,建议使用显卡来运行该项目。本项目使用的 Keras 版本是1.2.2。
Dogs vs. Cats
,训练集有25000张,猫狗各占一半。测试集12500张,没有标定是猫还是狗。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
|
➜ 猫狗大战 ls train | head cat.0.jpg cat.1.jpg cat.10.jpg cat.100.jpg cat.1000.jpg cat.10000.jpg cat.10001.jpg cat.10002.jpg cat.10003.jpg cat.10004.jpg ➜ 猫狗大战 ls test | head 1.jpg 10.jpg 100.jpg 1000.jpg 10000.jpg 10001.jpg 10002.jpg 10003.jpg 10004.jpg 10005.jpg
|
下面是训练集的一部分例子:

1 2 3 4 5 6 7 8 9
|
├── test [12500 images] ├── test.zip ├── test2 │ └── test -> ../test/ ├── train [25000 images] ├── train.zip └── train2 ├── cat [12500 images] └── dog [12500 images]
|
预处理函数
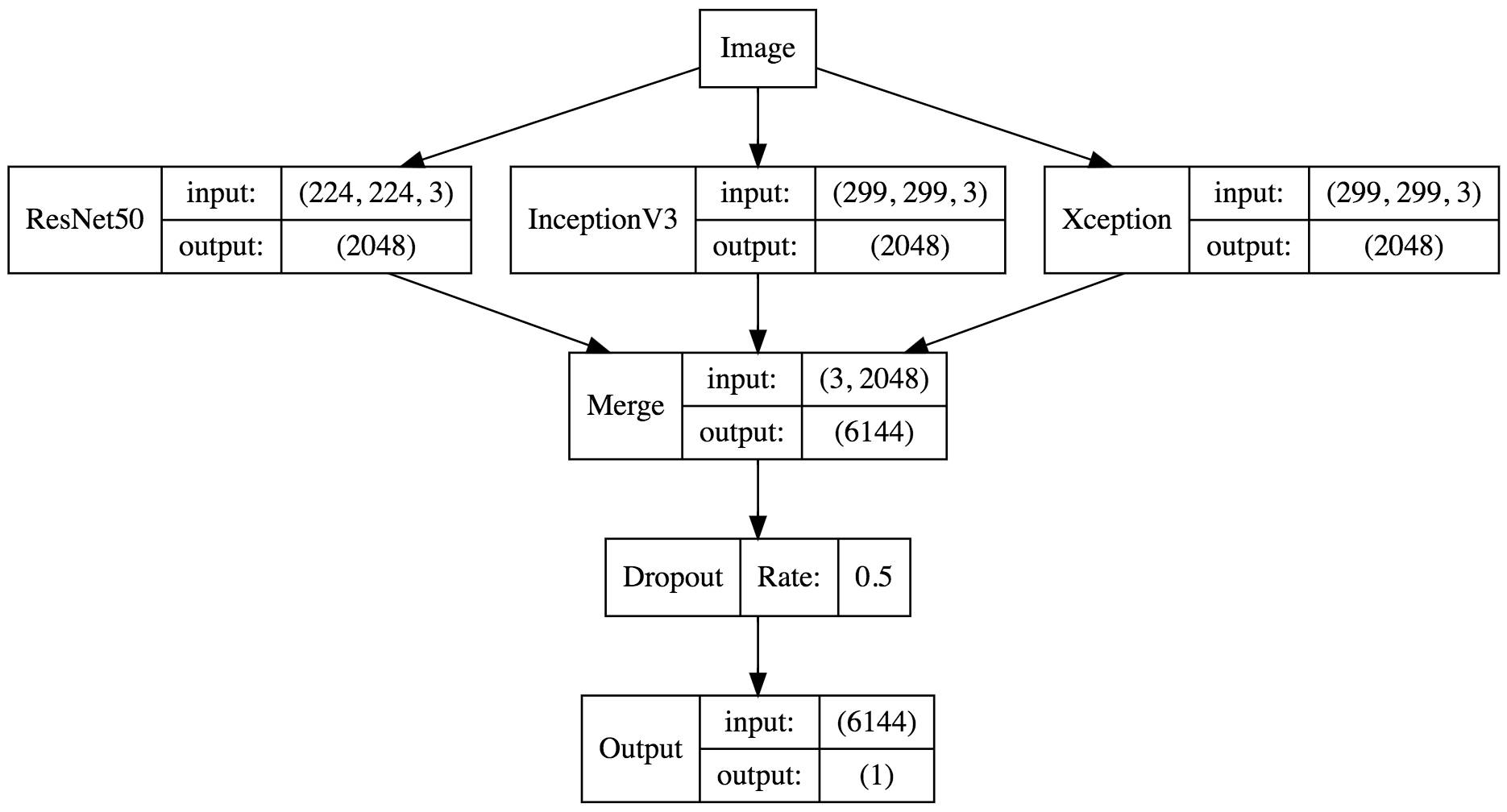
,因为 Xception 和 Inception V3 都需要将数据限定在
(-1, 1)
的范围内,然后我们利用
GlobalAveragePooling2D
将卷积层输出的每个激活图直接求平均值,不然输出的文件会非常大,且容易过拟合。然后我们定义了两个 generator,利用
model.predict_generator
函数来导出特征向量,最后我们选择了 ResNet50, Xception, Inception V3 这三个模型(如果有兴趣也可以导出 VGG 的特征向量)。每个模型导出的时间都挺长的,在 aws p2.xlarge 上大概需要用
十分钟到二十分钟
。 这三个模型都是在
ImageNet
上面预训练过的,所以每一个模型都可以说是身经百战,通过这三个老司机导出的特征向量,可以高度概括一张图片有哪些内容。
最后导出的 h5 文件包括三个 numpy 数组:
-
train (25000, 2048)
-
test (12500, 2048)
-
label (25000,)
-
如果你不想自己计算特征向量,可以直接在这里下载导出的文件
:
GitHub releases
(https://github.com/ypwhs/dogs_vs_cats/releases/tag/gap)
百度云
(https://pan.baidu.com/s/1pK7psxX#list/path=%2Fdataset%2FDogs%20vs%20Cats)
参考资料:
-
ResNet
15.12
(https://arxiv.org/abs/1512.03385)
-
Inception v3
15.12
(https://arxiv.org/abs/1512.00567)
-
Xception
16.10
(https://arxiv.org/abs/1610.02357)
-
1 2 3 4 5 6 7 8 9 10 11 12 13
|
digraph G{ node [shape=record] a[label="ResNet50|{input:|output:}|{(224, 224, 3)|(2048)}"] b[label="InceptionV3|{input:|output:}|{(299, 299, 3)|(2048)}"] c[label="Xception|{input:|output:}|{(299, 299, 3)|(2048)}"] Merge[label="Merge|{input:|output:}|{(3, 2048)|(6144)}"] Dropout[label="Dropout|Rate:|0.5"] Output[label="Output|{input:|output:}|{(6144)|(1)}"] Image -> a -> Merge Image -> b -> Merge Image -> c -> Merge Merge -> Dropout -> Output }
|