用数学模型分析策略,可以避免由于情绪波动的造成的影响,避免一些因此产生的非理性策略。从这点上来说,机器学习可以很好地避免这种主观情绪造成的非理性决策。
大多数人在炒股的时候会觉得,如果我能判断大盘涨跌,大盘涨的时候,我就买,下跌的时候,我就全卖了,等下次涨,那肯定能赚钱。那么,本篇文章就用3个模型(SVM,决策树,adaboost)来对HS300指数进行预测,记录数据的获取,清洗,模型选用,以及如何调参。
1、获取数据:
首先获取数据,这里我使用优矿的api:DataAPI.MktIdxdGet来获取历史数据。获取在fields中已定义的数据,本项目,我选择的数据有:tradeDate,交易日、closeIndex,收盘指数、highestIndex,当日最大指数,lowestIndex,当日最小指数,CHG,当日最大涨跌幅。
我们获取数据选用的是从2006年3月1日到2015年3月1日的所有交易日,一共有2127行的HS300指数数据。
2、 处理数据:
首先我把交易日设定为index,然后将预测用的交易日的前30日数据提取出来,找出前30日的最大指数,找出前30天最小指数,定义当日指数差为当日最大指数减去当日最小指数,找出前30天最大日指数差,加上之前通过api选择到的数据,作为特征值。
除去我们用作索引的交易日期,经过处理后,一共有11列数据,其中10个为特征值,一个是待处理的标签。我认为目前市场并不是完全的有效市场,少数异常值可以对预测的时候提供市场信息,所以我认为,不应当把任何值当作异常值去除。
处理完数据后,我们查看一下数据的统计描述:
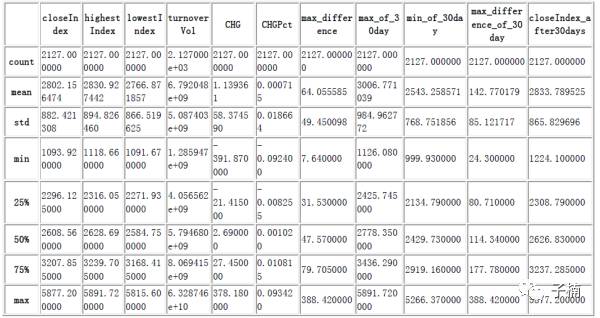
然后,我们找到预测用的30个交易日后的收盘价,用这个数字当作当前交易日需要预测的目标。设定lables表,为布尔值,如果这个预测目标大于当前交易日的收盘价,则设定为true,否则设定为False。
到这里数据集合就处理完了,待会儿可以直接切割这个集合用来做预测。
3、有效性验证:
为了验证模型的有效性,本项目采取了两个指标:
1、 模型交叉验证的score值。(这里的score值简单地计算测试机中准确预测的比率有多少。score值的范围为0~1,由于是二元分类问题,所以socre越接近1,模型表现越优秀。由于是二元分类问题,所以如果score小于等于0.5,那么可以认为模型失效。)
2、与纯随机策略对比的夏普比率(夏普比率是一个综合考虑风险和收益的计算数据,可以简单的理解为收益/风险,本模型中夏普比率采取的计算方式是(收益-基准收益)/标准差)。
首先,在训练模型的时候,对数据集进行交叉验证,获取score。以此来验证模型对于训练用数据集的准确率,如果小于等于0.5,则认为该模型对于该问题无效。如果score大于0.5,使用数据集时间点之后的数据进行回测,比对用了模型验证后,预测涨则随机选股,否则不选。对比没用模型时,纯粹随机选股的夏普比率,如果明显大于纯随即选股的夏普比率,则认为“如果大盘涨我就买,大盘跌就不买”这种思路是有效的。
4、阈值设定:
模型有效性经过验证的情况下,也就是说,“如果大盘涨我就买,大盘跌就不买”这种思路是有效的,且未经调参的模型score大于0.5的情况下。我认为经过调参后,模型的score要稳定大于0.8,才能证明该模型能够明显有效。
5、纯随机策略回测图:
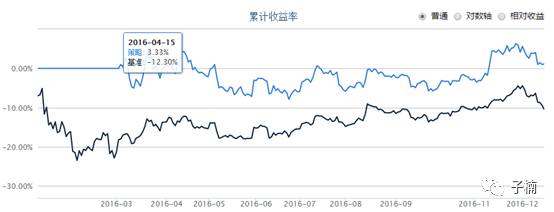
用2016年1月到12月来回测,得到下图:
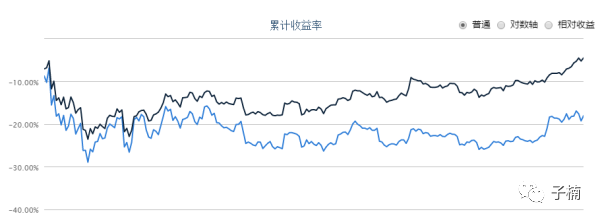
夏普指数为-0.72,我们在验证有效性时,使用该纯随机策略,只添加“如果预测1个月后上涨,则进行交易”这一个条件,其他不变,依然是随机购买。
6、SVM预测:
简要介绍:
SVM又名支持向量机,对二元分类问题表现尤其良好。某种程度上来说,SVM是把数据映射到高维空间,然后对空间进行切割,所以训练点之间间隔越大,SVM效果越好。作为一个大间隔分类器,SVM可以最小化经验误差,降低结构化风险。SVM的计算复杂度取决于其映射产生的支持向量,故不易发生维数灾难这种问题(这很重要,因为本题定义了很多特征量)。而最终结果取决于少数重要向量,所以一定程度上增减向量,不会对模型造成太大损害。
当样本数量过多时,SVM的训练时间会大幅增加,同时,SVM对多元分类问题处理存在困难。
单看指数的话,股票交易10年也不过2500个左右的交易日,所以数据量并不大。而当前研究的问题也确实是二元分类问题,所以这里首先选用SVM模型进行测试。
模型测试:
这里我们直接使用sklearn的SVM包中的分类模型SVC。在训练模型后,使用score函数,获得的预测准确率为:0.68。超过了0.5,所以可以认为该模型是初试有效的,值得进一步测试。
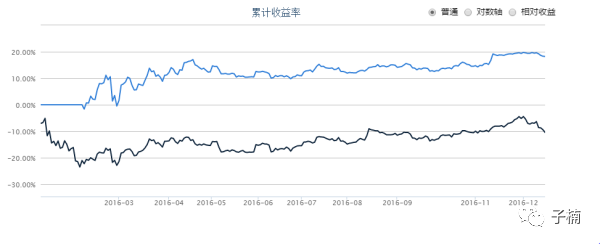
我们用2016年1月到12月来回测,得到上图,发现该模型是有效的,此时的夏普比率为0.99.,大于纯随机策略的-0.72,同时,我们的策略线(蓝线)确实明显优于HS300大盘指数(黑线)。
调整参数:
接下来,我将调整SVM的参数C,以便进一步提高SVM对于该模型的表现,观察随着C的变化,Score值的变化趋势:
我首先做了一个图,观察在C值在1~1000范围内,得到的Score值的变化:
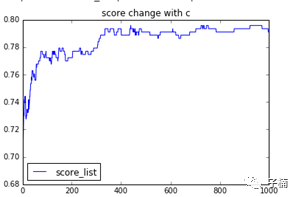
我们发现,模型表现随着C值的提高而提高,在C值为360左右的时候,表现达到了最高。
接下来调整gamma,也是相似的方法,我们观察gamma在0~10之间的变化,得到下图:
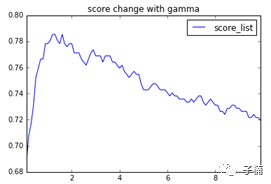
可以看出,gamma在1.8左右的时候,score表现得最好。
至于核函数,通常都是默认核函数最佳,这里由于是第一个模型,还是检验一下吧:
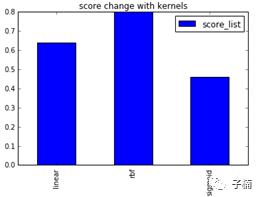
果不其然是rbf(默认的高斯核函数)是最佳的。
接下来我们用GridSearchCV来确切获得最佳的C值和gamma值:运行函数后,我们得到最佳的C值为300,最佳的gamma值为1.03。根据这两个参数,此时我们模型test后获得的score为0.76,明显高于之前的0.68。
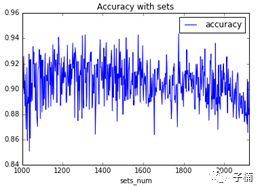
接下来通过不同的数据集(改变数据集中的数据数量)的方法测试score的方法,判断模型是否稳健,得到下图:
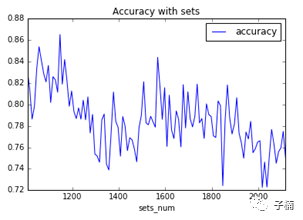
发现根据数据集的不同,准确率上下摆动,摆动幅度在0.1左右。但是始终没有低于过0.72,0.72大于0.5,所以可以认为模型一定程度上是稳健的。
但是由于0.72小于0.8,低于了我们设定的阈值,所以认为SVM模型对于该问题的解决表现不够良好。
7、决策树预测:
简要介绍:
由于决策树是归纳型算法,所以当其预测的数据集如果是人类很容易理解的信息,那么决策树可以表现良好。决策树可以清晰地处理大量数据,了解不同特征的影响重要性。这种算法在特征明确,杂音小,特别熟数据量较大时,效果较好。
决策树属于局部贪婪的算法,容易过拟合,有时无法保持全局最优,所以泛化能力较差。在股票交易中使用时,应当随时更新数据,否则有可能过拟合过去的经验,对未来的预测能力下降。
模型测试:
这里我们直接使用sklearn的tree包中的分类模型DecisionTreeClassifier。在训练模型后,使用score函数,获得的预测准确率为:0.88。超过了0.5,所以可以认为该模型是初步有效的。
我们用2016年1月到12月来回测,得到下图
发现该模型是有效的,此时的夏普比率为-0.09.大于纯随机策略的-0.72,我们的策略线(蓝线)也在HS300大盘指数(黑线)上面,所以可以认为相比于纯随机策略,模型是有效的。
调整参数:
接下来我们调整决策树的参数。首先我们调整最大深度,在0~100之间,获得下图:
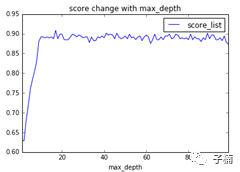
发现最大深度在15左右的时候,开始趋于稳定,在18左右的时候,模型表现最好。
然后我们调节min_samples_leaf参数,从0到10之间,获得下图:
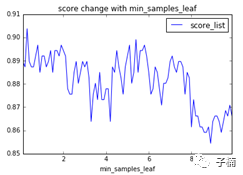
发现min_samples_leaf震荡幅度很大,总体来说,随着min_samples_leaf增加,模型score降低。所以这里我们就选用默认值1。
接下来调整参数min_samples_split,范围在0~50之间,获得下图:
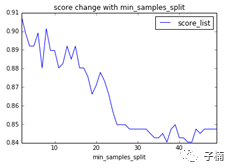
发现随着min_samples_split的增加,模型在测试集上获得的score降低。
然后调整参数min_weight_fraction_leaf,范围从0~0.5,获得下图:
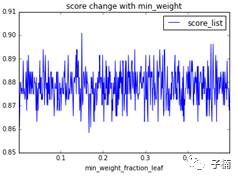
在可选范围内震荡过大,不具有明显规律,所以这时我们就选用默认值0.0。
接下来我们依靠上面选用的参数范围,使用GridSearchCV函数,选取表现出了趋势的参数max_depth和min_samples_split的最优值,我们得到的反馈为max_depth为32,min_samples_split为3.
依靠这两个参数重新进行一次在test集上的测试,这时我们得到的预测准确率为0.9,略高于之前的0.88
接下来通过不同的数据集(改变数据集中的数据数量)的方法测试score的方法,判断模型是否稳健,通过改变测试集,得到下图:
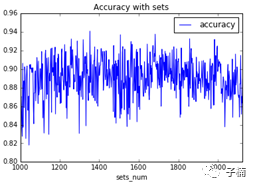
发现总体来说,模型表现在0.82~0.94之间,1000次的测试稳定高于0.8,0.8是大于0.5的,所以可以认为我们的预测模型是稳健有效的。
同时因为我们1000次的测试中,模型准确率从未低于我们设定的阈值,0.8。所以认为我们的模型对于问题的解决表现良好。
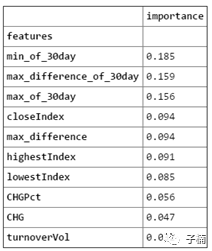
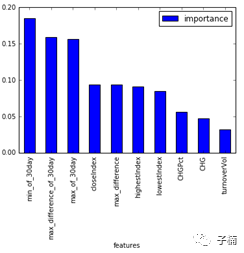
既然表现良好,那么我们就来看看哪些特征影响最大,我生成了一下特征在决策树中的重要性,得到下面得到得到下面表格与图:
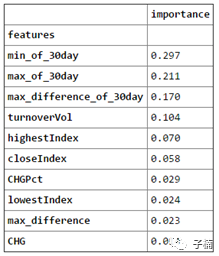
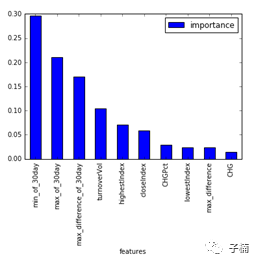
发现对于未来30天股市涨跌来说,最重要的预测指数是30天内的最高值和30天内的最低值,其次是30天内的最大日波动,这3项的重要性超过了50%。也就是说,对于未来股市涨跌的预测,决策树模型认为,股市的波动是最重要的。
8、 Adaboost预测:
简要介绍:
adaboost是一种通过训练多个不同的弱分类器,装配到一起的办法,形成一个较强的分类器的模型。它根据每个分类器上样本的准确性,来给特征分配权值,然后再把修改过权重值后的特征传入下一个分类器,依次迭代,最终融合成一个决策分类器。可以简单地把adaboost算法理解为“三个臭皮匠赛过诸葛亮”。
adaboost可以很好地对特征权重值进行筛选,一定程度排除无效的训练数据特征造成的干扰,增加关键数据的权重,可以较好的避免过拟合。
adaboost的缺点也很明显,弱分类器太少则训练结果不够好,太多则训练时间过长。
模型测试:
这里我们直接使用sklearn的ensemble包中的分类模型AdaBoostClassifier。在训练模型后,使用score函数,获得的预测准确率为:0.78。超过了0.5,所以可以认为该模型是有效的,有调参的价值。
我们用2016年1月到12月来回测,得到下图:
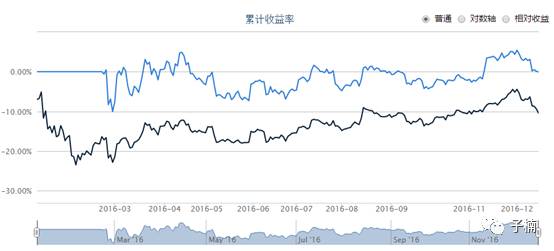
发现该模型是有效的,我们的策略线(蓝线)确实明显优于HS300大盘指数(黑线),此时的夏普比率为-0.13.大于纯随机策略的-0.72,所以可以认为相比于纯随机策略,模型是有效的。
调整参数:
接下来我们先调整adaboost的参数,首先调整装配数量n_estimators,我们选择0~200范围,发现得到下图:
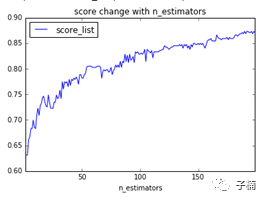
果不其然是随着装配的弱分类器数量的增加,模型表现效果越好,而且依然在增加,由于依然在增加,我们接下来比对一下200~300范围内,模型的score表
现结果:
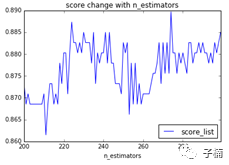 发现产生了较大的震动,那么可以认为,模型的最优n_estimators大致在这个范围之内。
发现产生了较大的震动,那么可以认为,模型的最优n_estimators大致在这个范围之内。
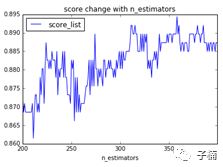
为了保险起见,我又做了一个200~400范围内的图,发现震荡依然很明显,略有提高,并且在350以后近似于稳定,此时计算起来已经相当慢了。以及此时相比于200~300的平均提高,已经没有超过自身的波动范围,可以认为没有进一步尝试更高的参数的意义。
接下来我们调整参learning_rate,在0~10的范围内,得到下图:
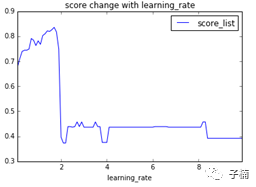
发现在1.7左右,表现最好。
综合以上两个大致范围,接下来我选用GridSearchCV在n_estimators为340时,learning_rate在1.5~2之间,寻找最优值。得到最优结果为:n_estimators=340,learning_rate = 1.53的情况下。此时预测准确率为0.91。
然后通过不同的数据集(改变数据集中的数据数量)的方法测试score的方法,判断模型是否稳健,通过改变测试集,得到下图:
确率在0.86~0.94之间波动,未低于0.84,平均在0.9左右,由于0.84大于0.5,所以模型是有效的。总体来说,模型的稳健性还不错。
同时,由于准确率的波动从未低于过我们设定的阈值0.8,所以可以认为模型表现良好,对于解决问题有积极作用。
由于我们这次装配准确率很不错,所以我又再次生成了一次特征重要性的表格与图,来看看哪些因子影响更大。
从表格与图中可以看出,这次影响最大依然是前30天的最小值,不过第二大的是30天内的最大日波动,第三大的因素才是30天内的当日最大指数。与决策树相比,前三位影响最大的因子依然是这3个。(不过与决策树相比,交易量不再是影响第四大的因素,在adaboost中,交易量成为了影响最小的因素了。)
值得注意的是,无论是在决策树模型,还是在adaboost模型中,能体现前30日的特征,在对未来30日后的涨跌预测中,起到了巨大的影响。
9、总结
通过添加了3个模型对大盘指数的预测后的随机策略,与纯随机策略的夏普指数相比,可以发现,对大盘预测之后,夏普指数是大于纯随机策略的,也就是说,预测大盘的涨跌,对于股票交易的收益提升以及风险降低,是有积极作用的。用通俗的话就是
“如果你能预测大盘涨跌后再瞎J8买,确实比纯粹的瞎J8买效果更好”
通过比较3个模型,我们发现,对于大盘的预测,SVM模型表现不够好,决策树和adaboost的表现经过调参之后,稳定大于我们设定的阈值,表现良好。
同时,在对达到了阈值的两个模型的参数比重分析中,我们发现了一个有趣的现象:“前30天的最小指数”,“30天内的最大日波动”与“30天内的最大日波动”这3个指数作为特征,对于模型预测的权重加起来达到了50%,我是这样理解的,前30日的股市波动,对股市未来30天的涨跌有巨大的影响。
10、增加样本外数据再次验证模型
不行,我一直在考虑时间序列这个问题,不写代码来验证一下睡不着。 虽说写好代码测试完都2点了,希望大家耐心看完吧。
于是这次我切割了样本外数据,通过预留最后100~228个数据用作样本外数据测试,再次查看模型效果。
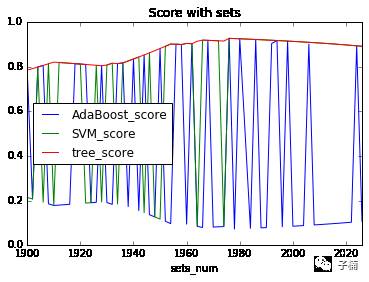
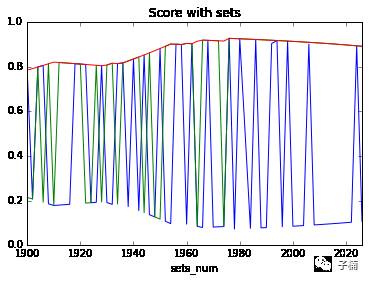
发现经过再次测试以后,adaboost和SVM的模型稳健性很差了,上下摇摆,波动不定,决策树的稳健性依然还在,但是预测样本外数据的准确率(0.8左右),明显低于预测样本内数据的准确率(0.9)
然而又有了新的问题,对于稳健性很差的那两个模型,一般而言,100个数据预测准确率为0.8,再增加一个数据,就算预测错了,预测准确率也应该只是变为0.79啊,为毛从图中看,变动的时候,直接就从0.8的准确率,变到0.2了呢?
这到底是为什么呢?目前我对这个现象的假设是这多的一个数据因为我分割的方法,它到了训练集里面,然后对模型产生了巨大的影响,恰好改变了模型之前对上涨和下跌的预测。产生这个问题的主要原因应该是我很SB的,直接根据大于或者小于算涨跌的定义标签的方式,导致分类器在涨跌那条很细的线上纠结,所以稳健性变差了。
解决方案:预留一个阈值,比方预留为5%,那么30天后的收盘价,大于今天的105%才算涨,低于今天的95%才算跌。否则设定为None。
然后我又想起来了一个问题,这个准确率是一段时间内的统计准确率,如果我减少时间周期,不是集合到一起统计准确率,而是100天,100天这样间隔统计准确率,准确率又如何呢?于是这次我得到了这样一张图:
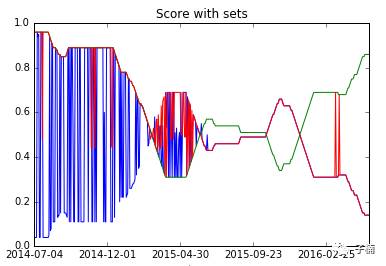
说明模型的稳健性并不够高,而且随着时间周期,模型的准确率会突变。有趣的是,不同模型依然保持一个加起来准确率为1的规律。
本文只是抛砖引玉,别妄想看完本文你就能拿去直接预测大盘了。还有一堆模型和一堆数据可以进一步使用的。
所使用的机器学习库均为
sklearn
的库,可以直接在谷歌上搜。






