在
DMP
中,对大数据的各种维度分析、分类、打标签,通过机器学习挖掘出数据中蕴藏的宝藏,是十分有技术含量的技术活儿。下面简单介绍一些常用的,对数据样本进行学习训练及回归验证的分析算法及、常规做法及核心流程。
样本训练
对原始样本数据训练可选择的算法有很多,常见的有:逻辑回归算法(
logistic regression
)、决策树算法(
decision tree
)、支持向量机算法(
support vector machine
)、神经网络算法(
neural network
)、朴素贝叶斯
(Naïve Bayes
,
NB)
分类算法等等。(实操中往往数据比算法更重要,解决问题的算法有很多,只要收集的数据质量较好,那么利用恰当的算法,往往比复杂算法对于质量较差的数据时能取得的效果更好。通常情况下数据比算法要重要。)
逻辑回归是比较常用的机器学习方法,是一种分类学习方法。使用场景大概有两个:第一用来预测,第二用来寻找
feature
(特征值)变量对
target
(目标值)变量的影响因素。通过历史数据的表现,对未来结果发生的概率进行预测。例如,我们可以将某用户购买某商品的可能性,以及某广告被用户点击的可能性的概率设置为
target
(目标值)变量,将用户的特征属性,例如性别,年龄,地域、时间、广告请求各种维度的数据等等等,设置为
feature
(特征值)变量。并根据这些历史
feature
属性对
target
(目标值)变量的影响程度,及之间的关系,以此来预测某类
feature
(特征值)变量出现时,
target
(目标值)变量出现的概率。其中
target
变量是我们希望获得的结果,
feature
变量是影响结果的潜在因素,
feature
变量可以有一个,也可以有多个。一个
feature
变量的叫做一元回归(如图
9-2
所示),超过一个
feature
变量的叫做多元回归。
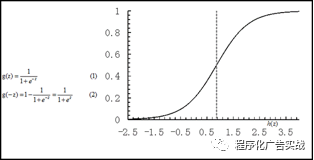
图
9‑2
逻辑回归算法示例
逻辑回归的适用性:
1)
可用于概率预测,也可用于分类。并不是所有的机器学习方法都可以做可能性概率预测。可能性预测的好处是结果有可对比性:比如我们得到不同广告被点击的可能性后,就可以列出点击可能性最大的
N
个。这样一来,哪怕得到的可能性都很高,或者可能性都很低,我们都能取出最优的
topN
。当用于分类问题时,仅需要设定一个阈值即可,可能性高于阈值是一类,低于阈值是另一类。
2)
仅能用于线性问题:只有在
feature
(特征值)和
target
(目标值)是线性关系时,才能用逻辑回归。这有两点指导意义,一方面当预先知道模型非线性时,果断不使用逻辑回归;另一方面,在使用逻辑回归时,注意选择同
target
(目标值)呈线性关系的
feature
(特征值)。
3)
各
feature
(特征值)之间不需要满足条件独立假设,但各个
feature
的贡献是独立计算的。逻辑回归不像朴素贝叶斯那样,需要满足条件独立假设(因为它没有求后验概率)。但每个
feature
的贡献是独立计算的,所以逻辑回归是不能自动组合聚类出不同的
features
而产生新
feature
的。
决策树算法是借助于树的分支结构来实现分类的。树的内部结点表示对某个属性的判断,该结点的分支是对应的判断结果;叶子结点代表一个类标。决策树算法借助于树的分支结构实现分类。
如图
9-3
所示,是一个决策树的示例:一个预测某人是否会购买电脑的决策树,利用这棵决策树,可以对数据进行分类,从根节点(年龄)开始,若某人的年龄为中年,就直接判断这个人会买电脑,若是青少年,则需要进一步判断是否是学生;若是老年则需要进一步判断其信用等级,直到叶子结点可以判定记录的类别。
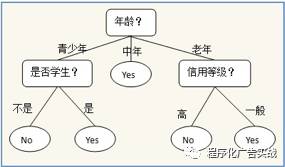
图
9‑3
决策树示例
决策树算法有一个好处,那就是它可以产生人能直接理解的规则,这是贝叶斯、神经网络等算法没有的特性;决策树的准确率也比较高,而且不需要了解背景知识就可以进行分类了,是一个非常有效的算法。决策树算法有很多变种,包括
ID3
、
C4.5
、
C5.0
、
CART
等,但其基础都是类似的。
支持向量机
(SupportVector Machine
,
SVM)
是一种常见的半监督式学习算法。支持向量机是
Corinna Cortes
和
Vapnik
等,于
1995
年首先提出的,它在解决小样本、非线性及高维模式识别中表现出很多特有的优势,并推广应用到函数拟合等等其他机器学习的领域。通过寻求结构化风险最小,来提高机器学习能力。实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,也能获得良好统计规律的目的。通俗讲就是,她是一种二类分类器,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略就是间隔最大化,最终可转化为一个凸二次规划问题的求解。
具体原理:
1)
在
n
维空间中找到一个分类超平面,将空间上的点分类。如图
9-4
所示为线性分类的例子。
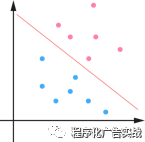
图
9‑4
线性分类示例
2)
一般而言,一个点距离超平面的远近,可以表示为分类预测的确信或准确程度。
SVM
就是要最大化这个间隔值。而在虚线上的点便叫做支持向量
Supprot Verctor
。如图
9-5
所示为
SVM
分类的示例。
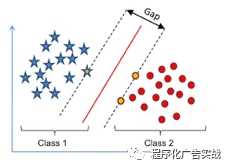
图
9‑5 SVM
分类示例
3)
实际中,我们会经常遇到线性不可分的样例,此时,我们的常规做法是,把样例特征映射到高维空间中去,如图
9-6
所示。
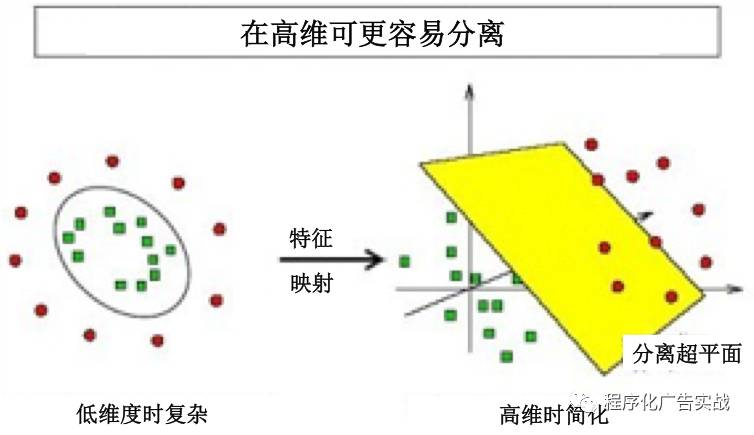
图
9‑6
高维空间映射示例
4)
线性不可分映射到高维空间,可能会导致维度高的十分严重
(
甚至无穷维的例子
)
,导致计算复杂。这个时候,常常会使用核函数,核函数的价值在于她虽然也是将特征进行从低维到高维的转换,但核函数事先在低维上进行计算,而将实质上的分类效果表现在高维上,避免了直接在高维空间中的复杂计算。
5)
很多时候,会使用松弛变量来应对数据噪音。
SVM
的优点:
1)
SVM
学习问题可表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
2)
举个例子:假设现在你是一个农场主,圈养了一批羊,但为预防狼群袭击羊群,你需要搭建一个篱笆来把羊群围起来。但是篱笆应该建在哪里呢?你很可能需要依据牛群和狼群的位置建立一个
“
分类器
”
,如图
9-7
所示,比较图中这几种(
SVM
、逻辑回归、决策树)不同的分类器,我们可以看到
SVM
提供了一个很好的解决方案。这个例子从侧面简单说明了
SVM
使用非线性分类器的优势。
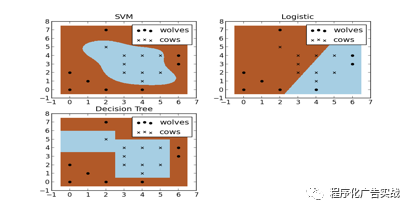
图
9‑7 SVM
、逻辑回归、决策树分类结果对比示意
BP
(
Back Propagation
)神经网络是一种按“误差逆传播算法训练”的多层前馈网络,是目前应用最广泛的神经网络模型之一。
BP
神经网络能学习和存贮大量的输入
-
输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。她的学习规则是使用梯度下降法,通过反向传播(就是一层一层往前传)来不断调整网络的权值和阈值,使网络的误差平方和最小。如图
9-8
所示,
BP
神经网络模型拓扑结构包括输入层(
input
)、隐层
(hidden layer)
和输出层
(output layer)
。利用输出后的误差来估计输出层前一层的误差,再用这层误差来估计更前一层误差,如此获取所有各层误差估计。这里的误差估计可以理解为某种偏导数,我们就是根据这种偏导数来调整各层的连接权值,再用调整后的连接权值重新计算输出误差。直到输出的误差达到符合的要求,或者迭代次数溢出设定值(有监督学习)。
BP
的传播对象就是“误差”,传播目的就是得到所有层的估计误差。她的学习本质就是:对各连接权值的动态调整。
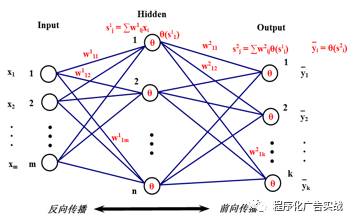
图
9‑8 BP
神经网络模型拓扑结构示意
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。分类问题往往采用经验性方法构造映射规则,即一般情况下的分类问题是缺少足够的信息,来构造
100%
正确的映射规则的,而是通过对经验数据的学习,从而实现一定概率意义上正确的分类,因此所训练出的分类器,并不一定能将每个待分类项,准确映射到其分类中,分类器的质量与分类器构造方法、待分类数据的特性、以及训练样本数量等等诸多因素有关。
贝叶斯分类的基础:贝叶斯定理,这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知
P(A|B)
的情况下如何求得
P(B|A)
。这里先解释什么是条件概率:
P(A|B)
表示事件
B
已经发生的前提下,事件
A
发生的概率,叫做事件
B
发生下事件
A
的条件概率。其基本求解公式详细见公式
9-1
:
公式
9‑1
求解公式
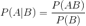
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出
P(A|B)
,
P(B|A)
则很难直接得出,但我们更关心
P(B|A)
,贝叶斯定理就为我们打通了从
P(A|B)
获得
P(B|A)
的道路。贝叶斯定理见公式
9-2
:
公式
9‑2
贝叶斯定理
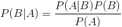
朴素贝叶斯分类是一种十分简单的分类算法,朴素贝叶斯的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。打个比方,如果你在街上看到一个黑人,让你猜他哪里来的,你十有八九猜非洲。为什么呢?因为黑人中非洲人的比率最高,当然人家也可能是美洲人或亚洲人,但在没有其它可用信息下,我们会选择条件概率最大的类别,这就是朴素贝叶斯的思想基础。整个朴素贝叶斯分类分为三个阶段:
(一)第一阶段:准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当的划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
(二)第二阶段:分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率,及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性计算阶段,可由程序自动计算完成。
(三)第三阶段:应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,可由程序完成。
下篇我们将继续介绍:回归验证
(转载请注明出处:微信订阅号:ad_automation)
文字表现力有限,欢迎参加
《5.28线下大课堂》
面对面为您答疑解惑讲透您关心的问题。
相关推荐阅读:
《2016合集目录【程序化广告实战】》





