选自Medium
作者:Alfredo Canziani等人
机器之心编译
参与:黄小天、吴攀
随着深度神经网络技术的发展,新型的网络架构也在不断涌现。普渡大学 e-Lab 的三位研究者 Alfredo Canziani、Abishek Chaurasia 和 Eugenio Culurciello 近日在 Medium 上发文阐述了一类新型的深度神经网络,其在视频分析上具有无监督学习 、分割、场景解析、定位、时空表征、视频预测、表征预测、在线学习等能力,并且还在很多方面优于当前大热的生成对抗网络(GAN)。
新一代深度神经网络正在涌现。它们演变自前馈模型,之前我们曾作过详细分析,参阅机器之心文章
《重磅 | 神经网络架构演进史:全面回顾从LeNet5到ENet十余种架构(附论文)》
或更新版本:https://medium.com/towards-data-science/neural-network-architectures-156e5bad51ba
这种新型的神经网络从 LeNet5 / AlexNet 及其变体的初始前馈模型进化而来,并且包含有比 ResNet / Inception 更复杂的旁路方案。由于这些前馈神经网络把图像压缩并编码为更小的表征向量,其也被称为编码器。
新一代神经网络有两个重要的新特征:
太棒了!但是这一额外的复杂性能给我们带来什么?
它证明了传统的前馈神经网络有很多局限性:
1 - 不能精确定位:
由于较高层的下采样和空间分辨率的损失,特征/目标/类别的定位受到限制。
2 - 不能进行场景推理:
由于把图像压缩为短表征代码,它们失去了关于图像构成以及图像或者场景各个部分的空间排列的信息。
3 - 具有时间的不稳定性:
由于它们使用静止图像进行训练,所以不能学习目标在空间中运动时平滑的时空转化。它们可以识别一些图像中(但不是全部)目标所属的类型,并且对于对抗性的噪音和扰动非常敏感。
4 - 不能预测:
由于它们使用时间信息,前馈神经网络在每一帧提供一个新的表征代码,这只基于当前输入,但是并不预测下几帧中将会发生什么(注意:有一些例外,它们不在视频上进行训练)
为了克服这些局限,我们需要新一代神经网络,以将已学习的表征投射回输入图像空间,并且可在图像的时间连贯的序列上训练:我们需要在视频上进行训练。
以下是新一代神经网络所具有的高级特征:
无监督学习 - 它们可在视频上进行预训练,以预测未来的帧或者表征,因此需要更少的标注数据来训练并执行某些任务。
-
分割 - 分割一张图像中的不同目标
-
场景解析 - 其在分割之后,如果数据集有每一像素的目标标签,用于自动驾驶和增强现实
-
定位 - 在分割和完美的目标边界之后,所有的场景解析和分割网络都可以做到此
-
时空表征 - 使用视频进行训练,而不仅仅是静态图像,了解时间概念和时间关系
-
视频预测 - 一些网络被设计用来预测视频中的未来帧
-
表征预测 - 一些网络可以预测视频中未来帧的表征
-
在线学习能力 - 通过监测预测与真实未来帧或表征之间的错误信号
现在让我们了解一下这些新网络的细节和实现:
生成性梯网络(Generative ladder networks)
这些模型使用一个编码器和一个解码器对以把图像分割为不同的部分与目标。实例有: ENet、SegNet、Unet、DenseNet、梯网络以及更多:
-
ENet:https://arxiv.org/abs/1606.02147
-
SegNet:https://arxiv.org/abs/1511.00561
-
Unet:https://arxiv.org/abs/1505.04597
-
DenseNet:https://arxiv.org/abs/1611.09326
-
梯网络:https://arxiv.org/abs/1507.02672
下面是一个典型的 3 层模型:
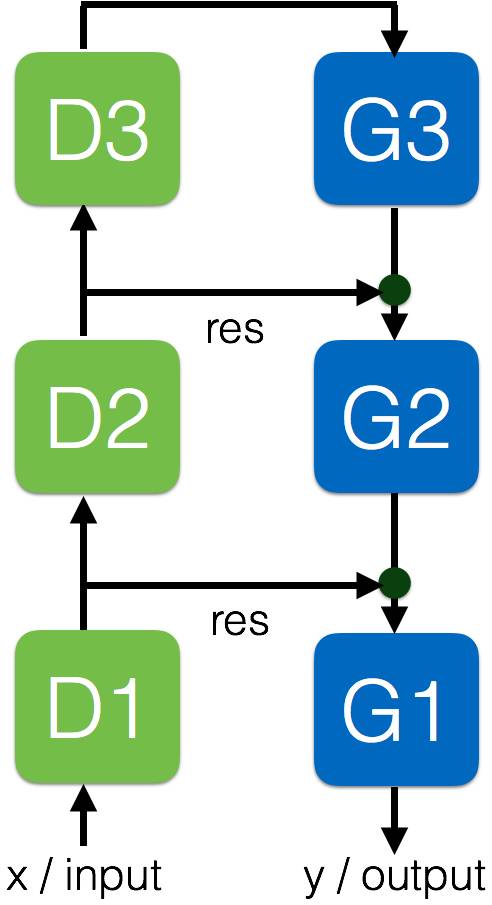
D 模块是标准的前馈层。G 模块是生成性模块,它和标准的前馈层相似,但具有去卷积和上采样。它们同样使用残差类型的连接
「
res
」
以把每一编码层的表征与解码层的表征相连。这迫使生成层的表征被前馈表征模块化,从而具有更强的能力去定位,把场景解析为目标和部分。
「
x
」
是输入图像,
「
y
」
是同一时间步的输出分割。
这些网络可以执行分割、场景解析、精确定位,但是不能在时域中进行操作,且没有过去帧的记忆。
最近每一层的编码器到解码器旁路帮助这些网络获得了当前最佳的性能。
递归和生成性梯网络(Recursive and generative ladder networks)
它是最新的深度神经网络之一,把递归添加进了生成性梯网络,从而形成了递归性和生成性梯网络(REGEL)。REGEL 是迄今为止最为复杂的深度神经网络之一,至少在图像分析领域是这样。
下面是一个我们正使用的 REGEL 的 3 层模型:
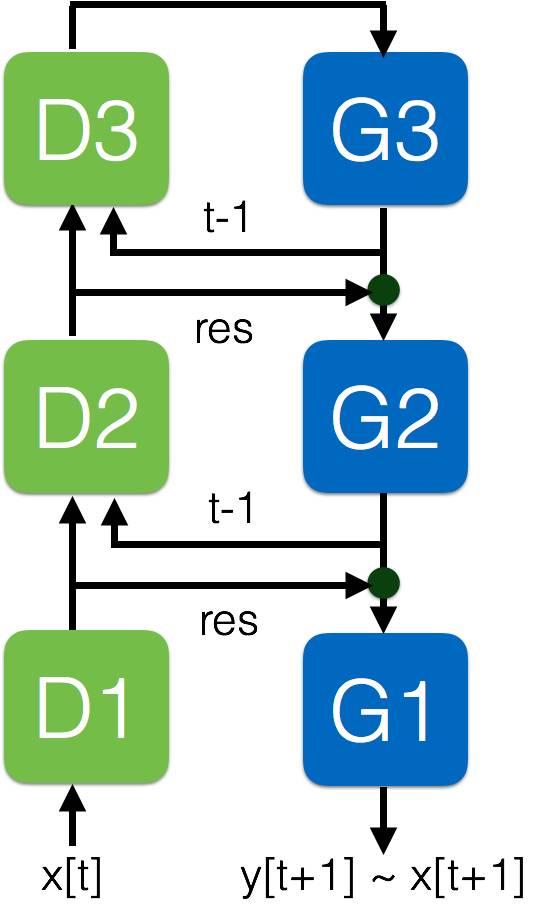
D 和 G 模块实际上与上述的生成性梯网络中的模块相同。该网络把来自每一个 G 模块的循环路径
「
t-1
」
添加到了同一层的每一个 D 模块之中。
该网络采用视频中一系列的帧作为输入 x[t],并在每一时间步预测视频 y[t+1] 的下一帧, y[t+1] 接近于 x[t+1],如果预测是精确的。
由于该网络可以度量预测与真实的下一帧之间的误差,它知道什么时候可以或者不可以预测输入。如果不可以,它可以激活增量学习,这是前馈神经网络做不到的。因此该网络本质上就可以执行在线学习。
我们认为这是机器学习的一个非常重要的特性,这是预测神经网络的一种天赋。没有这种特性,网络就不能提供真实的预测置信度信号,而且不能执行有效的增量学习。
这些网络仍在研究之中。我们的建议是:继续关注它们!
预测编码网络(predictive coding network)——第一部分
递归生成网络(recursive generative network)是一种可能的预测模型。预测编码计算神经科学模型(predictive coding computational neuroscience model)可作为其替代,能够提供预测能力并被做成层次化的深度神经网络。
这里给出了一个 2 层模型的示意:
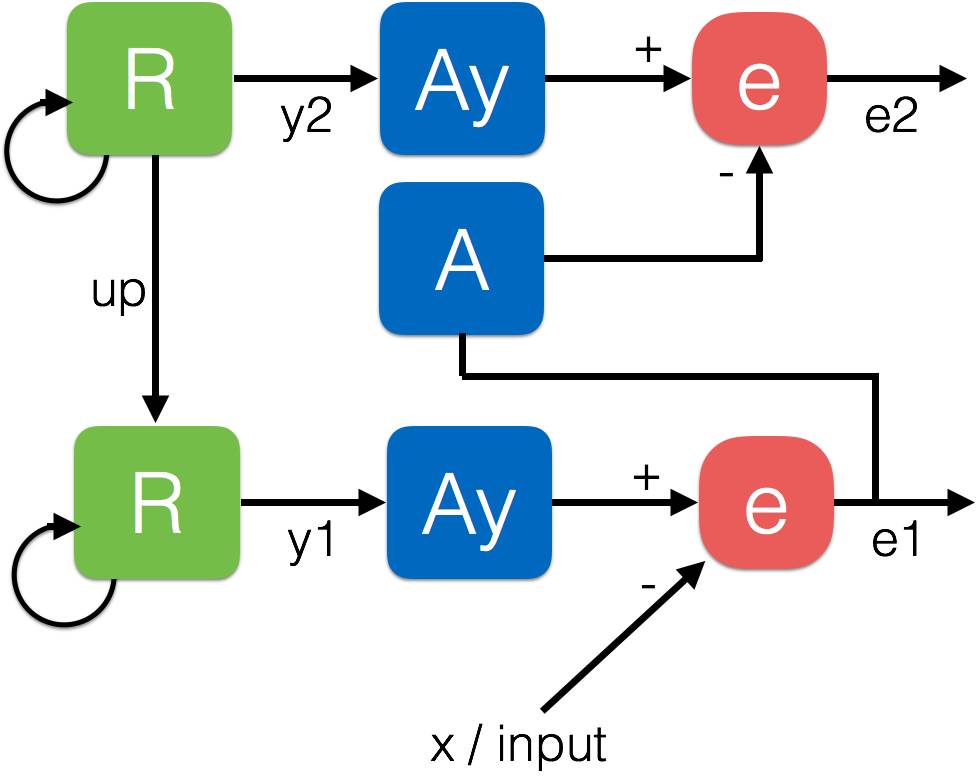
Rao 和 Ballard 在其 Nature Neuroscience 论文《Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects》中的模型和 Friston 的实现论文《Canonical microcircuits for predictive coding》都是计算 A 模块(类似于上述梯网络中的 D 模块)和 R/Ay 模块(类似于上述梯网络中的 G 模块)之间每一层的误差 e。这个误差 e 表示了该网络在每一层预测表征的能力。然后误差 e 被作为输入发送给下一层。R 是一个卷积 RNN/LSTM 模块,而 Ay 类似于 A 模块。R 和 Ay 可以被结合为一个单一的循环模块。在第一层中,x 是输入帧。
这个模型的问题是该网络非常不同于标准的前馈神经网络。这些预测网络并不会在更高层面上创造一个结合了更低层的特征的层次表征,而是会计算之前的层的残差误差(residual errors)的表征。
因此,它会让人想起残差前馈网络(residual feed-forward network),但在实际中,强迫这些网络向前传播误差并不能让它们在更高层学习到有效的层次表征。因此,它们不能基于更上层的表征来有效地执行其它任务,例如分类、分割、动作识别。要明确这些限制,还需要更多的实验。
该模型已经被 Bill Lotter 和 David Cox 实现,参考 PredNet:https://coxlab.github.io/prednet/
预测编码网络——第二部分
Spratling 预测编码模型是将表征 y 投射到更上层,而非像之前的 Friston 模型那样投射误差 e。这使得该网络与层次化前馈深度神经网络更兼容,并且还避免了学习到更上层的误差的矩(moments of errors)。
这里给出了一个 2 层模型的示意:
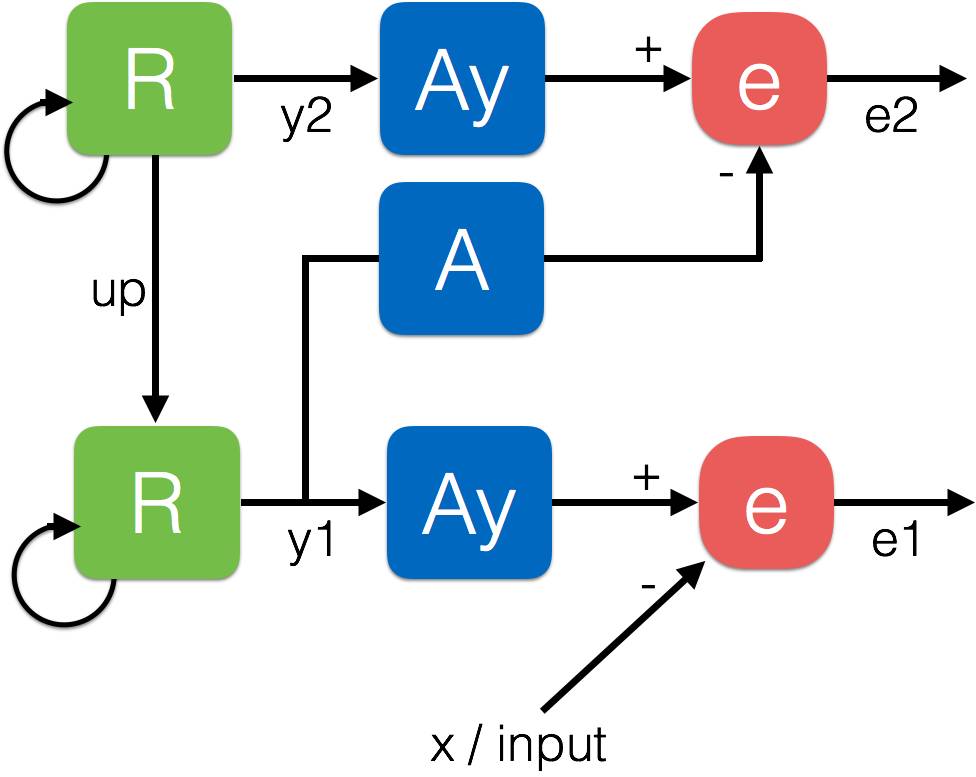
本质上讲,该模型可以被重写和简化成我们前面提到的循环生成梯模型。这是因为 R 和 Ay 可以被结合成一个单个循环模块。
与生成对抗网络的关系
生成对抗网络(GAN)是现在一种非常流行的模型,其可以从数据分布中学习生成样本。这里提出的新网络模型优于 GAN,原因如下:
-
它们并不通过最小最大博弈(minimax game)的方式来训练,而是直接面向一个有用的任务训练的,所以其鉴别器和生成器都是直接有用的。
-
它们可以学习创造有用的输入表征,同时也可以生成新的输入。
-
它们可以学习基于输入来生成目标数据。
-
生成器网络和鉴别器网络是紧密绑定的,消除了收敛问题。
-
其生成器可以提供具有近乎完美真实感的照片样本(见下),相比而言,GAN 的结果并不太好。

REGEL 网络预测能力的示例——左图:当前帧;中图:下一个真实帧;预测的下一帧
其它模型
REGEL 这样的模型让人想起像素循环网络(Pixel recurrent networks)及其诸多实现(比如 PixelCNN、Pixel CNN++、WaveNet)。这些模型的目标是建模输入数据的分布。(
「
我们的目标是估计自然图像的分布,并将其用于可跟踪地计算数据的似然并生成新的数据。
」
)它们仅专注于生成新的具有真实感的数据样本,但还没有表现出为真实世界任务学习表征的能力。而且这些模型的推理速度也非常慢。
-
像素循环网络:https://arxiv.org/abs/1601.06759
-
PixelCNN:https://arxiv.org/abs/1606.05328
-
Pixel CNN++:https://openreview.net/pdf?id=BJrFC6ceg
-
WaveNet:https://deepmind.com/blog/wavenet-generative-model-raw-audio/
-
其它:http://ruotianluo.github.io/2017/01/11/pixelcnn-wavenet/
总结
这些新网络仍然还在研究和评估之中。比如最近的 PredNet 论文(https://arxiv.org/abs/1605.08104 )就给出了预测编码网络和梯网络的一个比较,其中 PredNet 在一些任务上表现更优。PredNet 可被用于使用高层表征来执行定向的面部分类。另外,其还可以在一个数据集中预测转向角,但大多还是使用该网络第一层的简单动作过滤器。该任务并不需要对特征进行层次分解。

原文链接:https://medium.com/towards-data-science/a-new-kind-of-deep-neural-networks-749bcde19108
点击阅读原文,报名参与机器之心 GMIS 2017
↓↓↓






