正文

DIGITS 是什么?
7 月 8 日,英伟达深度学习学院 DLI 线下训练营即将来到深圳,主题是图像分类、目标检测与图像分割的零基础开发入门。
虽然是全球范围内顶级的 AI 培训项目,但 DLI 进入中国的时间太晚,中文网页也才上线没多久,导致国内开发者只知英伟达的显卡,却不知道英伟达有线上、线下的 AI 技术培训。此前我社曾撰文介绍过 DLI,详情见
今天推送的第二条
。

闲话少说,本期深圳 DLI 训练营主要用到
DIGITS 和 TensorFlow
两个工具。TensorFlow 大家都知道,不必介绍。但对 DIGITS 就很陌生了,它是什么呢?
DIGITS 是英伟达为普及深度学习开发的图形化操作界面,简单易用,旨在帮助初学者跨越入门障碍,迅速上手。因此,DLI 的入门培训均要求学员从 DIGITS 起步。
说白了, DIGITS 就是一个新手工具。但由于 DLI 刚刚进入中国,关于 DIGITS 的教程和信息并不充足,为初学者带来额外的信息障碍。 因此,雷锋网对这篇英伟达博客发布的官方教程进行了编译。该教程指导读者用 DIGITS 5 和 Caffe 进行图像分割,它脱胎于 DLI 的线上实验室(online labs)培训课。后者收费且只用英文授课,并不对非会员开放。但大家能从这篇教程对其了解一个大概。
更重要的,7 月 8 日深圳的 DLI 线下训练营,三场主要培训分别是
用 DIGITS 进行图像分类,用 DIGITS 目标检测,以及用 TensorFlow 进行图像分割(了解详情请点此)
。虽然前两场的内容与本教程并不一致,最后一场的难度比本文高出许多,而且用的是 TensorFlow 而非 Caffe,但与 DLI 的付费培训在内容上已十分接近。
感谢三位童鞋朱婷、彭艳蕾与马晓培编译本文花费的心血。
教程:用 DIGITS 5 进行图像分割
去年底,英伟达发布了 DIGITS 5,为 DIGITS 又增添了新功能,其中两个是这篇教程非常感兴趣的,分别是:
1. 完全集成的分割工作流,它能让你创建图像分割数据集,并将分割网络的输出结果可视化;
2. DIGITS 模型商店,它是一个公共的在线资源库,你可以从中下载网络说明以及预训练的模型。
本文将探索图像分割这一主题。对于 SYNTHIA 数据集里合成图像中的汽车、行人、路标以及各种其他城市物体,我将用 DIGITS 5 训练神经网络进行识别和定位 。
图 1 是预览,这就是你将通过本教程学着做的东西:

图 1: 使用 DIGITS 5.0 作图像分割的示例可视化。这交替显示了输入图像、 FCN-Alexnet 预测结果的叠加、 FCN-Alexnet 预测结果与 ground truth 的叠加。
从图像分类到图像分割
假设你想为自动驾驶车设计图像理解软件。你可能已经听说过 Alexnet [1], GoogLeNet [2], VGG-16 [3] 以及其他的图像分类神经网络架构,所以你可能从这些着手。假如有一个小狗的照片,图像分类,就是一个让计算机告诉你图中的旺就是旺的过程。
图像分类模型的输出是一个离散的概率分布; 其值介于 0、1 之间,用来表示每个训练类别的概率。图 2 是在 DIGITS 中使用 Alexnet 对一张猫的图像做分类的示例。其结果非常好:要知道 Alexnet 是在 1000 不同类别的对象上训练的,包括动物、乐器、蔬菜、交通工具等等。令人震撼的是,在 99% 的置信区间内,机器能够将图像主题正确归类为猫。即便是我己,恐怕也不过如此,无法进一步分辨出这只猫是埃及猫、花斑猫还是虎斑猫。
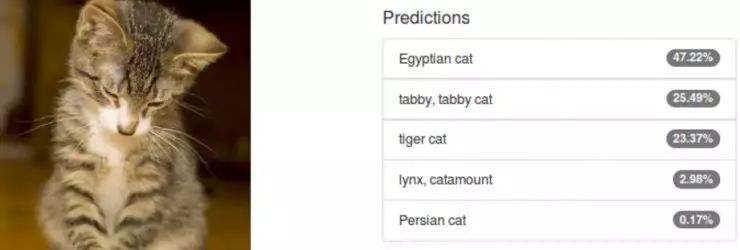
图 2:来自 PASCAL VOC 数据集的猫图像的 Alexnet 分类。
如果一张图片里同时有猫和狗,对它进行分类会发生什么?从常识来看,你可能会相信神经网络对我们最喜欢的这两种宠物图像分类时,将其归为每类的概率相同。我们来试试:图 3 所示是结果。在预测结果中有猫和狗的混合,但是 AlexNet 并没有给出 50/50 分的希望。在中间图像中,在前 5 名的预测中事实上并没有猫。这真令人失望,但是从另一方面来看,AlexNet 是在 120 万张图像的 “小” 世界上训练的,在这些图像中只有一个对象,所以不能想当然的期望在多个对象存在的情况下执行良好。
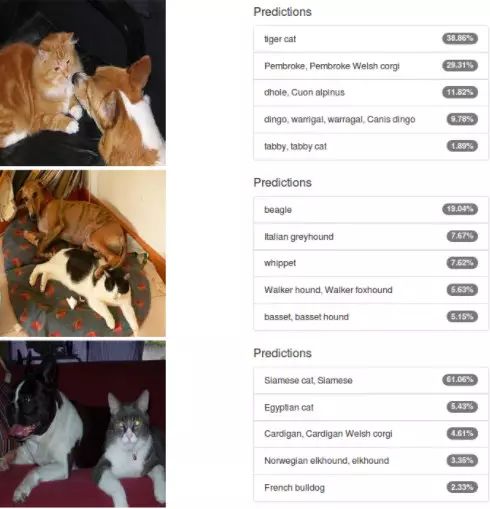
图 3 来自 PASCAL VOC 数据集的猫狗图像的 Alexnet 分类。
分类网络的另一个限制是它们不能分辨出图像中对象的位置。这是可以理解的,因为它们不是被训练来做这个的。尽管如此,这却是计算机视觉的一个主要障碍:如果一辆自动驾驶车不能检测到道路的位置,它没法行驶很远!
图像分割解决了部分弊端。它并不是预测整幅图像的单一概率分布,而是将图像分成多块,预测每块的概率分布。最常见的情况是,图像被划分到像素级别,对每个像素做分类:对于图像中的每个像素,训练网络来预测指定像素的类别。这使得网络不仅能鉴别出每张图像中多个主题类别,还能检测出对象的位置。图像分割通常生成标签图像,该图像的大小与输入图像的大小相等,其像素按照各类类标用颜色编码。图 4 所示是示例,在一幅图像中分割出 4 个不同类别:桌子、椅子、沙发和盆栽。

图 4:来自 PASCAL VOC 数据集的图像分割示例(白色区域标记未定义的像素,例如对象轮廓和未分类对象)。
在图像分割的进一步细化中,即实例感知图像分割(IAIS),神经网络要学习识别图像中每个对象的轮廓。这在应用中特别有用,它一定能识别出单个类别每一次的出现,甚至在各类之间界限不清晰时也是如此。例如在图 5 中:中间的图像是图像分割类标,而最右边图像是 IAIS 类标(注意颜色编码是如何唯一地识别每个人的)。我不会深入讨论 IAIS 的主题,我将重点讨论实例分割;但是我很鼓励你看看 Facebook 在 IAIS 上的 SharpMask 工作。
 图 5: 图像分割(中)vs. 实例感知图像分割(右)。图像来自 PASCAL VOC 数据集。
图 5: 图像分割(中)vs. 实例感知图像分割(右)。图像来自 PASCAL VOC 数据集。
让我们看一下如何设计能分割图像的网络。
从 CNN 到 FCN
前一节对图像分类模型和图像分割模型作了区分,前者对每个图像做概率分布预测,后者对每个像素做概率分布预测。原则上,这听起来很相似,你可能觉得它们会使用相同的技术。毕竟,仅仅是问题的空间维度得到了增加。在本文中,我将向你展示,仅仅一些小小的调整就足够将一个分类神经网络变成一个语义分割神经网络。我将使用在这篇论文( this paper)[4] 里面世的技术(我将之称为 FCN 论文)。
开始之前,先说一些术语:我将典型的分类网络,例如 Alexnet,称为卷积神经网络(CNN)。这有点滥用,毕竟卷积神经网络除了图像分类之外还有很多其他用途,但这是一种常见的近似。
CNN 中,常见的做法是将网络分为两部分:前一部分做特征提取,数据通过若干个卷积层逐步提取到越来越复杂、抽象的特征。卷积层之间通常有非线性转移函数和池化层。每个卷积层可被看作是一系列图像滤波器,它们在特定模式下触发高响应。例如,图 6 所示是来自 Alexnet 第一个卷积层的滤波器的表达以及在虚拟图像,包括简单的形状上的激活结果(输出)(有趣的是,AlexNet 将图像分类成一个挂钟!)这些滤波器触发了在比如水平和垂直边缘和角这些形状上的高响应。例如,看下左下角的滤波器,它看起来像黑白相间的竖条纹。现在看一下相应的激活结果以及在垂直线上的高响应。类似地,在右边的下一个滤波器在斜线上显示了高响应。网络更深的卷积层将能够在更加复杂的形状上例如多边形上触发高响应,最后学习检测纹理和各种各样自然对象的组成成分。在卷积层中,每个卷积输出都是通过通过将每个滤波器应用到输入中的窗口上(也叫感受野)计算而来,按该层的步长滑动窗口直到遍历整个输入为止。感受野尺寸大小与滤波器相同。如图 7 所示,是卷积计算的说明示例。注意,输入窗口跨越了输入图像的所有通道。
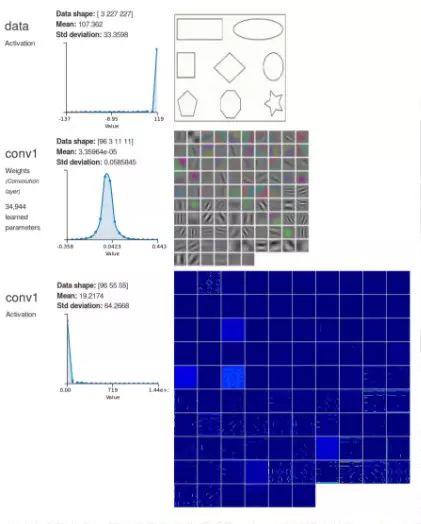
图 6:Alexnet conv1 l 层在 DIGITS 中的表现。从上到下:数据层(输入);conv1 层滤波器的可视化;conv1 层的激活结果(输出)。
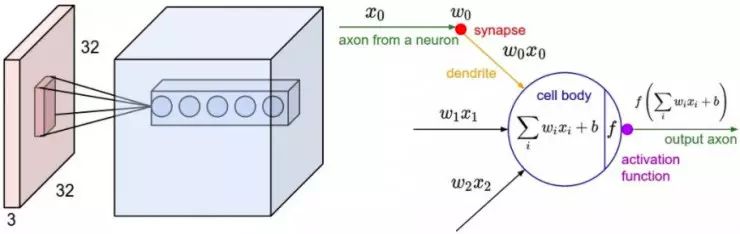
图 7:左:红色表示的输入量示例和第一个卷积层的神经元体示例。卷积层中的每个神经元只与输入空间中的局部区域相连接,但是却连接了全部深度(即所有的颜色通道)。注意,沿深度方向有多个神经元(示例中是 5 个),所有都连接着输入的相同区域;右:神经元仍然是计算其权值与输入的点乘,然后是非线性函数,但是它们的连接现在被限制在局部空间上。来源:斯坦福大学 CS231 课程。









