编辑:弗格森
【新智元导读】 本论文中,作者研究了如何从数据中直接学习卷积架构,并将这些架构应用到ImageNet的分类任务上。这种架构在ImageNet的 top-1任务上的准确率达到82.3%,top-5 准确率达96.0%。在top-1上,与人类创造的最佳架构相比,准确率提升了0.8%,同时,FLOPS少了90亿。

在计算机视觉的发展历史上,ImageNet中的图像分类任务一直是一个重要的基准。Krizhevsky等人使用卷积架构来参与ImageNet 图像分类代表了深度学习最重要的突破之一。
通过架构工程的调整,基于卷积神经网络的方法在这一基准上不断获得突破,取得了令人印象深刻的进步。
本论文中,作者研究了如何从数据中直接学习卷积架构,并将这些架构应用到ImageNet的分类任务上。
作者在论文中写道:“我们之所以聚焦在ImageNet分类任务上,是因为从解决这一任务的网络中派生出来的特征在计算机视觉领域非常重要。例如,ImageNet分类任务上做得很好的网络中的特征,当被迁移到其他的视觉任务中时,也可以获得最佳的性能,虽然这些地方通常没有足够的标签数据。”
该论文的方法源于最近提出的神经架构搜索(NAS)框架,其使用策略梯度算法来优化架构配置。考虑到数据集的大小,直接在ImageNet数据集上运行NAS在计算上是昂贵的。因此,作者使用NAS在较小的CIFAR-10数据集上搜索良好的架构,并将架构迁移到ImageNet。通过设计搜索空间来实现这种可迁移性,使得架构的复杂性独立于网络的深度和输入图像的大小。更具体地说,搜索空间中的所有卷积网络由具有相同结构但权重不同的卷积单元组成。因此,可以搜索最佳卷积架构缩小到寻找最佳的单元结构。以这种方式搜索卷积单元要快得多,并且架构本身更可能推广到其他问题。特别地,这种方法显着加速了使用CIFAR-10(例如,4周至4天)的最佳架构的搜索,并学习了成功传输到ImageNet的架构。
该研究取得的主要结果是,CIFAR-10上发现的最佳架构在ImageNet分类上实现了最高精确度,并且无需太多修改。在ImageNet上,所学习的最好的单元组成的架构获得了最佳的性能。在ImageNet的 top-1任务上的准确率达到82.3%,top-5 准确率达96.0%。在top-1上,与人类创造的最佳架构相比,准确率提升了0.8%,同时,FLOPS少了90亿。
在CIFAR-10本身,该架构具有96.59%的精度,比具有可比性能的架构的参数更少。
通过简单地改变卷积单元的数量和配置单元中的滤波器数量,可以创建具有不同计算需求的卷积架构。特别是,可以生成一个模型系列,在相同或更小的计算预算下实现优于所有人造发明模型的精度。值得注意的是,最小版本的学习模型在ImageNet上 top1上实现了74.0%的精度,比以前针对移动和嵌入式视觉任务的工程设计好了3.1%。
开发性能最佳的图像分类模型通常需要大量的架构工程和调参。本论文中,我们尝试使用神经架构搜索(Neural Architecture Search)来减少架构工程的数量,可以在一个小型的数据中学习到架构开发模块,并将其转移到大型的数据集上
这种方法与在一个递归网络中学习一个递归单元(CELL)的结构类似。在我们的实验中,我们在CIFAR-10数据集上搜索最佳的卷积单元,然后通过将更多的相同单元堆栈在一起,把它们运用到ImageNet数据集上。虽然单元并不是直接在ImageNet上学习到的,但是,所学习的最好的单元组成的架构还是获得了最佳的性能。在ImageNet的 top-1任务上的准确率达到82.3%,top-5 准确率达96.0%。在top-1上,与人类创造的最佳架构相比,准确率提升了0.8%,同时,FLOPS少了90亿。
这种单元还可以进一步缩小两个维度:从最佳的单元中学习到的一个更小的网络架构,在top-1任务上准确率达到74%,比移动(手机)平台上的相同规模的最佳模型准确率高3.1%。

论文的四名作者:Barret Zoph, Vijay Vasudevan,Jonathon Shlens,Quoc V. Le .
论文地址:https://arxiv.org/pdf/1707.07012.pdf
方法:神经架构搜索(Neural Architecture Search)
该研究扩展了Zoph和Le在2016年提出的框架——神经架构搜索(Neural Architecture Search)。
NAS的训练过程可以简单地总结如下:一个递归设计网络作为控制器,在各种架构中对子网络进行抽样,子网络经过训练,能够做到聚敛,以在一个留存验证数据集中获得最佳的准确率。在这一过程中获得的准确度,被用于升级控制器,这样一来,控制器将会在不断的重复中生成更好的架构。控制器去权重使用一个策略梯度的方法进行调整。
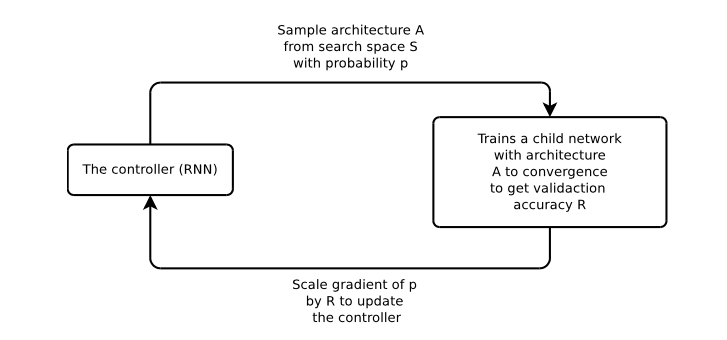
图1:Neural Architecture Search 概述。一个控制器的RNN从搜索空间S,利用概率P来预测架构A。一个带有架构A的子网络被训练用于聚敛所获得的准确率R。通过R来扩展p的梯度,进而升级RNN控制器。
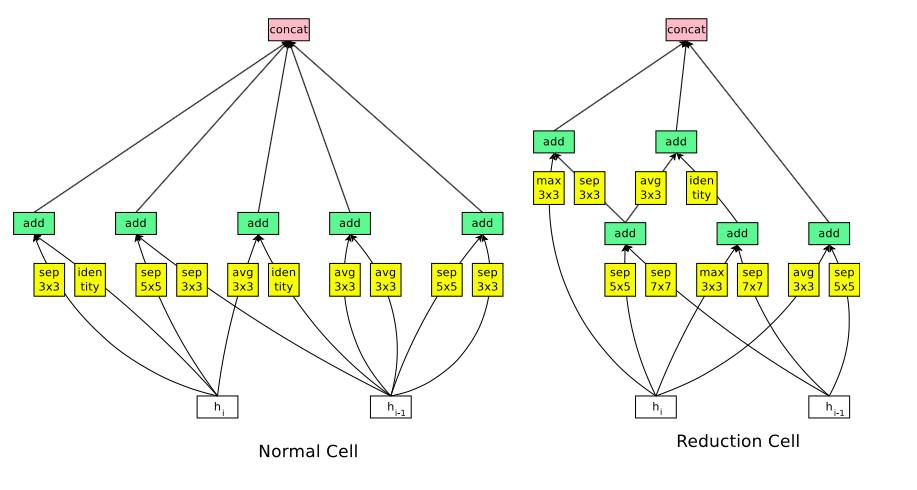
图2:图像分类的可扩展架构包含了两个重复的主题,叫Normal Cell 和 Reduction Cell。这一分类方法强调了CIFAR-1O和ImageNet的模型架构。Normal Cell 在Reduction Cell ,也就是N中的堆栈的次数选择,是可以变化的。
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~









