这是一个可以检测并规范化文本中的URL地址的Java库。
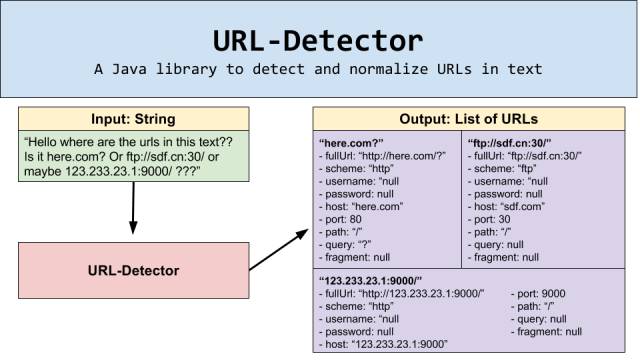
今天,我们很高兴做一个分享,因为我所在的 Linkedin 公司 开源了我们做的一个ULR探测工具:URL-Detector Java 库。
Linkedin 在每一秒钟,会检查数十万数量级的 URLs 。这些 URL 可能是来自恶意软件或者钓鱼网站的,为了保障我们每一个用户有一个安全的浏览体验,同时防止潜在的危险,我们后端的内容检查服务程序会检查所有由用户产生的内容。为了在这每秒数十万规模的用户内容上检测不良的 URL,我们要有能够在快速此规模上提取文本中URL 的方法。
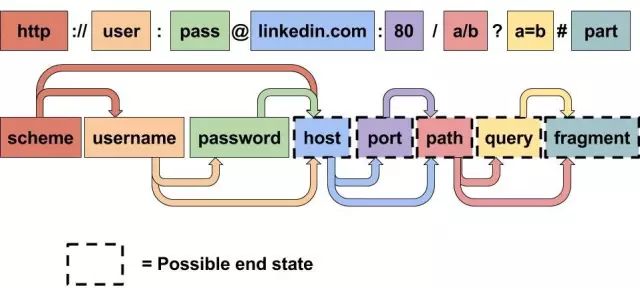
我们的服务器中的 URL地址有两种形式:
如果发送过来的是单一的 URL,我们可以通过我们的内容检查服务直接验证;
如果发送过来的是大块的文本内容,我们会先通过我们的URL探测器 ,经过搜索算法来验证这个文本是否有潜在危险的URL地址;
在我介绍URL探测器是如何工作的和它所能提供给的功能之前,让我们先来了解一下我们做这个项目的动机。
我们的目标是:检测出尽可能多的恶意链接,但是我们不希望紧紧局限于检测在 RFC 1738 中定义的URL地址,而是希望可以检测出任何能够在真正的浏览器地址栏中输入并且可以访问到的URL地址。因为,一个浏览器的地址栏中对 URL 的定义比起 在 RFC 1738 定义的来说,是非常松散的。同时,很多浏览器有不同的行为,所以,我们要找到一种URL文本规则能够被大部分流行的浏览器解析,它不是像RFC中定义语法那样简单。
最初,我们开始第一种解决方案,基于正则表达式。它可以帮我们检测到许多潜在的网址,其中有不少却是真的有潜在危险的,但是其中也有不少是没有的,而且有许多有危险的地址被遗漏了。用这种方式,为了抓取更多的地址这是一个反复匹配的过程,这可能出现一些不状况,比如,一个简单URL匹配的正则:
Regex: (ftp|http|https)://(w+:{0,1}w*@)?(S+)(:[0-9]+)?(/|/([w#!:.?+=&%@!-/]))?
然后,如果你想检测到不包含 scheme 的 URL,对应修改正则如下,这是其中一个的例子说明浏览器的地址栏可以解析的地址,但是却不符合 RFC 规范。
Regex: (ftp|http|https)://(w+:{0,1}w*@)?(S+)(:[0-9]+)?(/|/([w#!:.?+=&%@!-/]))?
经过各种浏览器和多场景的兼容,我们终于得到最后的正则:
Regex: ((((f|ht)tps?:)?//)?([a-zA-Z0-9!#$%&'*+-/=?^_`{|}~]+(:[^ @:]+)?@)?((([a-zA-Z0-9\-]{1,255}|xn--
[a-zA-Z0-9\-]+)\.)+(xn--[a-zA-Z0-9\-]+|[a-zA-Z]{2,6}|\d{1,3})|localhost|(%[0-9a-fA-F]{2})+|[0-9]+) (:[0-9]{1,5})?([/\?][^ \s/]*)*)
正如你所看到的,每一个兼容或者一个新的场景带来的小的逻辑分支,就对应至少增加几个字符的正则表达式长度。你可以在 这里 看到这种情况究竟有多复杂(注意:一些类似的 URL 匹配的的正则表达式 长度竟然超过了5500字符)。我们发现许多通过这种方式检测到的 URL 虽然是科学的 ,但是却也给我们带来了困扰。因为,我们越是频繁的变动正则,我们发现会有对应更多的误报 URL 。我们要是不优化这些正则,我们就发现我们遗漏的 URL 还很多。
因为我们发现太多的错误的匹配,我们采取了减少匹配数量的方法。编辑原始的复杂的正则表达式语句让我们引入了更多错误。因此,我们需要多正则表达式。下面的例子是我们其中一个正则表达式,用来排除“localhost”和“由数字和点组成的IPv4地址”。
Blacklisted Regex: ^((\d+(\.\d+){0,2})|(\d+(\.\d+){4,})|localhost)$
这样做的结果是,当解析大文本的时候,将耗费很长的时间,有些一次解析甚至是秒级别的。但是,我们的需要每秒处理数十万数量级的的 URL,这么耗时的这个方案明显是不可行的。同时,我们还发现正则表达式有一个缺点,就是:匹配易,处理分析难、维护难。就这样,我们的 URL探测器诞生了。
为了取代使用正则表达式,我们手工打造了一个有限状态机来解析出在文本中的URL。 有限状态机(你可以在这里了解更多信息)是由一组状态组成,状态之间可以由输入事件来触发状态转换。在这种请求下,输入事件就是我们在文本中正在解析的字符。