随着Splunk越来越被大家熟知和认可,现在市面上也不断涌各种同类产品,作为大数据搜索界的翘楚Splunk和ElasticSearch,绝对值得我们去学习,探索和使用,因此为了造福Splunk的铁粉和新粉们,小编特邀了Splunk的资深架构师,江湖人称“陶指导”的陶刚为大家就架构,功能,产品线,概念等方面将Splunk和ElasticSearch做了一下全方位的对比,希望能够给大家在制定大数据搜索方案的时候有所帮助。
陶刚在Splunk上海担任资深架构师,负责数据采集和云平台产品的技术架构。 拥有丰富的企业级产品的开发经验,对数据科学,数据可视化和机器学习等领域有着浓厚的兴趣。同时是足球和炉石传说的狂热爱好者,也是大圣庞卡足球队的当家球霸和炉石传说俱乐部最受追捧的明星会长。
本文就架构,功能,产品线,概念等方面就ElasticSearch和Splunk做了一下全方位的对比,希望能够大家在制定大数据搜索方案的时候有所帮助。
简介
ElasticSearch (1)(2)是一个基于Lucene的开源搜索服务。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ELK是ElasticSearch,Logstash,Kibana的缩写,分别提供搜索,数据接入和可视化功能,构成了Elastic的应用栈。
Splunk 是大数据领域第一家在纳斯达克上市公司,Splunk提供一个机器数据的引擎。使用 Splunk 可收集、索引和利用所有应用程序、服务器和设备(物理、虚拟和云中)生成的快速移动型计算机数据 。从一个位置搜索并分析所有实时和历史数据。 使用 Splunk 处理计算机数据,可让您在几分钟内(而不是几个小时或几天)解决问题和调查安全事件。监视您的端对端基础结构,避免服务性能降低或中断。以较低成本满足合规性要求。关联并分析跨越多个系统的复杂事件。获取新层次的运营可见性以及 IT 和业务智能。
根据最新的数据库引擎排名显示,Elastic,Solr和Splunk分别占据了数据库搜索引擎的前三位。
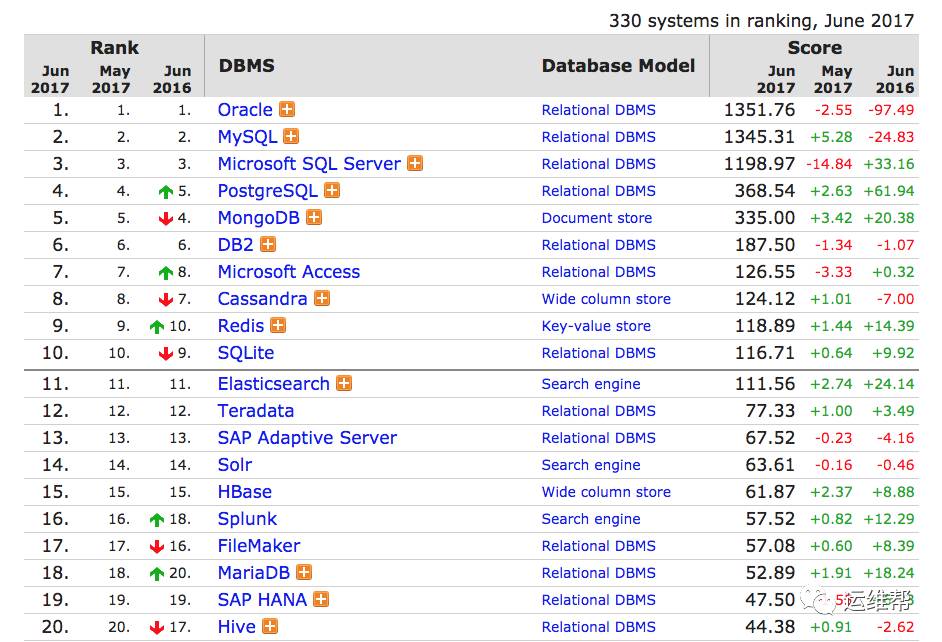
从趋势上来看,Elastic和Splunk上升明显,Elastic更是表现出了非常强劲的势头。
基本概念
Elastic
准实时(NRT)
Elasticsearch是一个准实时性的搜索平台,从数据索引到数据可以被搜索存在一定的时延。
索引(Index)
索引是有共同特性的文档的集合,索引有自己的名字,可以对索引执行搜索,更新,删除等操作。
类型(Type)
每个索引可以包含一个或者多个类型,类型可以看作一个索引数据的逻辑分组,通常我们会把拥有相同字段的文档定义为同一个类型。
文档(Document)
文档是索引信息的基本单元。Elastic中文档表现为JSON对象,文档物理存贮在索引中,并需要被制定一个类型。因为表现为JSON, 很自然的,文档是由一个个的字段(Feilds)组成,每个字段是一个名值对(Name Value Pair)
评分(score)
Elastic是基于Lucene构建的,所以搜索的结果会有一个打分。来评价搜索结果和查询的相关性。
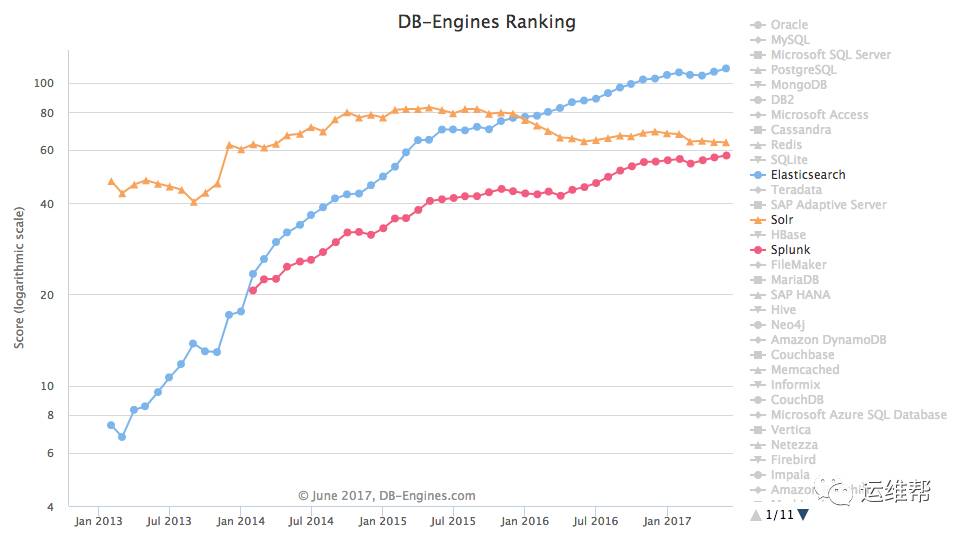
下图是一个Elastic的搜索在Kibana中看到的例子,原始的数据是一个简单的日志文件:
我们通过logstash索引到Elasticsearch后,就可以搜索了。
Splunk
实时性
Splunk同样是准实时的,Splunk的实时搜索(Realtime Search)可以提供不间断的搜索结果的数据流。
事件(Event)
对应于Elastic的文档,Splunk的数据索引的基本单元是事件,每一个事件包含了一组值,字段,时间戳。Splunk的事件可以是一段文本,一个配置文件,一段日志或者JSON对象。
字段(Fields)
字段是可以被搜索的名值对,不同的事件可能拥有不同的字段。Splunk支持索引时(index time)和搜索时(search time)的字段抽取(fields extraction)
索引(Indexes)
类似Elastic的索引,所有的事件物理存储在索引上,可以把索引理解为一个数据库的表。
知识对象(Knowledge Object)
Splunk的知识对象提供对数据进一步的解释,分类,增强等功能,包括:字段(fields),字段抽取(fields extraction),事件类型(event type),事务(transaction),查找(lookups),标签(tags),别名(aliases),数据模型(data model)等等。
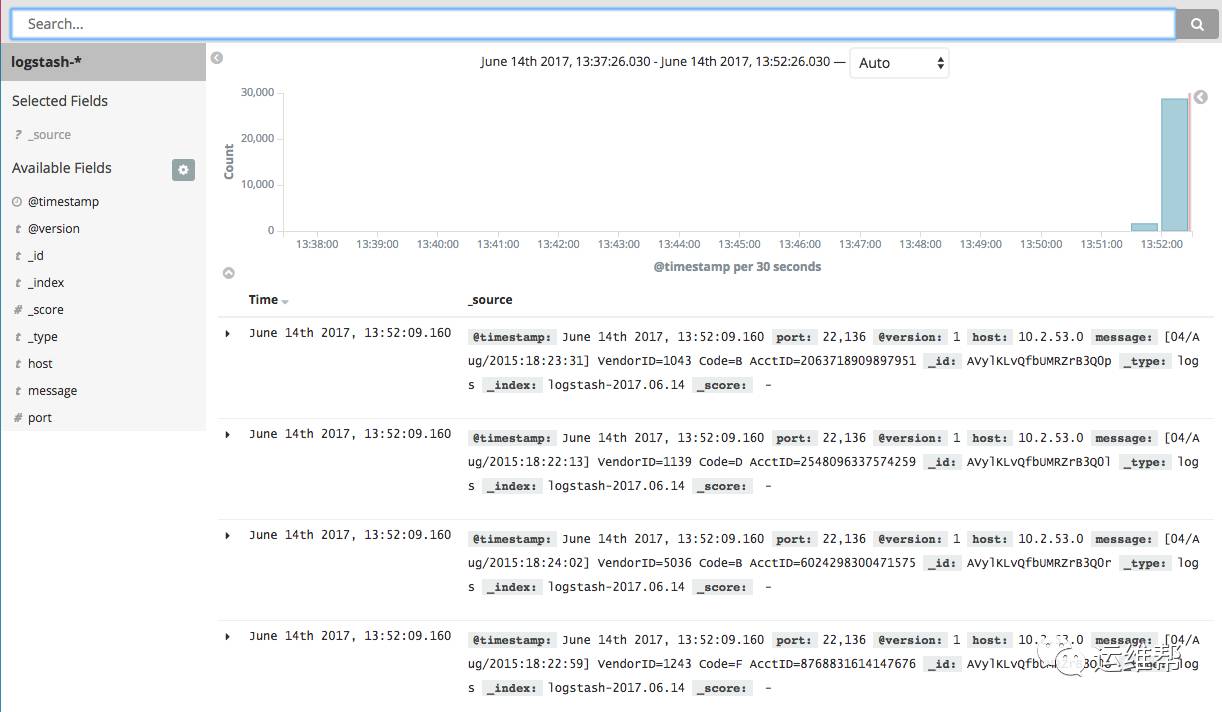
下图是一个Splunk的搜索在Splunk客户端看到的和前一个例子同样的日志数据的搜索结果。
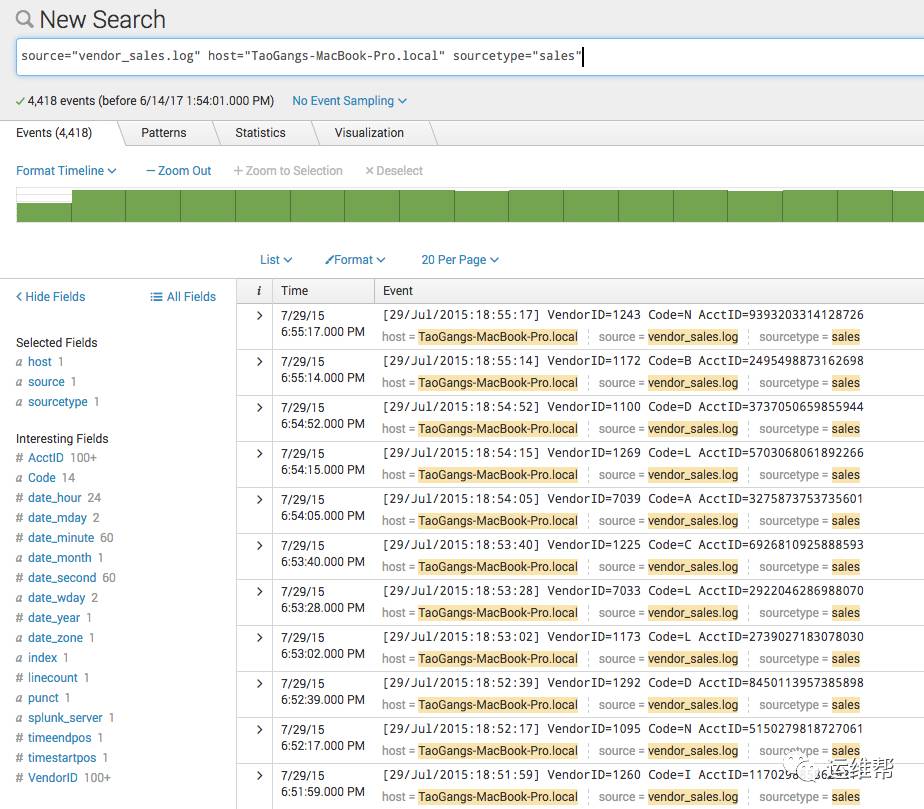
从基本概念上来看,Elasticsearch和Splunk基本一致。从例子中我们可以看到很多的共性,事件/文档,时间戳,字段,搜索,时间轴图等等。其中有几个主要的差别:
Elastic不支持搜索时的字段抽取,也就是说Elastic的文档中的所有字段在索引时已经固定了,而Splunk支持在搜索时,动态的抽取新的字段
Elastic的搜索是基于评分机制的,搜索的结果有一个打分,而Splunk没有对搜索结果评分
Splunk的知识对象可以提供对数据更高级,更灵活的管理能力。
用户接口
ElasticSearch提供REST API来进行
Elasticsearch 本身并没有提供任何UI的功能,搜索可以用Kibana,但是没有管理UI还是让人不爽的,好在开源的好处就是会有很多的开发者来构建缺失的功能:
ElasticHQ
cerebro (推荐,界面干净,我喜欢)
dejavu
另一选择就是安装X-Pack,这个是要收费的。
Splunk作为企业软件,管理及访问接口比较丰富,除了REST API 和命令行接口,Splunk的UI非常友好易用,基本上所有的功能都能通过集成的UI来使用。同时提供以下接口
功能
数据接入和获取
Elastic栈使用Logstash和Beats来进行数据的消化和获取。
Logstash用jruby实现,有点像一个数据管道,把输入的数据进行处理,变形,过滤,然后输出到其它地方。Logstash 设计了自己的 DSL,包括有区域,注释,数据类型(布尔值,字符串,数值,数组,哈希),条件判断,字段引用等。
Logstash的数据管道包含三个步骤,Input,Filter和Output,每一步都可以通过plugin来扩展。另外Input和Output还支持配置Codecs,完成对输入输出数据的编解码工作。
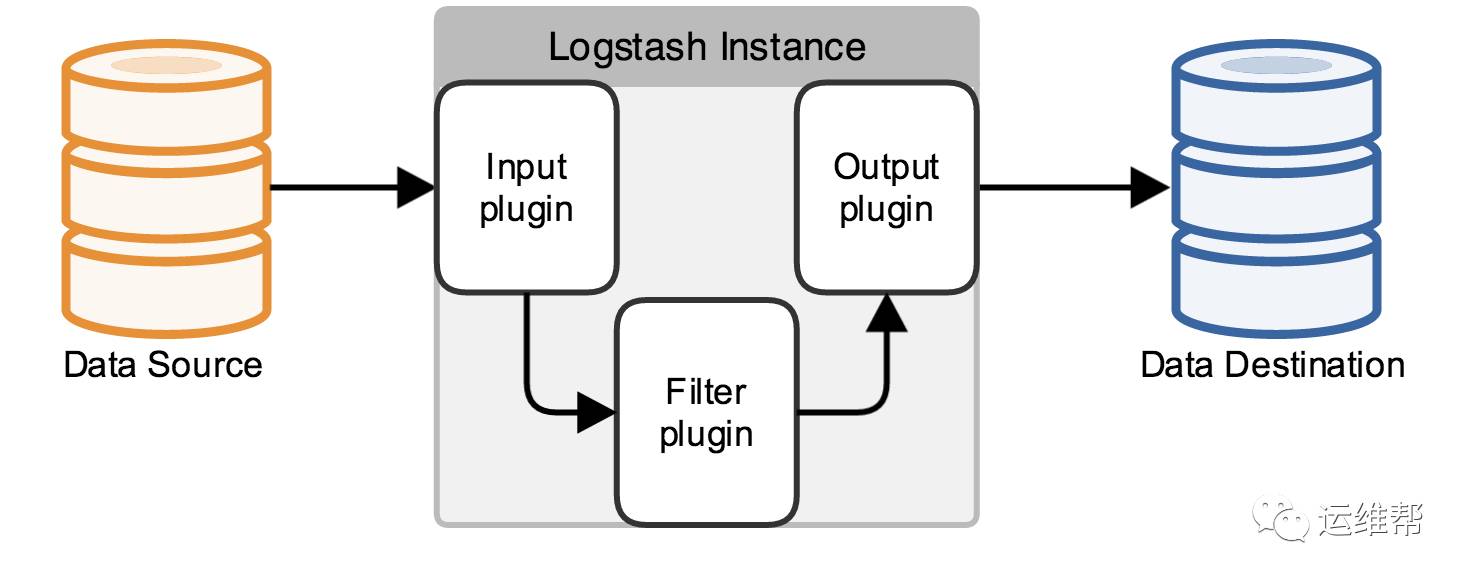
Logstash支持的常见的Input包含File,syslog,beats等。Filter中主要完成数据的变形处理,可以增删改字段,加标签,等等。作为一个开源软件,Output不仅仅支持ElasticSearch,还可以和许多其它软件集成和目标,Output可以是文件,graphite,数据库,Nagios,S3,Hadoop等。
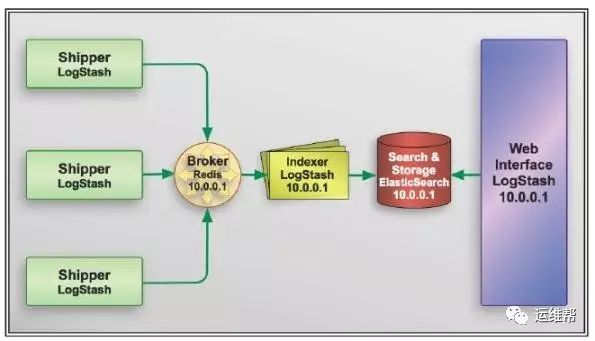
在实际运用中,logstash 进程会被分为两个不同的角色。运行在应用服务器上的,尽量减轻运行压力,只做读取和转发,这个角色叫做 shipper;运行在独立服务器上,完成数据解析处理,负责写入 Elasticsearch 的角色,叫 indexer。
logstash 作为无状态的软件,配合消息队列系统,可以很轻松的做到线性扩展
Beats是 Elastic 从 packetbeat 发展出来的数据收集器系统。beat 收集器可以直接写入 Elasticsearch,也可以传输给 Logstash。其中抽象出来的 libbeat,提供了统一的数据发送方法,输入配置解析,日志记录框架等功能。
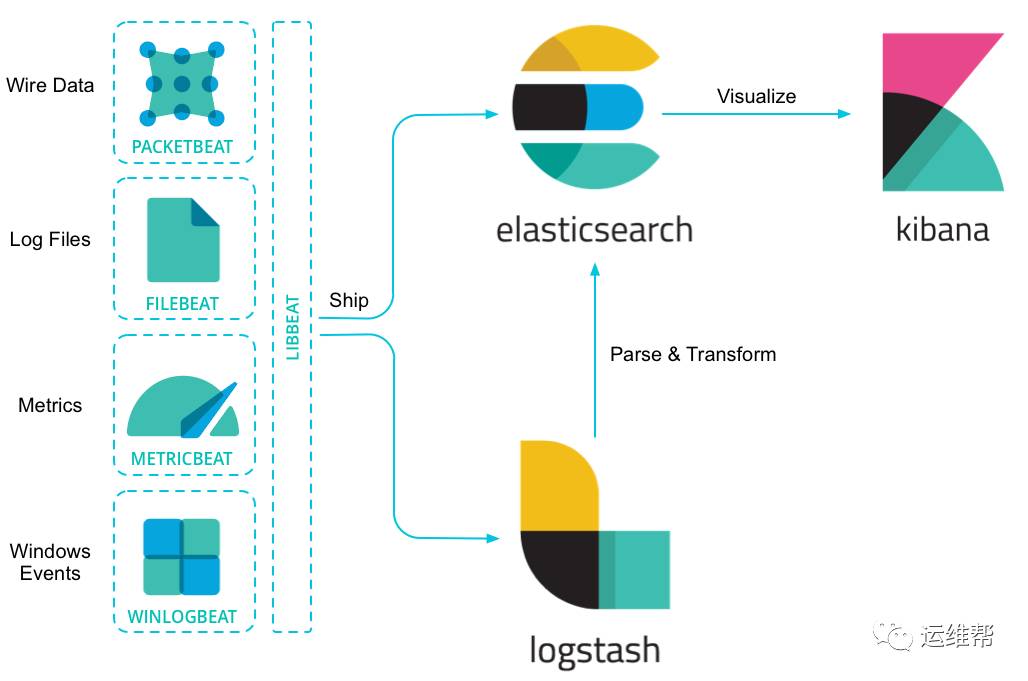
开源社区已经贡献了许多的beats种类。
因为Beats是使用Golang编写的,效率上很不错。
Splunk使用Farwarder和Add-ons来进行数据的消化和获取。
Splunk内置了对文件,syslog,网络端口等input的处理。当配置某个节点为Forwarder的时候,Splunk Forwarder可以作为一个数据通道把数据发送到配置好的indexer去。这时候,它就类似logstash。这里一个主要的区别就是对数据字段的抽取,Elastic必须在logstash中通过filter配置或者扩展来做,也就是我们所说的Index time抽取,抽取后不能改变。Splunk支持Index time的抽取,但是更多时候,Splunk 在index time并不抽取而是等到搜索是在决定如何抽取字段。
对于特定领域的数据获取,Splunk是用Add-on的形式。Splunk 的App市场上有超过600个不同种类的Add-on。

用户可以通过特定的Add-on或者自己开发Add-on来获取特定的数据。
对于大数据的数据采集,大家也可以参考我的另一篇博客。
数据管理和存储
ElasticSearch的数据存贮模型来自于Lucene,基本原理是实用了倒排表。大家可以参考这篇文章。
Splunk的核心同样是倒排表,推荐大家看这篇去年Splunk Conf上的介绍,Behind the Magnifying Glass: How Search Works

Splunk的Event存在许多Buckets中,多个Buckets构成逻辑分组的索引分布在Indexer上。

每个Bucket中都是倒排表的结构存储数据,原始数据通过gzip压缩。
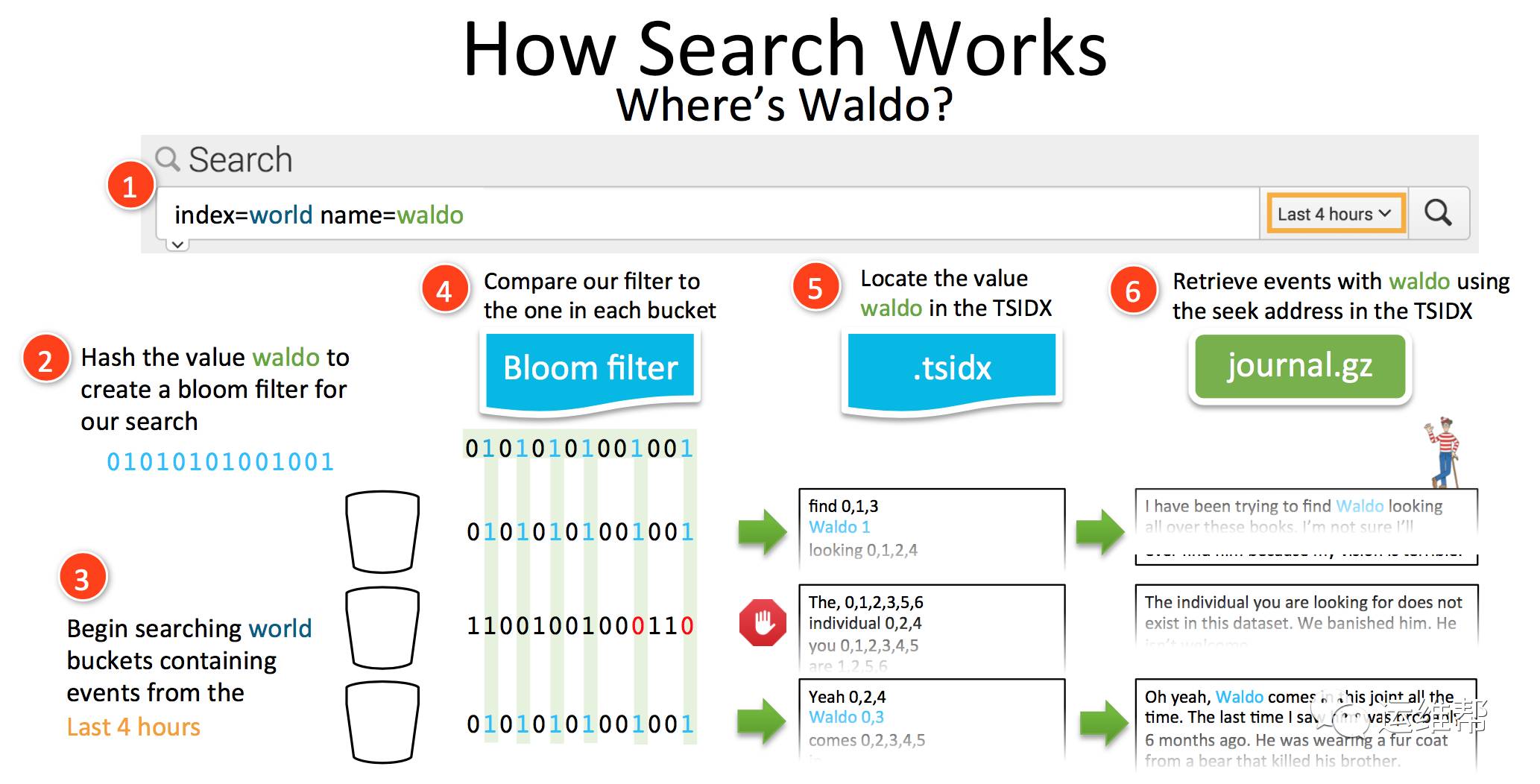
搜索时,利用Bloom filter定位数据所在的bucket。
在对数据的存储管理上,Elastic 和Splunk都是利用了倒排表。Splunk对数据进行压缩,所以存储空间的占用要少很多,尤其考虑到大部分数据是文本,压缩比很高的,当然这会损失一部分性能用于数据的解压。
数据分析和处理
对数据的处理分析,ElasticSearch主要使用 Search API来实现。而Splunk则提供了非常强大的SPL,相比起ES的Search API,Splunk的SPL要好用很多,可以说SPL就是非结构化数据的SQL。无论是利用SPL来开发分析应用,还是直接在Splunk UI上用SPL来处理数据,SPL都非常易用。开源社区也在试图为Elastic增加类似SPL的DSL来改善数据处理的易用性。例如:
从这篇反馈可以看出,ES的search还有许多的不足。
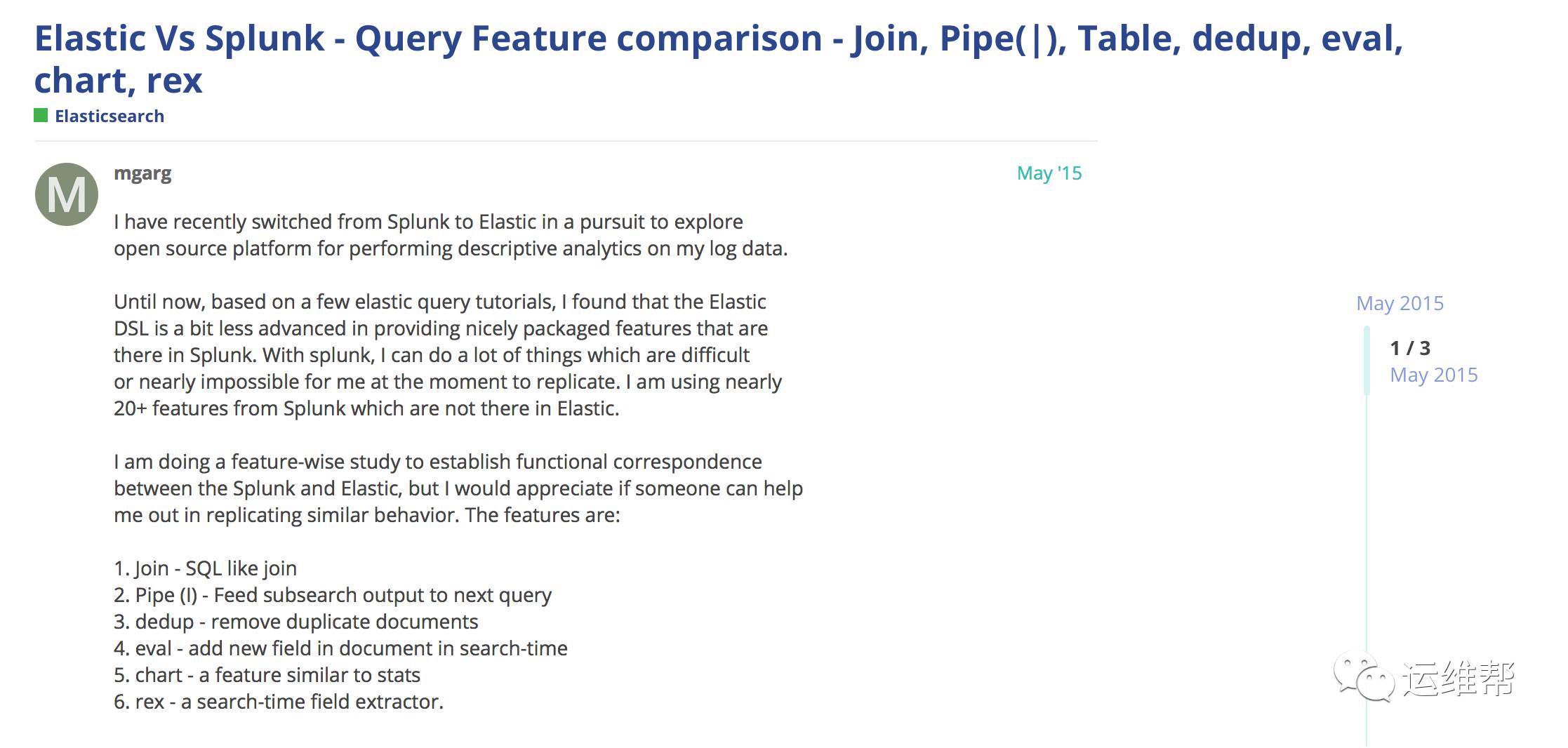
作为对此的响应,Elastic推出了painless script,该功能还处于实验阶段。
数据展现和可视化
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
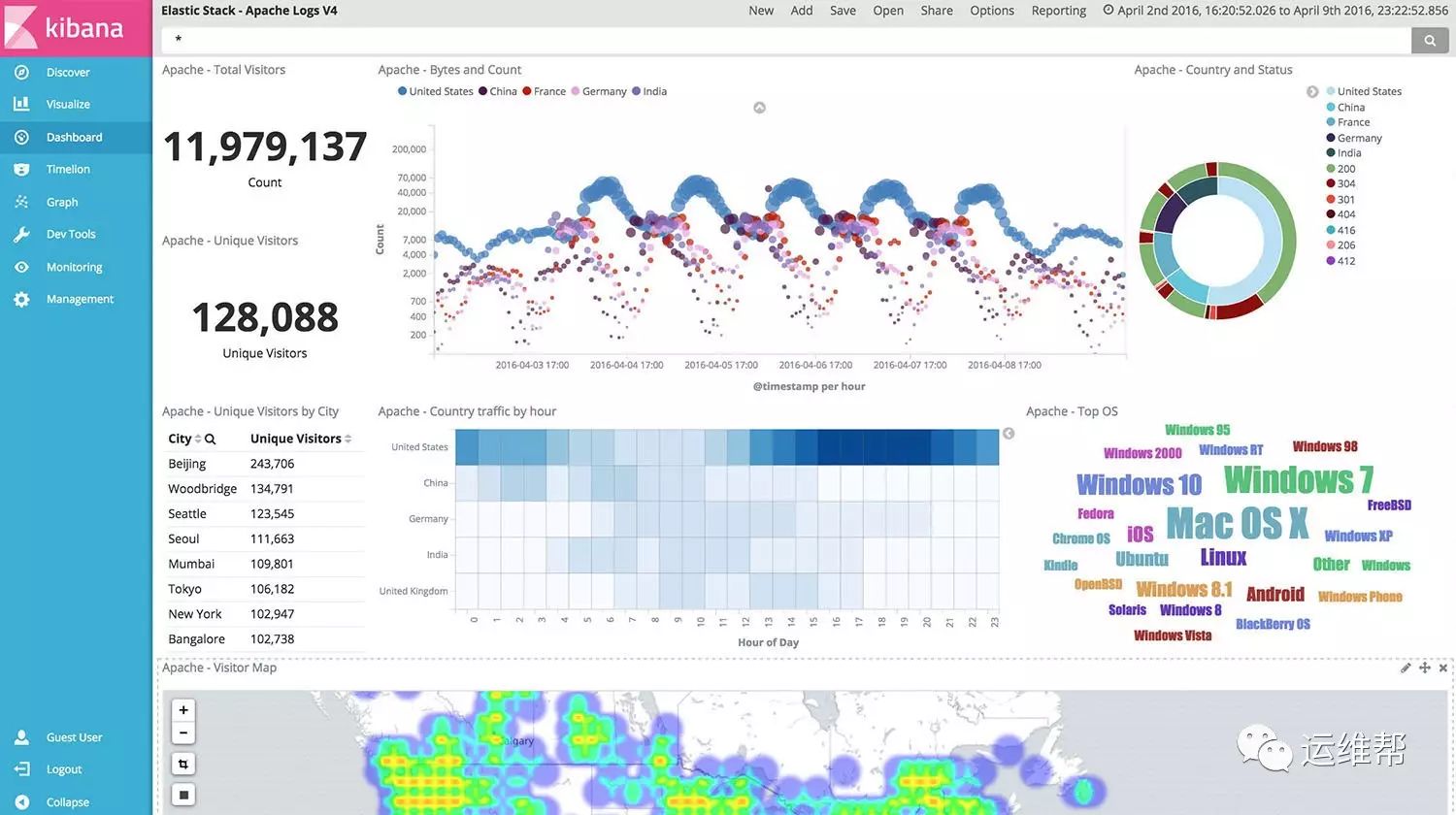
Splunk集成了非常方便的数据可视化和仪表盘功能,对于SPL的结果,可以非常方便的通过UI的简单设置进行可视化的分析,导出到仪表盘。
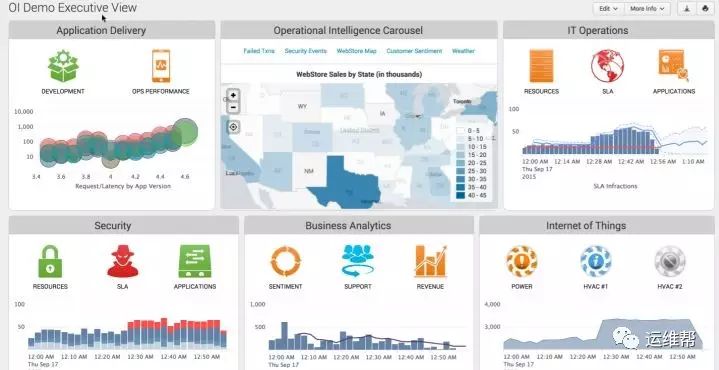
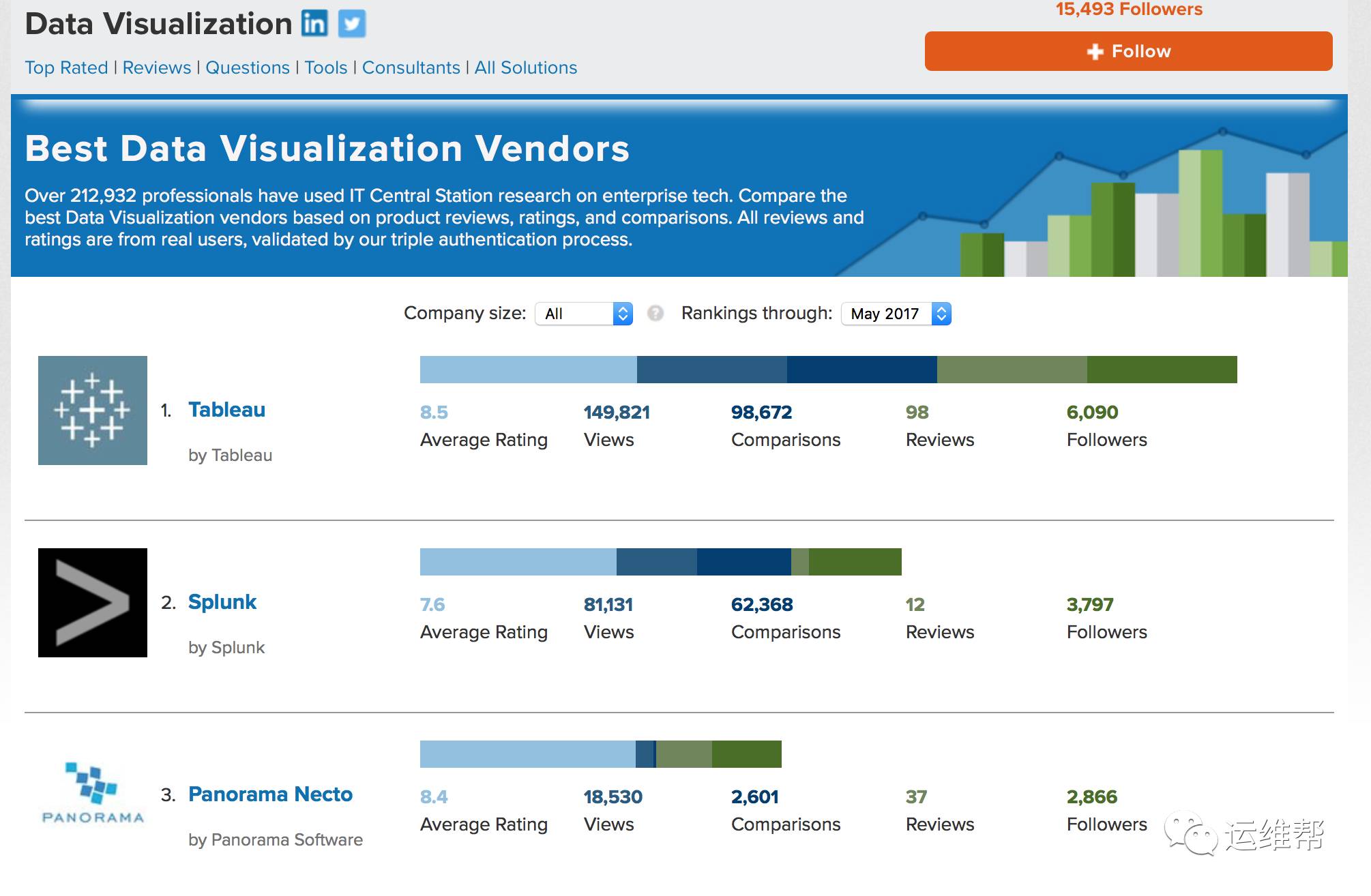
下图的比较来自https://www.itcentralstation.com/products/comparisons/kibana_vs_splunk
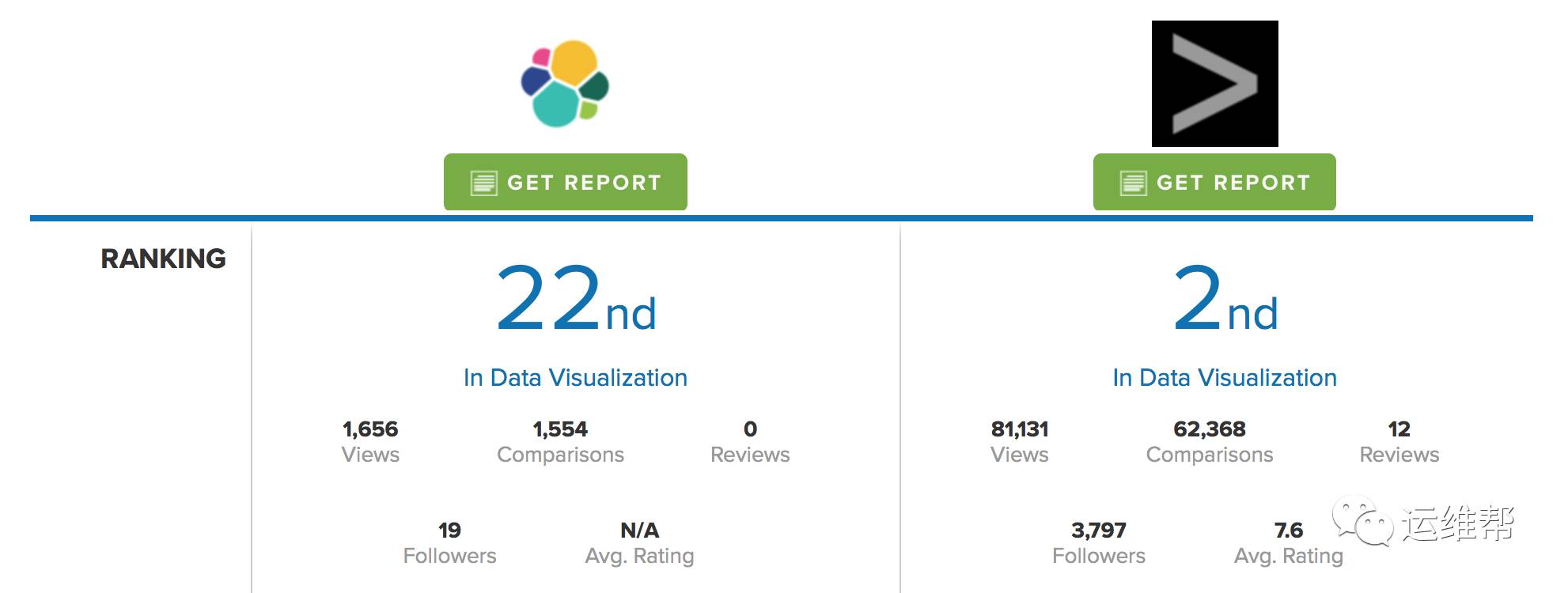
在数据可视化的领域的排名,Splunk仅仅落后于Tableau而已
扩展性
从扩展性的角度来看,两个平台都拥有非常好的扩展性。
Elastic栈作为一个开源栈,很容易通过Plugin的方式扩展。包括:
ElasticSearch Plugin
Kibana Plugin
Logstash Plugin
Beats Platform
Splunk提供一系列的扩展点支持应用和Add-on的开发, 在http://dev.splunk.com/可以找到更多的信息和文档。包括:
Web Framework
SDK
Modular Input
... ...
比起Elastic的Plugin,Splunk的扩展概念上比较复杂,开发一个App或者Add-on的门槛都要相对高一些。做为一个数据平台,Splunk应该在扩展性上有所改进,使得扩展变的更为容易和简单。
架构
Elastic Stack
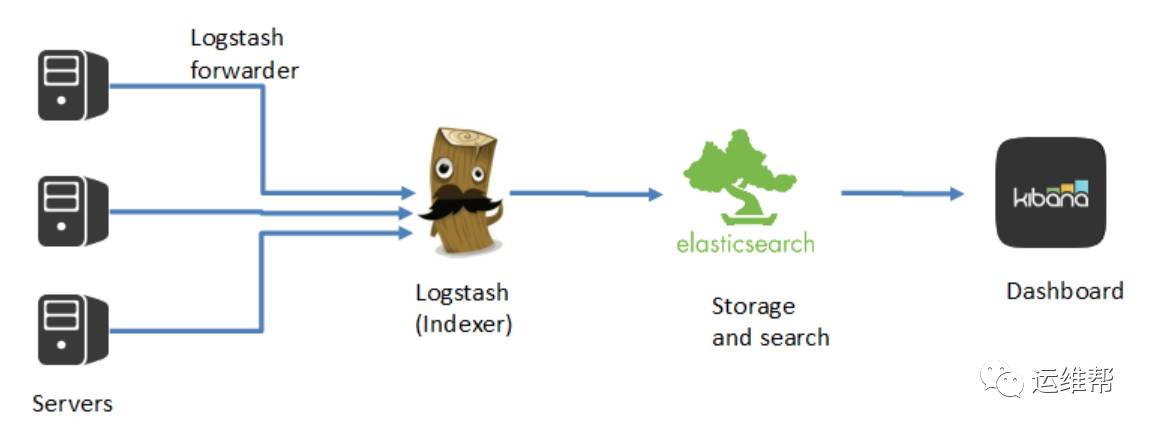
如上图所示,ELK是一套栈,Logstash提供数据的消化和获取,Elasticsearch对数据进行存储,索引和搜索,而Kibana提供数据可视化和报表的功能。
Splunk
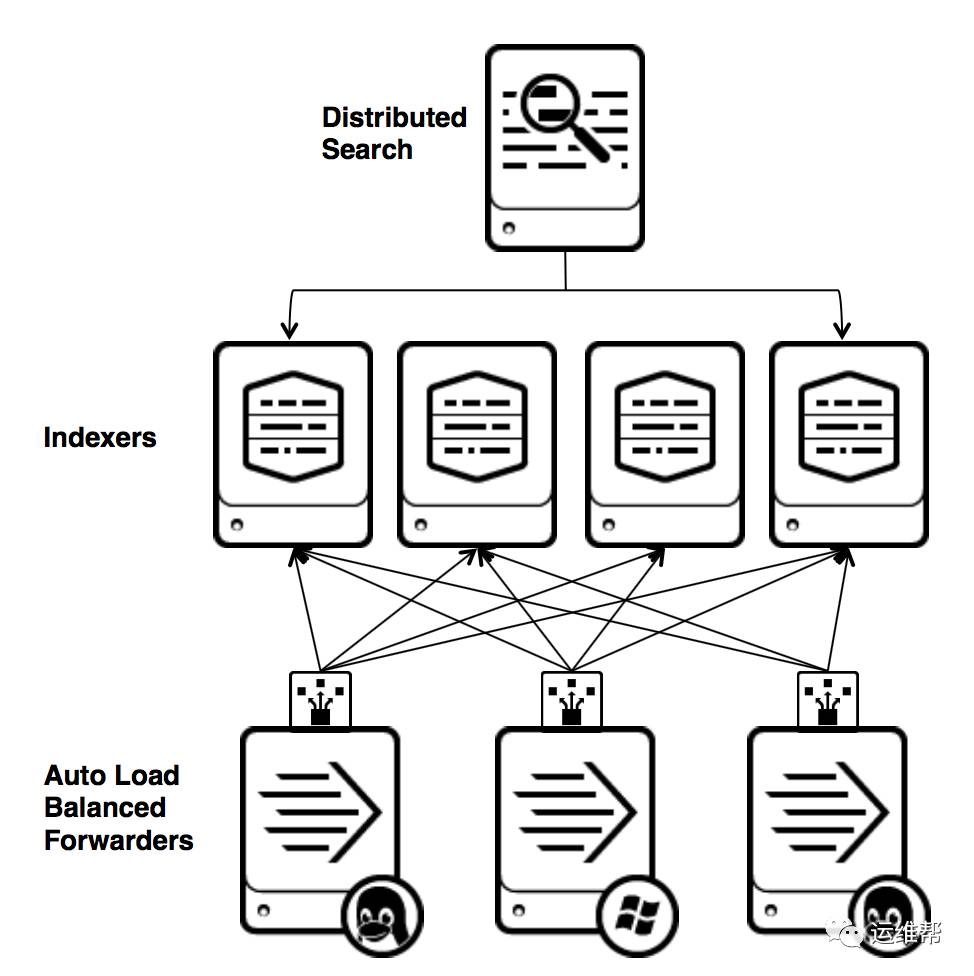
Splunk的架构主要有三个角色:
Indexer
Indexer提供数据的存储,索引,类似Elasticsearch的作用
Search Head
Search Head负责搜素,客户接入,从功能上看,一部分是Kibana,因为Splunk的UI是运行在Search Head上的,提供所有的客户端和可视化的功能,还有一部分,是提供分布式的搜索功能,包含对搜索的分发到Indexer和搜索结果的合并,这一部分功能对应在Elasticsearch上。
Forwarder
Splunk的Forwarder负责数据接入,类似Logstash
除了以上的三个主要的角色,Splunk的架构中还有:Deployment Server,License Server,Master Cluster Node,Deployer等。
Splunk和ELK的基本架构非常类似,但是ELK的架构更为简单和清楚,Logstash负责数据接入,Kibana负责数据展现,所有的复杂性在Elasticsearch中。Splunk的架构更为复杂一些,角色的类型也更多一些。
如果装单机版本,Splunk更容易,因为所有的功能一次性就装好了,而ELK则必须分别安装E/L/K,从这一点上来看,Splunk有一定的优势。
分布集群和扩展性
ElasticSearch
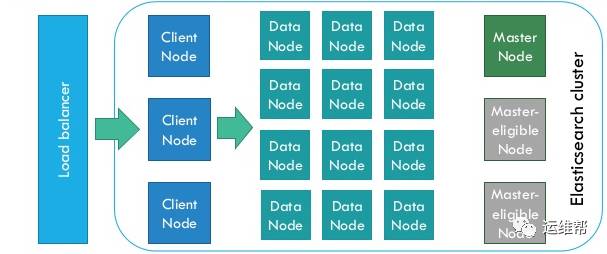
ElasticSearch是为分布式设计的,有很好的扩展性,在一个典型的分布式配置中,每一个节点(node)可以配制成不同的角色,如上图所示:
每一种角色可以通过ElasticSearch的配置文件或者环境变量来配置。每一种角色都可以很方便的Scale,因为Elastic采用了对等性的设计,也就是所有的角色是平等的,(Master Node会进行Leader Election,其中有一个是领导者)这样的设计使得在集群环境的伸缩性非常好,尤其是在容器环境,例如Docker Swarm或者Kubernetes中使用。
参考:
Splunk
Splunk作为企业级的分布式机器数据的平台,拥有强大的分布式配置,包括跨数据中心的集群配置。Splunk提供两种集群,Indexer集群和Search Head集群。
Splunk Indexer集群
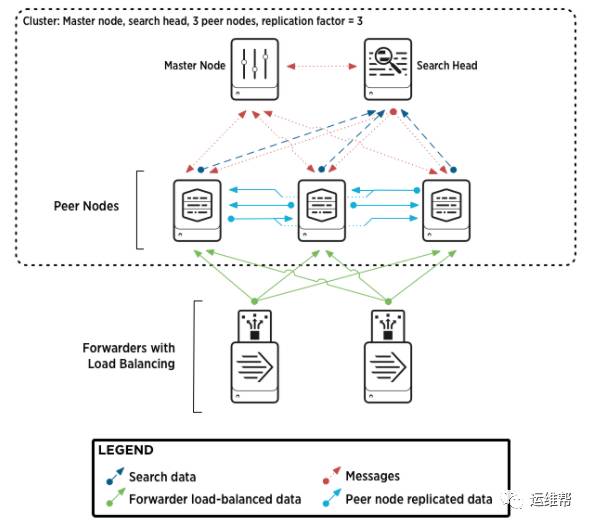
如上图所示,Splunk的indexer集群主要由三种角色:
Master Node,Master Node负责管理和协调整个的集群,类似ES的Master。但是只有一个节点,不支持多Master(最新版本6.6)。Master Node负责
协调Peer Node之间的数据复制
告诉Search Head数据在哪里
Peer Node的配置管理
Peer Node故障时的故障恢复
Peer Nodes,负责数据索引,类似ES的Data Node,Peer Node负责
存储索引数据
发送/接收复制数据到其他Peer节点
响应搜索请求
Search Head,负责数据的搜索和客户端API访问,类似ES的Client Node,但不完全相同。Search Head负责发送搜索请求到Peer Nodes,并对搜索的结果进行合并。
有人会问,那Master是不是集群中的单点故障?What if Master node goes down?Splunk的回答是否。即使Master 节点出现故障,Peer Nodes仍然可以正常工作,除非,同时有Peer Node出现故障。
http://docs.splunk.com/Documentation/Splunk/6.6.1/Indexer/Whathappenswhenamasternodegoesdown
https://answers.splunk.com/answers/129446/why-does-master-node-continue-to-be-single-point-of-failure-in-clustering.html
Splunk Search Header 集群
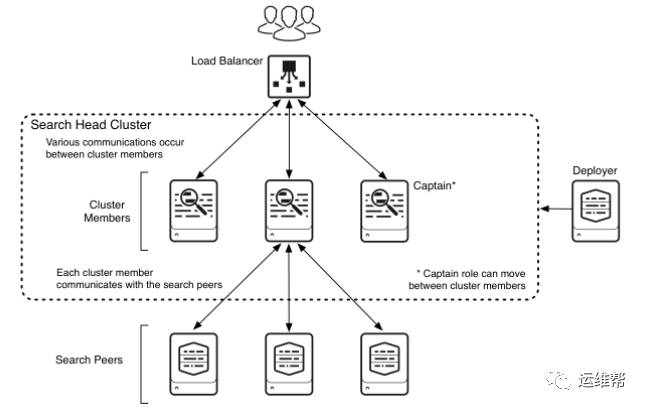
Search Head集群是由一组Search Head组成,它们共享配置,搜索任务等状态。该Cluster主要有以下角色:
Deployer, 负责分发状态和应用到peers
Cluster Member,其中有一个是Captain,负责协调。Cluster Memeber之间会互相通信,来保证状态一致。Load Balancer是个可选项,可以负责Search的接入。
Search Peers,负责数据索引的 Indexer Nodes
另外Splunk还曾经提供过一个功能叫做Search Head Pooling,不过现在已经Depecated了。
Indexer集群可以和Search Head集群一起配置,构成一个分布式的Splunk配置。
相比较ES的相对比较简单的集群配置,Splunk的集群配置比较复杂,ES中所有每一个节点可以灵活的配置角色,并且可以相对比较容易的扩展,利用例如Kubernetes的Pod的复制可以很容易的扩展每一个角色。扩展Splunk相对比较困难,要做到动态的伸缩,需要比较复杂的配置。大家可以参考这里,在容器环境里配置一个Splunk的集群需要比较多的布置,例如在这个Master的配置中,用户需要考虑:
并且集群的扩展很难直接利用容器编排平台提供的扩展接口,这一点Splunk还有很多提高的空间。
产品线
Elastic
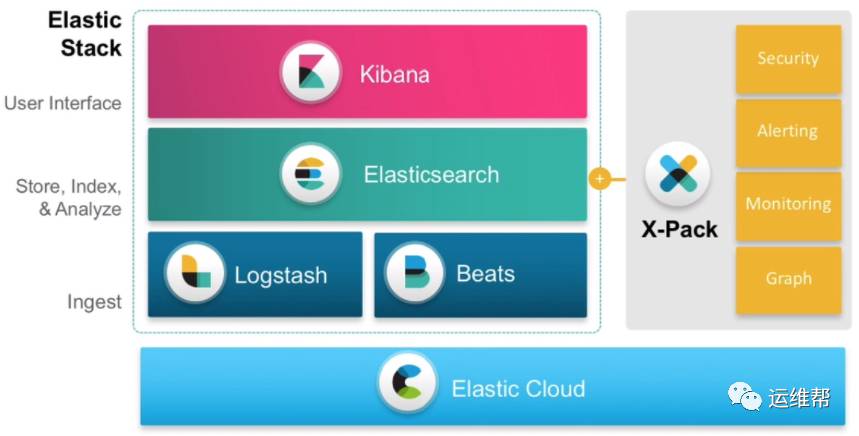
Elastic的产品线除了大家熟悉的ELK(ElasticSearch,Logstash,Kikana),主要包含
Beats Beats是一个开源组件,提供一个代理,把本地抓到的数据传送到ElasticSearch
Elastic Cloud, Elasti提供的云服务
X-Pack, Elastic的扩展组件,提供安全,告警,监控,机器学习和图处理能力。主要功能需要付费使用。
Splunk
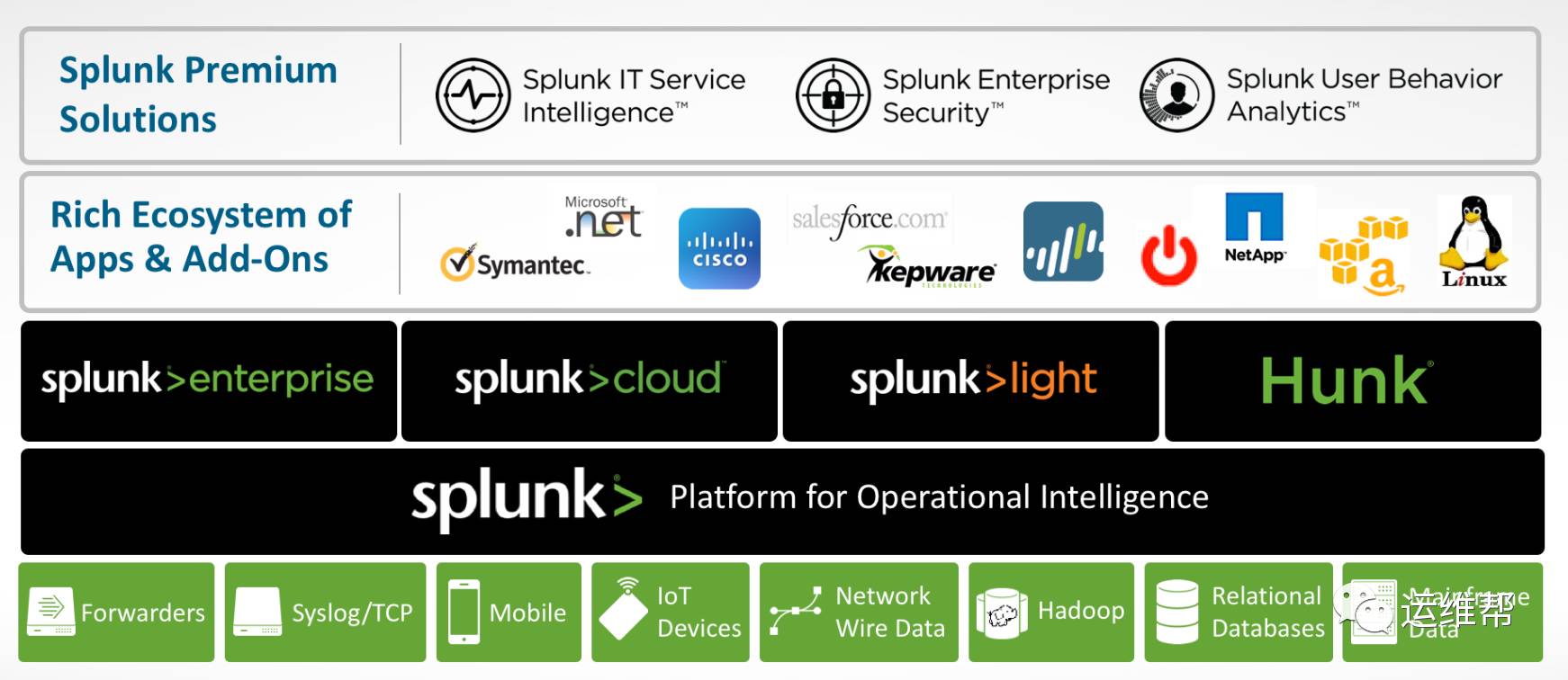
Splunk的产品线包括
Splunk Enterprise
Splunk Cloud, Splunk运营的云服务,跑在AWS上
Splunk Light,Splunk Light版本,功能有所精简,面向中小企业
Hunk, Splunk on Hadoop
Apps / Add-ons, Splunk提供大量的应用和数据获取的扩展,可以参考 http://apps.splunk.com/
Splunk ITSI (IT Service Intelligence), Splunk为IT运维专门开发的产品
Splunk ES (Enterprise Security), Splunk为企业安全开发的产品,这个是Splunk 公司的拳头产品,连续被Gartner评为SIEM领域的领导者,挑战了该行业的传统巨鳄IBM,HP
Splunk UBA (User Behavior Analytic), UBA是Splunk在15年收购的Caspidia带来的基于机器学习的安全产品。
从产品线的角度来看,Splunk除了提供基本平台,在IT运维和安全领域都有自己的拳头产品。Elastic缺乏某个领域的应用。
价格
价格是大家非常关心的一个因素
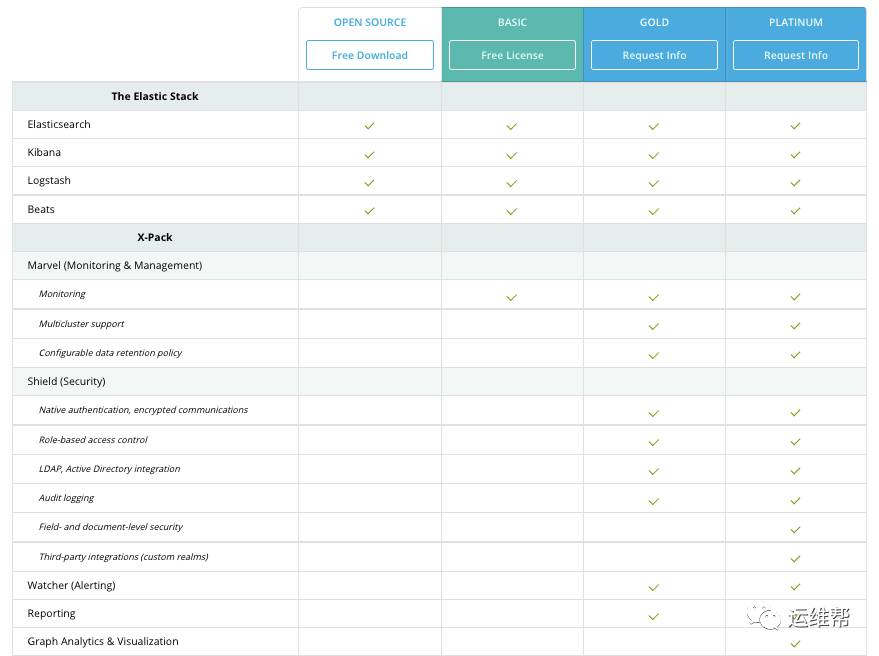
Elastic的基本组件都是开源的,参看下表,X-pack中的一些高级功能需要付费使用。包含安全,多集群,报表,监控等等。
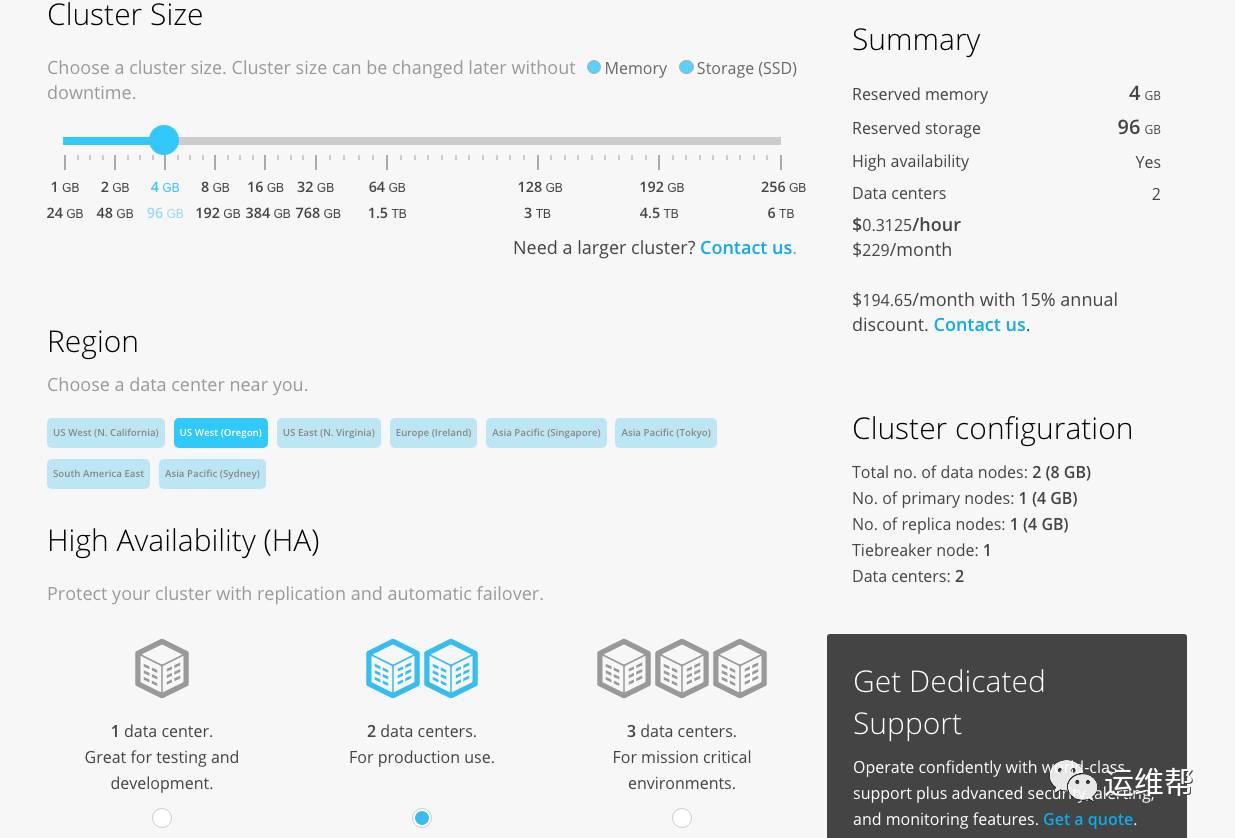
云服务的价格参考下图,ES的云是按照所使用的资源来收费,从这里选取的区域可以看出,ES的云也是运行在AWS上的。下图中的配置每月需要花费200美元左右。(不同区域的收费不同)
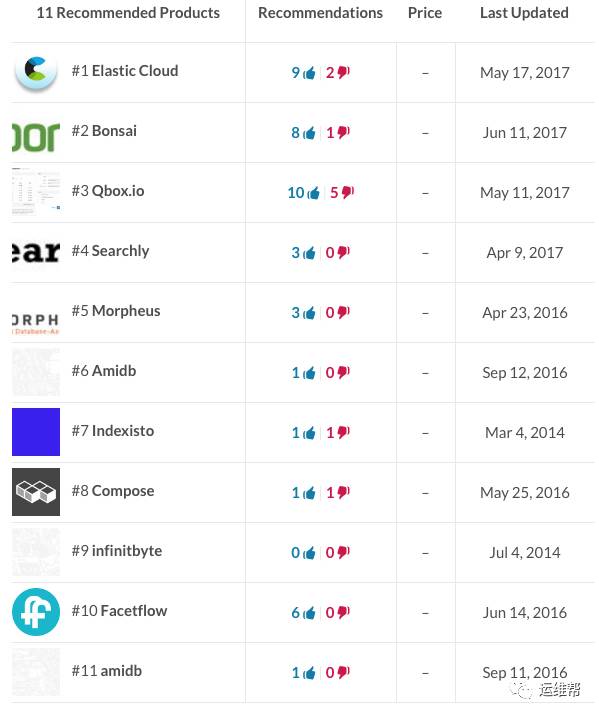
同时,除了Elastic自己,还有许多其他公司也提供Elastic Search的云服务,例如Bonsai,Qbox.io等。
Splunk
Splunk Enterprise是按照数据每日的流量按年或者无限制事件付费,每天1GB的话,每年是2700美元,每个月也是差不多200块。如果每天的数据量少于500M,可以使用Splunk提供的免费License,只是不能用安全,分布式等高级功能,500M可以做很多事情了。

云服务的价格就要便宜多了,每天5GB,每年只要2430元,每个月不到200块。当然因为计费的方式不同,和Elastic的云就不好比较了。另外因为是在AWS上,中国的用户,呵呵了。

总结
大数据的搜索平台已经成为了众多企业的标配,Elastic栈和Splunk是其中最为优秀和流行的选择。两者都有各自的优点和值得改进的地方。希望本文能够在你的大数据平台的选型上,有所帮助。也希望大家来和我交流,共同成长。
参考文档
ELK
ElasticSearch 参考文档https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
Github上收集的ElasticSearch相关开源软件列表 https://github.com/dzharii/awesome-elasticsearch
知乎ElaticSearch专题 https://www.zhihu.com/topic/19899427/hot
中文书 https://github.com/chenryn/ELKstack-guide-cn
中文书 https://www.gitbook.com/book/wizardforcel/mastering-elasticsearch/details
Splunk
Splunk 文档 https://docs.splunk.com/Documentation
Splunk电子书 https://www.splunk.com/web_assets/v5/book/Exploring_Splunk.pdf
Splunk 开发文档 http://dev.splunk.com/getstarted
Splunk 应用市场 http://apps.splunk.com/
Splunk 快速参考 https://www.splunk.com/content/dam/splunk2/pdfs/solution-guides/splunk-quick-reference-guide.pdf
其它
https://www.upguard.com/articles/splunk-vs-elk
https://db-engines.com/en/system/Elasticsearch%3BSplunk
https://www.searchtechnologies.com/blog/log-analytics-tools-open-source-vs-commercial
http://www.learnsplunk.com/splunk-vs-elk-stack.html
https://www.slideshare.net/hepterida/splunk-vs-elk
http://blog.takipi.com/log-management-tools-face-off-splunk-vs-logstash-vs-sumo-logic/
http://blog.takipi.com/splunk-vs-elk-the-log-management-tools-decision-making-guide/
https://www.edureka.co/blog/splunk-vs-elk-vs-sumologic
https://www.youtube.com/watch?v=ElMZqeogc3w (请自行翻墙)








