机器能否进入人类内心深处去了解她们的性格和情感呢?这些问题在心理学领域已经被思考了上千年。日前,微软亚洲研究院资深研究员谢幸受邀在剧院式演讲平台“造就”上发表主题演讲《如何让机器拥有像人一样的思维》。我们整理了谢幸的演讲视频及演讲内容,全文如下。
大家好,我是微软亚洲研究院的谢幸。今天我想和大家探讨的是,“如何让机器拥有像人一样的思维”。
进入正题之前,我先讲一个我自己的故事。最近,我给我三岁的女儿买了一本绘本,名字是“Can I build another me”,她爱不释手。这本书的主角是一个厌倦了自己规律生活的孩子,他希望能训练出一个机器人代替自己按时午睡、吃饭、去幼儿园,这样他就可以自由自在地玩耍。于是,他买来一个最便宜的机器人,带回家来训练它。在这个过程中,他遇到的第一个问题就是,怎样才能让机器人才能变成他呢?于是,他试图告诉机器人各种关于自己的信息,包括他的姓名、年龄、身高、体重,父母、兄弟和宠物,甚至包括“左撇子”“易烦躁”“袜子经常破洞”这种信息。
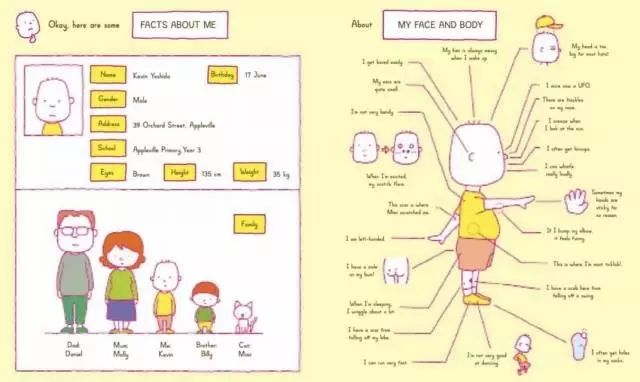
我发现这绘本的作者脑洞很大,他也在思考我们所思考的问题。这个故事也告诉我们,要让机器人拥有人一般的思维,第一步便是理解自己。因为这样我们才能告诉机器人,怎样做才能最像自己。今天,我将从以下几个方面与大家探讨这个问题:
1. 人工智能与心理学
2. 人格分类及推测
3. 如何让机器人像人一样思考
在很长一段时间内,我们团队一直从事用户画像的研究。什么是用户画像?简单说来,就是通过用户产生的大数据,去猜测和理解一个人的年龄、职业、兴趣爱好,也可以去描绘一群人的生活规律和移动模式。这让我们开始思考,我们能不能通过这些数据进一步走到人的内心深处,去了解她们的性格和情感呢?这并不容易。但是在研究的过程中,我们发现这些问题在心理学领域已经被思考了上千年。实际上,人工智能和心理学这两个领域实际上早就有交叉。

人工智能的早期开拓者之一,Herbert A. Simon,是著名的跨界学者。他既是计算机科学家,也是心理学家,是经济学家,还是社会学家,甚至还是认知科学家。让人惊叹的是,他在每个领域都取得了同样卓越的成绩:他获得了1975年的图灵奖、1978年的诺贝尔经济学奖、1986年的美国国家科学奖章,及1993年美国心理学会的终身成就奖。右边这位是多伦多大学的Geoffrey E. Hinton教授,深度学习的积极推动者。他既是计算科学家,同时也是一位心理学家。

两年前,我们便开始拜访著名的心理学家和教授,试图进行跨学科合作交流。在这个过程中,我们首先想解决的问题就是人格。从用户生成的大数据中能否计算出人的性格?
虽然人格这个术语在日常生活中很常见,但是给人格下一个准确清晰的定义却并非易事,即使是心理学家们在这个术语的定义上也很难达成共识。人格最早的定义可以追溯到2000多年前(公元前400年)古希腊医学家希波克拉底(Hippocrates)的体液说,他认为人体是由四种体液构成,包括血液、粘液、黄胆汁和黑胆汁,而这四种体液的分布便决定了人的性格:黑色的胆汁产生了忧郁型人格,血液产生了乐观型人格,黄色胆汁产生了冲动易怒型人格,而粘液产生了冷静型人格。尽管希波克拉底的体液说已经被现代医学所否定,但是他关于人格分类的探讨是有启发意义的,以致于后来的心理学家仍然一直探讨这个问题。
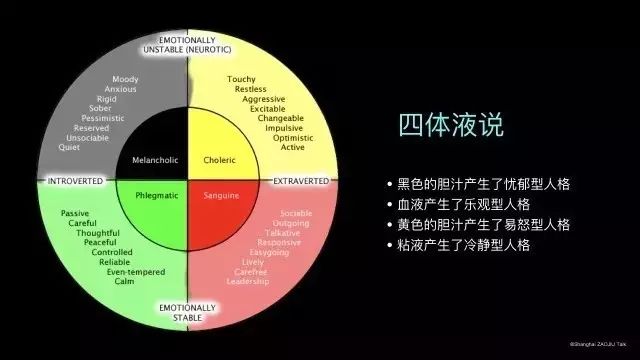
在我们与心理学家交流时,我们又发现了一个有趣事实:在现代心理学中,人格的定义其实跟语言的使用有着紧密的关系。其实在计算机科学领域,我们对语言也有很多研究,我们称之为“自然语言理解”。在心理学里面,有一个概念叫“词汇学假说”。什么叫词汇学假说?根据这个假说,我们无需通过观察、研究各种各样的人来研究人格,我们可以简单一些,通过直接观察人类语言中相关词汇。比如说,你介绍一位朋友给我认识,可能会用一大段话来描述他:“他特别喜欢说话;人很多的时候,他特别高兴,话特别多;每次都听到他在说话,是个话痨”等等。其实,一个词即可概括这段话:健谈。因此,心理学家决定整理这些描述性词汇。如果这个词汇不多的话,它们便可成为建立分类体系的基础。基于这些观察,人格理论的先驱奥尔波特(Allport)和奥德伯特(Odbert)于1936年对英语词汇进行了艰难而又系统的调查研究。通过查看词典,他们按照个人特质、暂时的情绪或者行为以及智力与才干这四个类别发现大约18000个单词,并进一步从中整理出四千多个描述性格的词汇。虽然说四千似乎已经很少了,但对于整个用户语言来说,这仍然是很复杂的。试想下,在描述一个人性格的时候,如果要给这四千个描述维度分别打分,这该是多大的工作量。因此,他们想在此基础上进一步缩减。在这个过程中,他们发现,这些单词间其实存在一些相关性。比如说,一般外向的人通常也比较健谈,冷静的人通常也比较理智,但他可能也比较内向。如果能定位这些相关性,便可在此基础上对四千多个词进行进一步归类。
近二十年来,人格研究者关注与支持最多的人格定义是五因素模型,也常常被称之为“大五人格理论”。如图所示,大五人格包括了五个高度概括的人格因素:外向性 (Extraversion),尽责性 (Conscientiousness),神经质 (Neuroticism),随和型(Agreeableness)和开放性(Openness)。每个人格因素下还有一些细分特质(比如外向性下包括了是否经常参加活动、是否热心肠等)。这样,以后你在介绍朋友时,可以将他描述为“比较外向,但不太随和,可能比较情绪化的一个人”。方式很简单,但是描述很全面。实际上,整理这些词汇以及生成人格分类体系大多是依赖数据驱动,与计算机科学有很多很紧密的联系。那我们能不能自动的计算用户的大五人格呢?其实这也是有可能的。
原文链接:
http://mp.weixin.qq.com/s/vYVwRxutadj-s4v-qSwrmA









