安妮 编译整理
量子位 出品 | 公众号 QbitAI
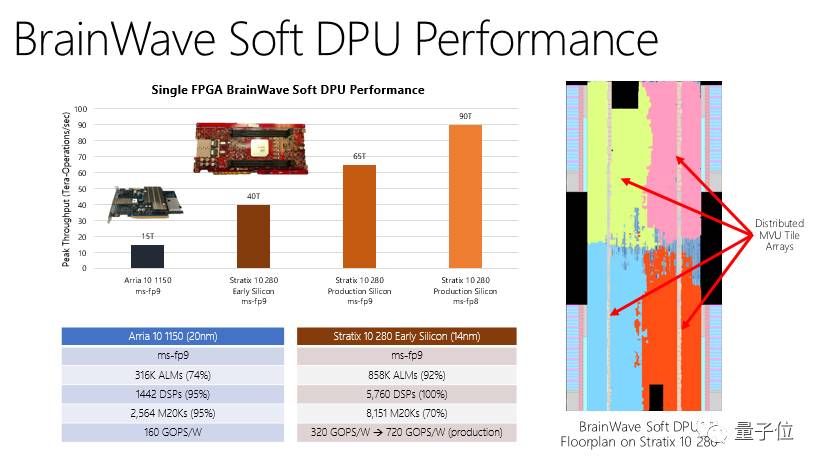
在昨天Hot Chips 2017大会上,微软发布了基于FPGA的低延迟深度学习加速平台。据微软官方博客显示,当使用英特尔Stratix 10 FPGA时,Brainwave可在无批处理的情况下支持每秒39.5万亿次浮点运算。
产品概念
这已经不是微软第一次提出Brainwave的概念,过去几年中微软一直尝试用FPGA提升必应(Bing)与Azure的性能与效率。微软希望赋予开发人员FPGA处理能力,帮助他们运行复杂的任务。因此,这套深度学习加速平台应运而生。
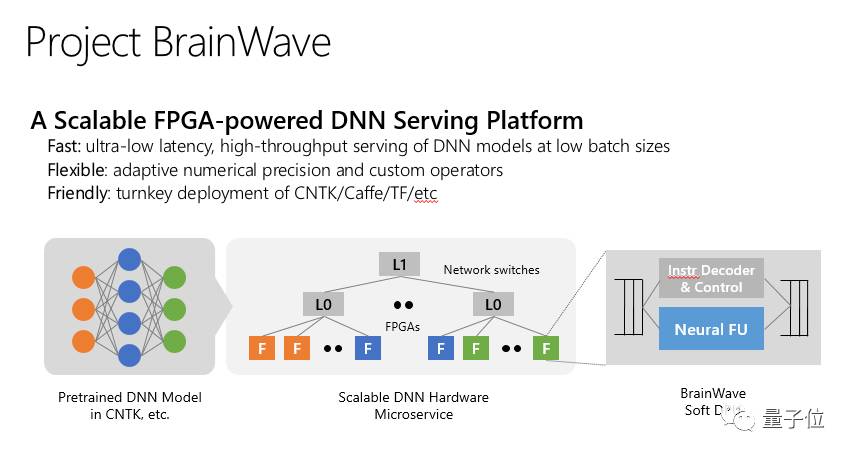
微软在官方博客上公布了Brainwave的三个层面:
-
高性能分布式系统架构
-
集成至FPGA上的深度神经网络(DNN)引擎
-
可低摩擦部署训练模型的编译器和runtime
 △
Brainwave用英特尔FPGA进行演示
△
Brainwave用英特尔FPGA进行演示
性能详解
第一层面
Brainwave利用了大量微软在过去几年里部署的FPGA架构。通过将高性能FPGA链接到数据中心网络,微软让DNN支持硬件微服务。其中DNN可被映射到一个远程的FPGA池,由一个loop中没有软件的服务器调用。
这种系统架构既降低了延迟,并且CPU无需处理传入的请求,允许非常高的吞吐量,所以FPGA处理请求的速度和网络传输速度一样快。
第二层面
Brainwave使用了集成至商用FPGA上的强大的“软”DNN处理单元(DPU)。
不论科技巨头还是初创公司,很多公司正在构建“硬化”的DPU。尽管其中有些芯片峰值性能很强,但必须在设计时就选好操作符和数据类型,这限制了它们的灵活性。
微软的解决办法不同,它提供了跨系列的数据类型,可在合成时间内决策。该设计将ASIC数字信号处理模块、FPGA和合成逻辑三者结合,提供了更庞大、数量上更优化的功能单元。
第三层面
此外,Brainwave内置一个支持各种流行的深度学习框架的软件栈,目前Microsoft Cognitive Toolkit(CNTK)、Tensorflow均已兼容,微软计划支持更多框架。
在这里,微软定义了一种基于图的中间表示,先将模型转换为受欢迎的框架,然后再编译到高性能的基础架构中。





