来源:colinraffel.com
作者:
Colin Raffel
编译:刘小芹
【新智元导读】
本文作者过去一年参加了谷歌大脑实习项目(Residency Program),在Ian Goodfellow的小组工作。本文中作者介绍了他一年间参与的项目和感受,可以说是不可多得的谷歌大脑经验谈。

过去一年里,有许多人问我在谷歌大脑的实习实际上是怎样的,因为这是谷歌大脑实习项目的第一年。我认为最准确的描述就是“相当于一年期的博士生活”,除了地点是在谷歌大脑而不是在大学。如果你是刚接触机器学习,那么这就像博士生的第一年;如果你已经有很多机器学习的经验,做过许多研究,写过论文,等等,那么这个实习项目可能更像博士生的高年级。也就是说,假如你在这个实习项目待上四五年,也无法让人称你为“博士”。
我认为这是一个恰当的描述,因为在这里,我的日常生活和责任与我在博士生期间所做的事情相比没有任何变化。具体来说,我每天早上通常要花一两个小时阅读论文,然后花上一整天编代码和运行实验。有时我会去参加谷歌大脑的研究员或访问学者的讲座。有不少人担任我的“导师”,我需要对他们汇报我的研究进展和想法。而且,也像往常一样,在接近论文deadline期间,我得忙着将我的实验结果提交给相关会议。
当然,两者之间也有一些实质性的差异,主要是由于谷歌大脑是一个非常大的研究实验室(有数百人),而大多数学校里实验室都要小得多。这意味着如果你对某个具体的研究课题有疑问,那么大脑里有可能有人在这个课题工作,或者更具体地说,如果你正在阅读某篇机器学习论文,那么有可能作者就坐在离你只有几百英尺远的地方。此外,在谷歌大脑里有更多的合作机会——或许太多了!在来谷歌大脑之前,我从来没有需要拒绝/推迟与厉害的人进行研究工作的时候。
另一个显着的区别是,你将拥有非常疯狂的计算量任你处置。在几十甚至几百个GPU上进行实验,通常不是什么大事。这确实会对你所做的工作类型具有具体的影响——有更多的空间尝试各种不同的想法,超参数配置,等等。这也意味着你可以更加不注意在开始试验时让所有内容正确/高度优化,不管是好是坏。我记得我在博士期间,花了相当大量的时间来衡量不同的Theano操作,以便可以利用我的单GPU得到最大的性能。在谷歌,更不注重细粒度效率; 相反,注重的是扩大规模。
我的实习目标基本上是:1. 做基础(而不是特定于某个应用的)ML研究;2. 学习知识;3. 利用我在谷歌大脑这一优势。我的研究背景主要涉及序列数据的机器学习模型(博士时主要专注于应用于音乐的ML),所以这令我在选择要研究的问题时,给了我很大的影响。
Subsampling Sequences
我的第一个项目是试图创建一个能够自己发现序列的层次结构的模型。许多序列可以自然地分解成层次结构(例如文档 - >段落 - >句子 - >词汇 - >字符),所以我们希望有一个可以发现这些层次结构的模型是特别强大的或至少是更容易解释的。为了解决这个问题,我决定重点关注一个比较简单的机制,像这样:有一个输入序列,你想通过做一个二进制的“是/否”决定来构造一个较短的输出序列,以决定在输出序列中是否包含输入序列的每个entry。实际上,你只是对输入序列进行“采样”以产生一个新的较短的序列。是否将输入序列的每个entry包含在输出中的决定可以是自适应的,即基于输入序列本身。下面的图可以说明这个想法:
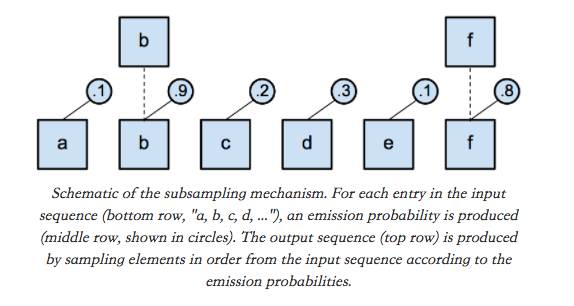
你可以想象,使用RNN处理序列并多次应用这个“二次采样机制”可能会鼓励模型学习分层表示,你可以将每个较短的序列中的每个元素视为表示输入中存在的较粗略的概念序列。幸运的是,可以为输出中包含给定输入序列元素的概率导出表达式,因此你可以使用标准反向传播的机制来训练模型。不幸的是,除了一个简单的问题,我还无法通过这种方法在任何任务上获得良好的效果。例如,我使用这种机制获得的一个模型,在TIMIT任务中只得到~30%的错误率(state-of-the-art 为约17%)。不过,我在ICLR研讨会的扩展摘要[1]中写了这个想法,提出训练一个理想的二次采样机制是可能的。
monotonic attention
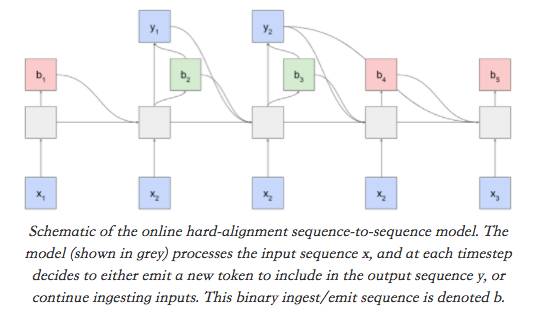
我认为二次采样机制在实践中效果不好的原因之一是,“二次采样概率”必须在产生任何产出之前立即计算。为了解决这个问题,我将注意力机制和序列到序列模型(seq2seq)联系起来,它可以将输入序列转换成新的输出序列。由于输出中的每个元素都是生成的,所以允许“返回”到输入中的条目,这有助于它更直接地调节输出生成过程。虽然注意力机制已被证明是非常有效的,但其一般形式却有一些缺点:首先,这些模型不能在线使用——也就是说,它们不能在输入序列生成时产生输出;第二,它们具有二次时间复杂度,因为对于输出序列的每个元素,模型必须重新处理整个输入序列。但是,通过用二次采样机制替代标准注意事项,我们实际上可以获得在线和线性时序序列模型。这给了我们一种“单调注意力”(monotonic attention),其中一旦模型参与到输入中的给定条目,它不能在随后的输出时间步长中考虑到它之前的任何东西。与采样机制一样,有一个简单的方法来训练这种机制,不需使用梯度估计。原理上,monotonic attention 如下所示:

monotonic attention机制的示意图
这个项目的一个好处是,我能够利用谷歌内部的现有专业知识和代码库来加速实验。令人惊讶的是,谷歌中有许多团队和项目都在使用seq2seq模型,并注意到了这种“monotonic attention”。因此,我在四种不同的代码库中实现了这种方法;这是我能够观察这个模型是否适用于某个任务。这个项目形成了一篇ICML论文[2]。
Hard Alignments with RL
在像谷歌大脑(或像Google / Alphabet这样的大公司)这样大的实验室工作的结果是,可以有多个组的人同时在处理非常相似的想法。 monotonic attention的工作就是这种情况。然而,他们不是用反向传播来训练,而是侧重于用 hard alignments 来训练模型。这排除了反向传播的使用,所以他们使用梯度估计(gradient estimation)技术(REINFORCE [3],NVIL [4],VIMCO [5])。这种方法的好处在于它使训练和测试时间模型行为相同,即意味着训练是线性时间的。困难的部分是,梯度估计的差异化使训练不小心的话难以获得正确结果。关于这个方法,他们最近在arXiv发了一篇很好的论文[6]。
一开始,我们大多在高级别上分享结果和洞察力,但最终我最终尝试了我一直在使用的句子总结基准测试。 这主要是看它是否在语音识别之外的一个设置中工作,这是其主要测试台。 不幸的是,它不能击败一个简单的无关序列序列基线,这表明该模型没有真正利用注意机制。 这可能至少部分是因为让模型工作在语音识别上需要一些不能很好地推广到文本数据的正则化。 尽管有不利的结果,这给了我们一些有趣的见解,用于训练模型的不同方法的重要性。 运行这个实验后,我主要帮助了一个高层次,他们最近在这个方法上发表了一篇关于arXiv的很好的论文[6]。
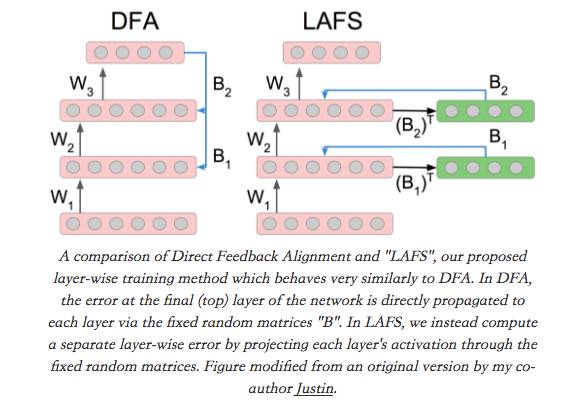
Direct Feedback Alignment
Direct Feedback Alignment(DFA)[8]是一个非常奇怪的想法:在正常的反向传播中,网络的“错误”(损失梯度,关于输出非线性预激活)通过与每个层的权重矩阵相乘来反向传播到较早的层。在DFA中,我们取网络的错误,并将其与固定的随机矩阵相乘,以计算每个层参数的更新。令人惊讶的是,这似乎效果很好。
Magenta
对于我个人来说,在谷歌大脑工作的一件好事是,虽然我可以学习新的研究领域,并进行基础研究,但是在大脑里面有一个关注点在音乐上的小组: Magenta。 我从来没有在Magenta做过大量的工作,但是他们很好,允许我来参加会议,甚至不时地询问我对不同研究思想的看法。我也有机会代表Magenta去了Moogfest,在那里我帮助他们介绍了他们开发的一些工具。
参考文献:
[1]
"Training a Subsampling Mechanism in Expectation"
by Colin Raffel and Dieterich Lawson (arXiv:1702.06914).
[2]
"Online and Linear-Time Attention by Enforcing Monotonic Alignments"
by Colin Raffel, Minh-Thang Luong, Peter J. Liu, Ron J. Weiss, and Douglas Eck (arXiv:1704.00784).
[3]"Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning" by Ronald J. Williams.
[4]"Neural Variational Inference and Learning in Belief Networks " by Andriy Mnih and Karol Gregor (arXiv:1402.0030).
[5]
"Variational inference for Monte Carlo objectives "
by Andriy Mnih and Danilo J. Rezende (arXiv:1602.06725).
[6]
"Learning Hard Alignments with Variational Inference"
by Dieterich Lawson, George Tucker, Chung-Cheng Chiu, Colin Raffel, Kevin Swersky, and Navdeep Jaitly (arXiv:1705.05524).
[7]
"Decoupled Neural Interfaces using Synthetic Gradients"
by Max Jaderberg, Wojciech Marian Czarnecki, Simon Osindero, Oriol Vinyals, Alex Graves, David Silver and Koray Kavukcuoglu (arXiv:1608.05343).
[8]"Direct Feedback Alignment Provides Learning in Deep Neural Networks" by Arild Nøkland (arXiv:1609.01596).
[9]
"Explaining the Learning Dynamcis of Direct Feedback Alignment"
by Justin Gilmer, Colin Raffel, Samuel S. Schoenholtz, Maithra Raghu and Jascha Sohl-Dickstein.
[10]
"Neural Message Passing for Quantum Chemistry"
by Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals and George E. Dahl (arXiv:1704.01212).
原文:http://colinraffel.com/blog/my-year-at-brain.html
【号外】
新智元正在进行新一轮招聘,
飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~






