Chapter 2
这部分将从两个思路跟进现代人脸识别算法:
思路1
:Metric Learning: Contrastive Loss, Triplet loss 及相关 sampling method。
思路2
:Margin Based Classification: 包含 Softmax with Center loss, Sphereface, NormFace, AM-softmax (CosFace) 和 ArcFace.
关键字
:DeepID2, Facenet, Center loss, Triplet loss, Contrastive Loss, Sampling method, Sphereface, Additive Margin Softmax (CosFace), ArcFace.
思路1:Metric Learning
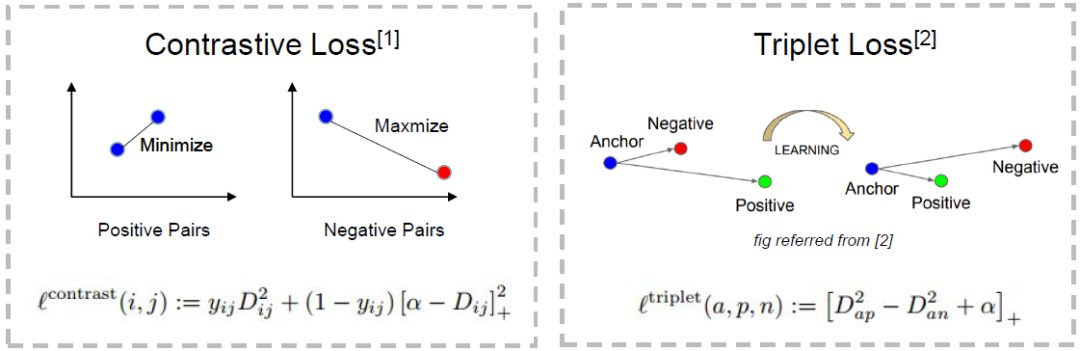
Contrastive Loss
基于深度学习的人脸识别领域最先应用 Metric Learning 思想之一的便是
DeepID2
[2]
了,同 Chapter 1 的思想,“特征”在这篇文章中被称为“DeepID Vector”。
DeepID2 在同一个网络同时训练 Verification 和 Classification(即有两个监督信号)
。其中 Verification Loss 便在特征层引入了 Contrastive Loss。
Contrastive Loss 本质上是使同一个人的照片在特征空间距离足够近,不同人在特征空间里相距足够远直到超过某个阈值 m(听起来和 Triplet Loss 很像)。
基于这样的 insight,DeepID2 在训练的时候不是以一张图片为单位了,而是以 Image Pair 为单位,每次输入两张图片,为同一人则 Verification Label 为 1,不是同一人则 Label 为 -1,参数更新思路见下面公式(截自 DeepID2 论文):

DeepID2 在 14 年是人脸领域非常有影响力的工作,也掀起了在人脸领域引进 Metric Learning 的浪潮。
Triplet Loss from FaceNet
这篇 15 年来自 Google 的 FaceNet 同样是人脸识别领域的分水岭性工作。不仅仅因为他们成功应用了 Triplet Loss 在 benchmark 上取得 state-of-art 的结果,更因为他们
提出了一个绝大部分人脸问题的统一解决框架
,即:识别、验证、搜索等问题都可以放到特征空间里做,需要专注解决的仅仅是如何将人脸更好的映射到特征空间。
为此,Google 在 DeepID2 的基础上,抛弃了分类层即 Classification Loss,将 Contrastive Loss 改进为 Triplet Loss,只为了一个目的:
学到更好的 feature
。
Triplet Loss 的思想也很简单,输入不再是 Image Pair,而是三张图片(Triplet),分别为 Anchor Face,Negative Face 和 Positive Face。Anchor 与 Positive Face 为同一人,与 Negative Face 为不同人。那么 Triplet Loss 的损失即可表示为:
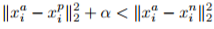
直观解释为:在特征空间里 Anchor 与 Positive 的距离要小于 Anchor 与 Negative 的距离超过一个 Margin Alpha。
有了良好的人脸特征空间,人脸问题便转换成了 Chapter 1 末尾形容的那样简单直观。附上一张我制作的 Contrastive Loss 和 Triplet Loss 的 PPT:
Metric Learning 的问题
基于 Contrastive Loss 和 Triplet Loss 的 Metric Learning 符合人的认知规律,在实际应用中也取得了不错的效果,但是它
有非常致命的两个问题
,使应用它们的时候犹如 pain in the ass。
1. 模型需要很很很很很很很很很很很很很很长时间才能拟合
(months mentioned in FaceNet paper),Contrastive Loss 和 Triplet Loss 的训练样本都基于 pair 或者 triplet 的,可能的样本数是 O (N2) 或者 O (N3) 的。
当训练集很大时,基本不可能遍历到所有可能的样本(或能提供足够梯度额的样本),所以一般来说需要很长时间拟合。我在 10000 人,500,000 张左右的亚洲数据集上花了近一个月才拟合。
2. 模型好坏很依赖训练数据的 Sample 方式
,理想的 Sample 方式不仅能提升算法最后的性能,更能略微加快训练速度。
关于这两个问题也有很多学者进行了后续研究,下面的内容作为 Metric Learning 的延伸阅读,不会很详细。
Metric Learning 延伸阅读
1. Deep Face Recognition
[3]
为了加速 Triplet Loss 的训练,这篇文章先用传统的 softmax 训练人脸识别模型
,因为 Classficiation 信号的强监督特性,模型会很快拟合(通常小于 2 天,快的话几个小时)。
之后移除顶层的 Classificiation Layer,用 Triplet Loss 对模型进行特征层 finetune,取得了不错的效果。
此外这篇论文还发布了人脸数据集 VGG-Face
。
2. In Defense of the Triplet Loss for Person Re-Identification
[4]
这篇文章提出了三个非常有意思的观点:
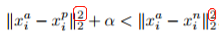
3. Sampling Matters in Deep Embedding Learning
[5]
这篇文章提出了两个有价值的点:
-
从导函数角度解释了为什么第 2 点中提到的
Non-squared Distance
比 Squared-distance 好,并在这个 insight 基础上提出了 Margin Based Loss(本质还是 Triplet Loss 的 variant,见下图,图片取自原文)。
-
提出了 Distance Weighted Sampling。文章说 FaceNet 中的 Semi-hard Sampling,Deep Face Recognition
[3]
中的 Random Hard 和
[4]
中提到的 Batch Hard 都不能轻易取到会产生大梯度(大 loss,即对模型训练有帮助的 triplets),然后从统计学的视角使用了 Distance Weighted Sampling Method。

4. 我的实验感想
延伸阅读中有提到大家感兴趣的论文,可参考 reference 查看原文。最后,值得注意的是,
Triplet Loss 在行人重识别领域也取得了不错的效果
,虽然很可能未来会被 Margin Based Classfication 打败。
思路2:Margin Based Classification
顾名思义,Margin Based Classficiation 不像在 feature 层直接计算损失的 Metric Learning 那样,对 feature 加直观的强限制,而是
依然把人脸识别当 classification 任务进行训练
,通过对 softmax 公式的改造,间接实现了对 feature 层施加 margin 的限制,使网络最后得到的 feature 更 discriminative。
这部分先从
Sphereface
[6]
说起。
Sphereface
先跟随作者的 insight 理下思路(图截自原文):

图 (a) 是用原始 softmax 损失函数训练出来的特征,图 (b) 是归一化的特征。不难发现在 softmax 的特征从角度上来看有 latent 分布。
那么为何不直接去优化角度呢?
如果把分类层的权重归一化
,并且不考虑偏置的话,就得到了改进后的损失函数:
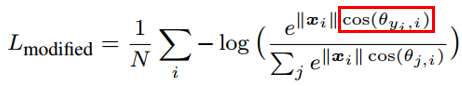
不难看出,对于特征 x_i,该损失函数优化的方向是使得其向该类别 y_i 中心靠近,并且远离其他的类别中心。这个目标跟人脸识别目标是一致的,最小化类内距离并且最大化类间距离。
然而为了保证人脸比对的正确性,还要保证最大类内距离还要小于最小类间距离。上面的损失函数并不能保证这一点。所以作者引入了 margin 的思想,这跟 Triples Loss 里面引入 Margin Alpha 的思想是一致的。
那么作者是如何进一步改进上式,引入 margin 的呢?
上式红框中是样本特征与类中心的余弦值,我们的目标是缩小样本特征与类中心的角度,即增大这个值。换句话说,如果这个值越小,损失函数值越大,即我们对偏离优化目标的惩罚越大。
也就是说,这样就能进一步的缩小类内距离和增大类间距离,达到我们的目标。基于这样的思想最终的损失函数为如下:
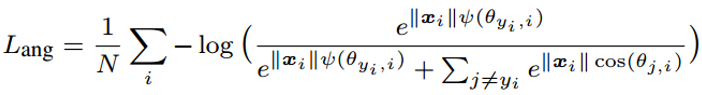
原始的 cos(θ) 被换成了 phi(θ),phi(θ) 的最简单形式其实是 cos(mθ),之所以在原文中变得复杂,只是为了将定义域扩展到 [0,2π] 上,并保证在定义域内单调递减。
而这个 m 便是增加的 margin 系数。当 m=1 时,phi(θ) 等于 cos(θ),当 m>1 时,phi 变小,损失变大。超参 m 控制着惩罚力度,m 越大,惩罚力度越大。
为计算方便,m 一般设为整数。作者从数学上证明了,m>=3 就能保证最大类内距离小于最小类间距离。实现的时候使用倍角公式。
另外:Sphereface 的训练很 tricky,关于其训练细节,这篇文章并没有提到,而是参考了作者前一篇文章
[10]
。有关训练细节读者也可以去作者 Github 上去寻找,issues 里面有很多讨论。
Normface
Sphereface 效果很好,但是它不优美。在测试阶段,Sphereface 通过特征间的余弦值来衡量相似性,即以角度为相似性的度量。
但在训练阶段,不知道读者有没有注意到,其实 Sphereface 的损失函数并不是在直接优化特征与类中心的角度,而是优化特征与类中心的角度在乘上一个特征的长度。
也就是说,我在上文中关于 Sphereface 损失函数优化方向的表述是不严谨的,其实优化的方向还有一部分是去增大特征的长度去了。
我在 MNIST 数据集上做过实验,以下图片分别为 m=1 和 m=4 时的特征可视化,注意坐标的尺度,就能验证上述观点。

然而特征的长度在我们使用模型的时候是没有帮助的。这就造成了 training 跟 test 之间目标不一致,按照 Normface 作者原话说就是存在一个 gap。
于是 Normface 的核心思想就出来了:
为何在训练的时候不把特征也做归一化处理?
相应的损失函数如下:
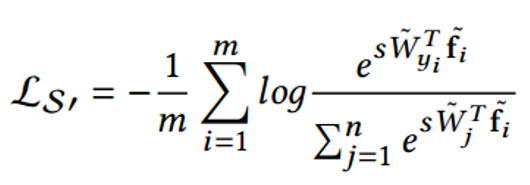
其中 W 是归一化的权重,f_i 是归一化的特征,两个点积就是角度余弦值。参数 s 的引入是因为数学上的性质,保证了梯度大小的合理性,原文中有比较直观的解释,这里不是重点。
如果没有 s 训练将无法收敛。关于 s 的设置,可以把它设为可学习的参数。但是作者更推荐把它当做超参数,其值根据分类类别多少有相应的推荐值,这部分原文 appendix 里有公式。
文章中还有指出一点,
FaceNet 中归一化特征的欧式距离,和余弦距离其实是统一的
。还有关于权重与特征的归一化,这篇文章有很多有意思的探讨,有兴趣的读者建议阅读原文。
AM-softmax
[11]
/ CosFace
[12]
这两篇文章是同一个东西。Normface 用特征归一化解决了 Sphereface 训练和测试不一致的问题。但是却没有了 margin 的意味。AM-softmax 可以说是在 Normface 的基础上引入了 margin。直接上损失函数:
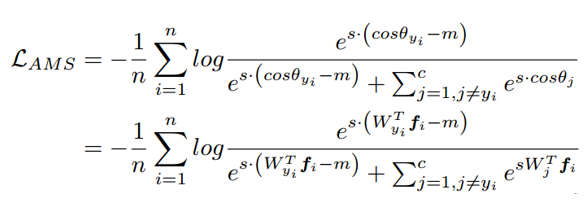
其中这里的权重和特征都是归一化的。
直观上来看,cos(θ)-m 比 cos(θ) 更小,所以损失函数值比 Normface 里的更大,因此有了 margin 的感觉。
m 是一个超参数,控制惩罚的力度,m 越大,惩罚越强。作者推荐 m=0.35。这里引入 margin 的方式比 Sphereface 中的‘温柔’,不仅容易复现,没有很多调参的 tricks,效果也很好。
ArcFace
[13]
与 AM-softmax 相比,区别在于 Arcface 引入 margin 的方式不同,损失函数:
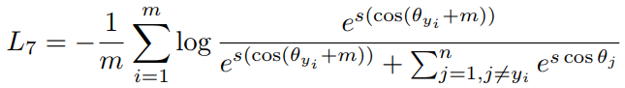
乍一看是不是和 AM-softmax一样?注意 m 是在余弦里面。文章指出基于上式优化得到的特征间的 boundary 更为优越,具有更强的几何解释。
然而这样引入 margin 是否会有问题?仔细想 cos(θ+m) 是否一定比 cos(θ) 小?
最后我们用文章中的图来解释这个问题,并且也由此做一个本章 Margin-based Classification 部分的总结。
小结
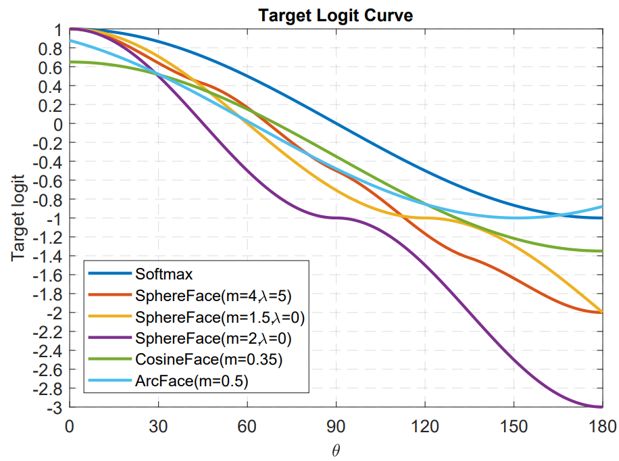
这幅图出自于 Arcface,横坐标为 θ 为特征与类中心的角度,纵坐标为损失函数分子指数部分的值(不考虑 s),其值越小损失函数越大。
看了这么多基于分类的人脸识别论文,相信你也有种感觉,大家似乎都在损失函数上做文章,或者更具体一点,大家都是在讨论如何设计上图的 Target logit-θ 曲线。
这个曲线意味着你要如何优化偏离目标的样本,或者说,根据偏离目标的程度,要给予多大的惩罚。两点总结:
1. 太强的约束不容易泛化
。例如 Sphereface 的损失函数在 m=3 或 4 的时候能满足类内最大距离小于类间最小距离的要求。此时损失函数值很大,即 target logits 很小。但并不意味着能泛化到训练集以外的样本。施加太强的约束反而会降低模型性能,且训练不易收敛。
2. 选择优化什么样的样本很重要
。Arcface 文章中指出,给予 θ∈[60° , 90°] 的样本过多惩罚可能会导致训练不收敛。优化 θ ∈ [30° , 60°] 的样本可能会提高模型准确率,而过分优化 θ∈[0° , 30°] 的样本则不会带来明显提升。至于更大角度的样本,偏离目标太远,强行优化很有可能会降低模型性能。
这也回答了上一节留下的疑问,上图曲线 Arcface 后面是上升的,这无关紧要甚至还有好处。因为优化大角度的 hard sample 可能没有好处。这和 FaceNet 中对于样本选择的 semi-hard 策略是一个道理。
Margin based classification 延伸阅读
1. A discriminative feature learning approach for deep face recognition
[14]
提出了 center loss,加权整合进原始的 softmax loss。通过维护一个欧式空间类中心,缩小类内距离,增强特征的 discriminative power。
2. Large-margin softmax loss for convolutional neural networks
[10]
Sphereface 作者的前一篇文章,未归一化权重,在 softmax loss 中引入了 margin。里面也涉及到 Sphereface 的训练细节。
注:思路二由陈超撰写









