2016
年年中的时候,我读到一篇论文
《基于高铁余票的客流行为特征及其效应分析
——
以沪宁沿线高铁站点为例》(《城市规划》
2015-07
)
。对其中分析方法比较感兴趣,也对其数据的获取方法比较感兴趣。后来听说研究团队编写的程序是到铁路部门的系统中去运行,从而抓取余票数据(未核实)的,那么如果这样的话,这对普通研究者而言,基本上无可行性。后来,我看到
12306
网站上有余票查询的链接(
https://kyfw.12306.cn/otn/leftTicket/init
),可以准确获取实时余票数量。
(目前,该网址已无法查询实时数据,超过一定的余票量将仅显示“有”。因此,按本文的方法抓取的数据,恐将无太大意义。如无研究必要性,请不要去抓取余票数据,避免对
12306
网站服务器造成影响。分析数据地址:链接:https://pan.baidu.com/s/1MlrhIOti3RdfzesBa8Nv4Q 密码:rxvz,包括3个CSV文件。)
于是,我就在想,可不可以用
Python
编写抓爬程序?经过实践,方法可行,并获得最终如论文所示的结论。

一、数据抓取
爬虫程序编写的关键与步骤是,(
1
)理解论文作者的方法;(
2
)找到余票数据源;(
3
)抓取该站点该车次发车前
30
分钟的余票数据;(
4
)程序要全天运行(后来了解到车票有发售时间,不需要
24
小时运行)。
对于步骤
1
,看懂论文的描述,实在看不懂,可以去看作者团队的软件著作权说明中的具体解释。步骤
2
对但凡有点爬虫基础的人,都能找到。步骤
3
,涉及到较复杂的判断,要去判断车次、车站及时间。我采用的是偷懒的做法,不去爬取
30
分钟前的数据,而是去把一天中每一秒、所有车站、所有车次数据全下载下来(仅下载了
2016
年
12
月
21
日星期三沪宁线上的余票数据),后面再来对数据进行清洗。步骤
4
,用
schedule
库来实现。
具体代码,我就不贴出来了,下面的数据分析是介绍重点。
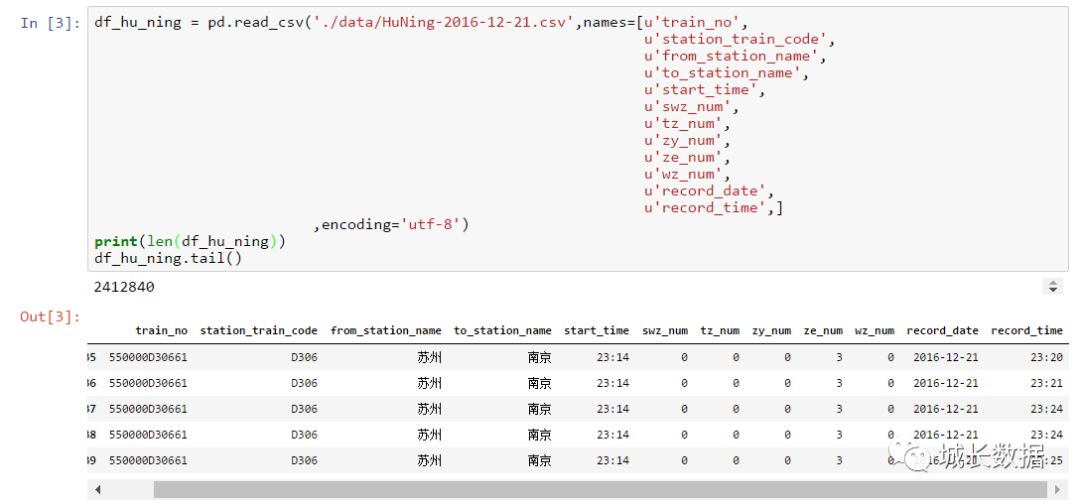
如下图,可以看到沪宁方向(另外还有宁沪方向)共下载了近
241
万条数据(所有车次、所有车站)。
二、数据清洗
1
、筛选数据(时间筛选)
这里要筛选出出发前
30
分钟的余票数据。
第一步,筛选出运行时间段的数据。
上海
—>
南京,最早发车时间为
06:02
,最后一个区间是
22:43 G7128
镇江至南京;南京
—>
上海,最早发车时间为
03:30
,最后一个区间是
22:43 G7128
镇江至南京。

第二步,增加一列,记录发车前
30
分钟数据
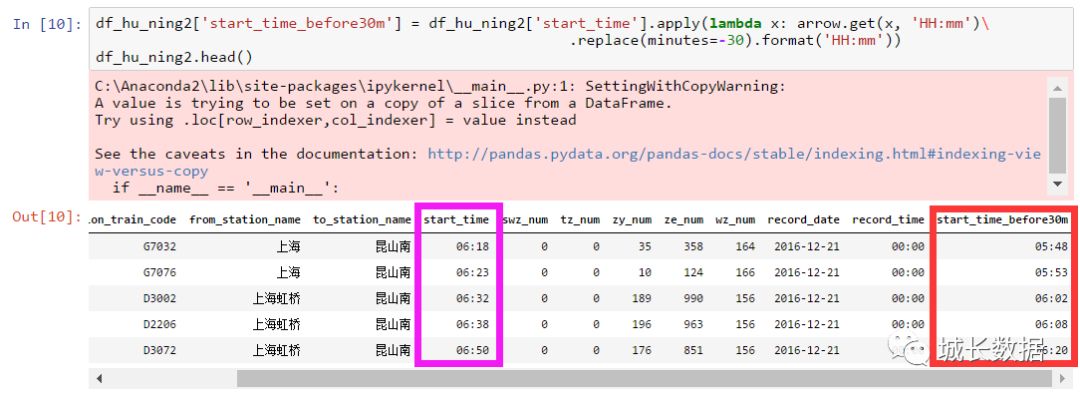
第三步,筛选出发车前
30
分钟时间
==
记录时间。

第四步,加一条列,记录起止站数据,便于后续区间判断。

第五步,保存数据,以待下一步使用。

2
、
筛选数据(区间筛选)
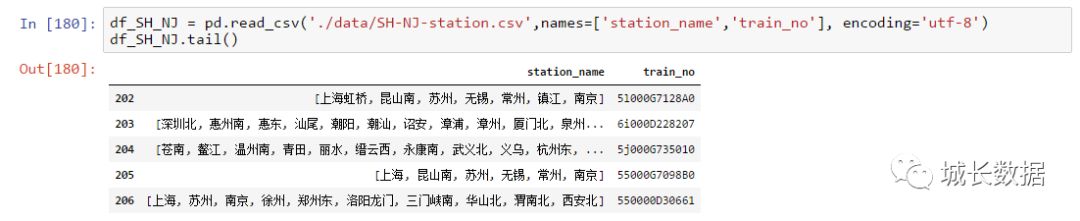
这里要筛选出相邻区间站数据。在筛选之前,要找出沪宁线上有多少个车次、各车次的停靠站点。两个代码如下:不再详细说明。
最终获得的数据如下(沪宁线沪宁方向车次及停靠站点)。
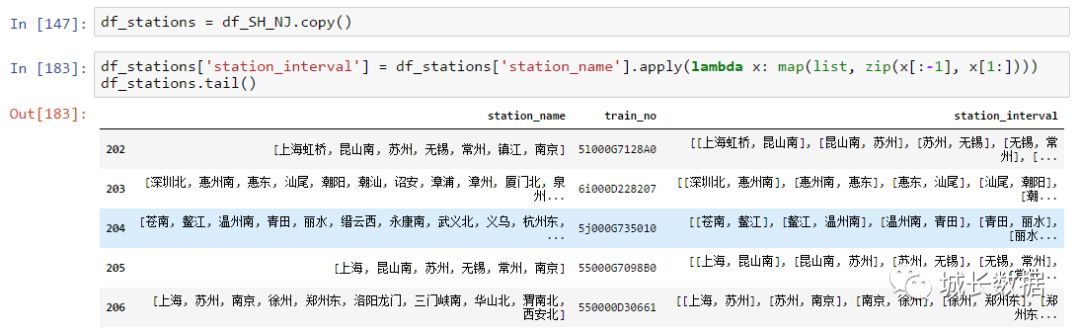
接下来,需要组合每个车次的相邻两个站点。
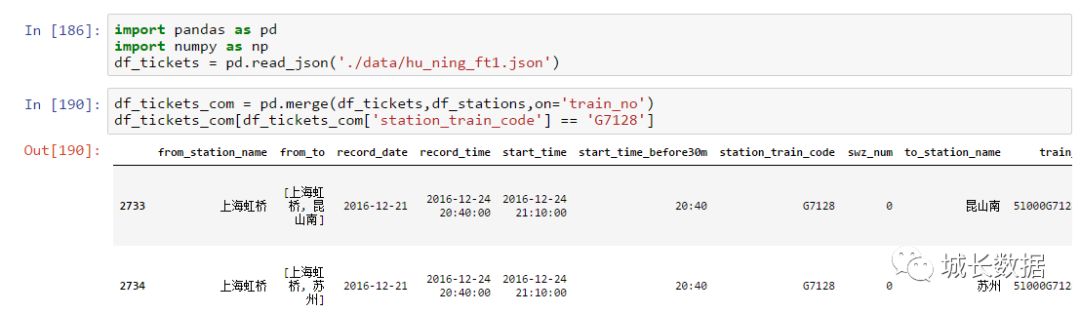
再往后,我们将站点数据(
df_stations
)与前面的时间筛选数据进融合,获得进一步分析的基础数据(
df_tickets_com
)。
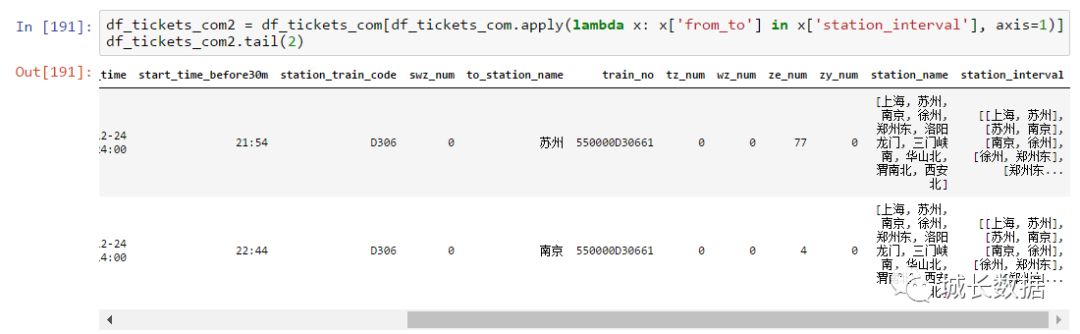
接下来,我们再来获得起终站点是相邻区间站的数据,并保存这个数据。这个数据就是我们经过清洗后的最终数据,接下来就可以进行数据的分析与可视化了。

三、数据分析与可视化
按照论文作者的思路,进行数据分析。
第一步,读取数据,
筛选苏州四个站点,到达站、出发站数据。这里也可以分开筛选单个站点。
第二步,添加两列,分别记录出发、到达的余票数据,并进行对比,即可获得该站点是上的多还是下的多。我的分析中,负数为下为主,正数为上为主。
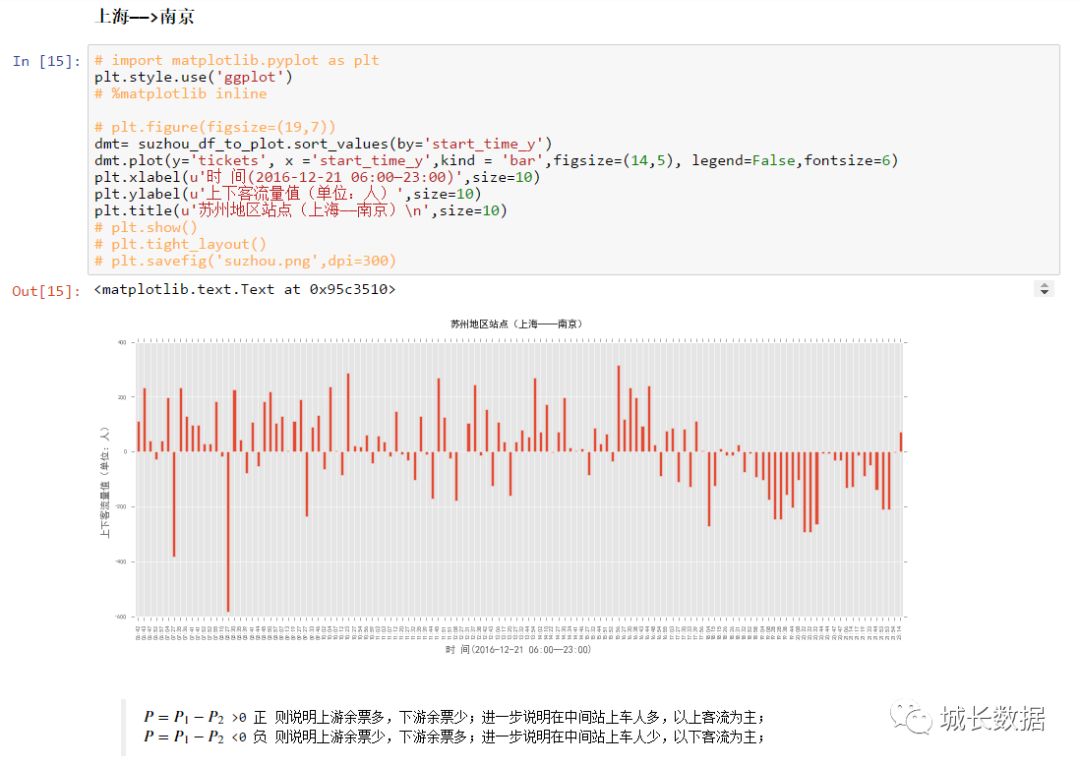
第三步,数据可视化。下图显示的是沪宁线上海到南京(上行方向)苏州地区的客流变化。可以很明显的看到
17:30
以后都是下客流,反映出很多在上海上班的人晚上回苏州住了,上海房价贵啊,买不起啊买不起。
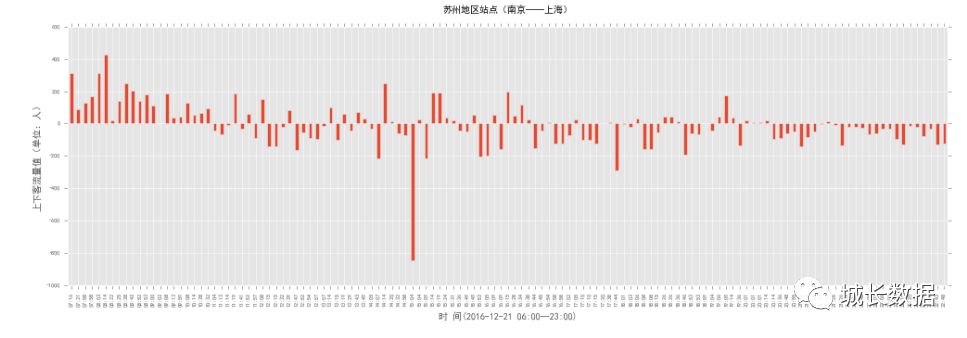
下面这张图显示的是沪宁线南京到上海(下行方向)苏州地区的客流变化。可以很明显看到
11:30
以前都是上客流,反映出上午去上海的人较多,都去上海挣大钱了。
具体介绍到此结束。这分析是
16
年底做的,时间上好久了,可能中间没有介绍清楚。不过没有关系,思路清晰就行。





