经验
|
文献
|
实验
|
工
具
|
SCI写作
|
国自然

作者:麦子
转载请注明:解螺旋·临床医生科研成长平台
上期我们介绍了
一个诊断或风险预测模型的评价指标,重新分类指数(Net reclassification index)
。主要介绍了一些概念和运用,今天我们就来解决一下技术问题,怎么算。想来想去,我觉得计算这个东西还是R比较威武。
话说恰好前两天在知乎上看到某位生物学大大发了这么一张图——
啊呀啊哟!不服啊不服哎!可是想来好像又好有道理^(00)^
今天是R语言代码的盛(暴)宴(击),除了NRI的运算,还有蛮多预处理的操作,在哪都能用得着。大家做好战斗准备。
R里有2个包专事计算NRI,分别为nricens和PredictABEL。从最后结果来说,nricens计算出来的是绝对NRI,PredictABEL则为相对NRI。但我们已经知道计算原理了呀,而且它们都能生成新旧模型分类的对照表,所以其实只用其中一个包就都可以计算了。
不过它们还是有一些小小差异,我们就以logistic回归模型为例,分别看一下这两个包,供大家参考选择。Cox模型参数较多也较复杂,但我相信你看完这篇的讲解就能看懂帮助文档中的cox案例,算是留个小作业给你吧~
先用一份示例数据做个模型。这是survival包里带有的一份梅奥诊所的数据,记录了418位患者的临床指标,观察这些因素与原发性胆汁性肝硬化(PBC)的关系。其中前312位参加了RCT,其他的只参加了观察队列。
我们用前312份样本,做个预测2000天时间点上死亡与否的模型。先载入这份数据看一下。
library(survival)
### logistic回归
egData
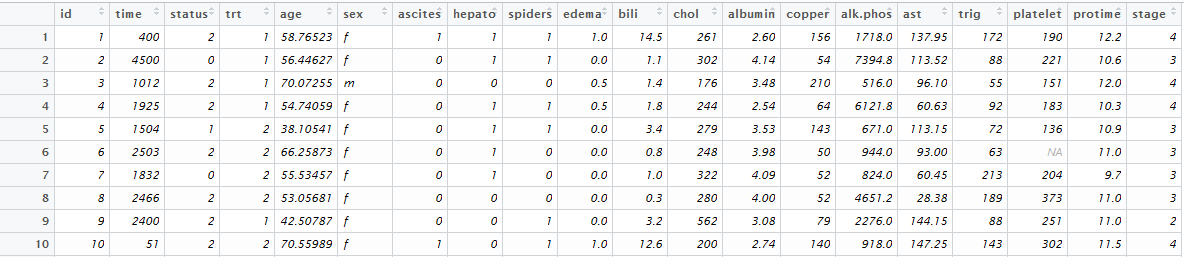
(点击看大图)
做一个logistic回归,我们需要一个结局事件作为因变量,它必需是个分类变量;其次需要若干自变量,它们可以是分类也可以是连续。
这个表中的结局是status,0 = 截尾(删失),1 = 接受移植,2 = 死亡。研究目的“死亡与否”是个二分类变量,所以要做些变换。
再看time一栏,有的不够2000天,这些样本要么是没到2000天就死亡了,要么是删失了。我们要删掉2000天内删失的数据。
egData = egData[egData$time > 2000 |
(egData$time < 2000 & egData$status == 2),]
“[ ]” 表示筛选条件,| 表示“或”,& 为“和”。所以条件句就是egData中的time一列大于2000的保留,或小于2000但同时状态为死亡的也保留。最后一个“,”别忘了,其在条件句的前面表示对列进行选择,在其后表示选择行。
选好后做一个event向量,把status的三个状态变成死亡 = 1, 未死亡 = 0。
event = ifelse(egData$time < 2000 & egData$status == 2, 1, 0)
ifelse (test, yes, no)大法好啊,前面一个test是逻辑判断句,其值为真时返回yes的值,为假时返回no的值。所以本句中test就是当time<2000,且status为2(死亡)时,记为1,否则为0。
然后把event合并入原来的表格。
egData = cbind(egData,event)
cbind()是以列合并,另有rbind()以行合并。这样event就成了最后一列,为结局事件。
然后选择模型的自变量(predictors)。太多了,选取其中几个示例。就以年龄、胆红素、白蛋白为旧模型(standard),三者加上一个凝血酶原时间为新模型(new)。
一般做logistic回归是用glm(因变量 ~ 自变量1 + 自变量2 + …… +自变量n
,
family = binomial
(
'logit'
),
data = 数据表),但如果自变量较多的话,前面那个运算式就会很长很长,万一这些自变量还是基因名或编号,就很想死了。所以顺便讲一个简化的办法,即把那一串先写成formula。
fml.std paste(colnames(egData)[c(5,11,13)],
collapse = '+')))
这里有好几层函数,paste() 会把括号中的元素粘贴起来,collapse是其中的间隔。colnames() 是获取表格的列名,[]中的数值向量为所选择的列序号。这样如果是一个超大表格,你选中第10~70列还可以写成“10:70”。
好了,同样写出新模型的formula:
fml.new paste(colnames(egData)[c(5,11,13,19)],
collapse = '+')))
可以查看一下,新模型的formula写成这个效果:
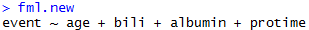
然后像上边说的那样用glm()拟合两个模型。
mstd = glm(fml.std, family = binomial('logit'),
data = egData, x=TRUE)
mnew = glm(fml.new, family = binomial('logit'),
data = egData, x=TRUE)
这样一长串运算式用刚才命名好的fml.std和fml.new代替就好了。x=TRUE是将来用nricens包计算时要求用到的,表示输出结果中是否包含所用到的数据表,平时可以不写。
模型就这样做完了~ 先不急着计算NRI,先看看它的总体情况。
summary(mstd)
运行这句就得到该模型的描述特征。

残差、相关系数、各个自变量的统计显著性等,注意倒数第二行的AIC,就是上一期提到的赤池信息准则,表示模型校准度,很少有人汇报呢。
可以用同样的方法看看新模型。这里就-不展开了,进入下一环节。
• 先看nricens包的方法。
library(nricens)
NRI updown = 'category',cut = c(0.3,0.6),
niter = 10000,alpha = 0.05)
填上新旧两个模型。Cut是判断风险高低的临界值,现在我们写了2个,也就是0~29%为低风险,30%~59%为中风险,60%~100%为高风险。现实中可以查阅相关文献进行设置,预测风险达到多少需要怎样干预之类的。
Updown为定义一个样本的风险是否变动的方式,category是指分类值,即我就熟悉的低、中、高风险,另有一种diff,为连续值。选diff时,cut就设1个值,比如0.02,即认为当预测的风险在新旧模型中相差2%时,即被认为是重新分类了。这种方法用的比较少。
后面几个参数就比较有意思了,niter为重复取样的次数,即boostrap方法,不做的话将其设为0就好了;做的话建议至少1000次,这也是默认值,但我(读书少)见过的研究都10000次。然后将统计显著性alpha设为0.05。
这样就可以看到输出的结果:
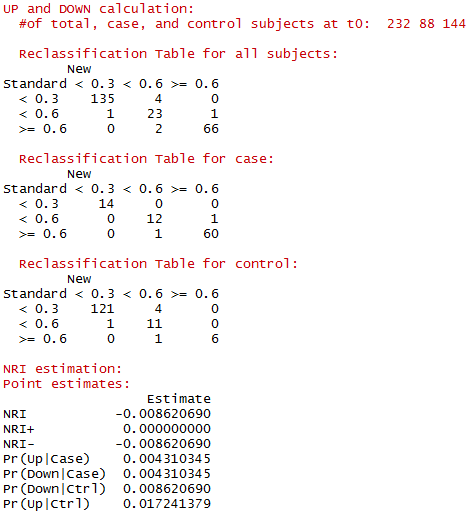
如果不做bootstrap,就是这个结果。有重新分类情况的详表,最后是NRI和各种变动的概率。第一个NRI如前所述,是绝对NRI,大家可以根据之前的知识和上边的详表自己计算验证一下,此时可手动计算出相对NRI。其他指标随便看看。
如果做了bootstrap,就会多出一个表:
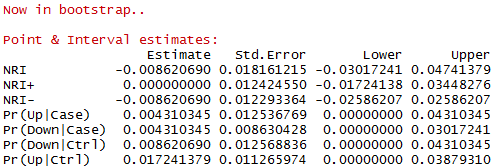
因为做了10000次重复取样,相当于有10000个NRI,于是就有了标准误和置信区间,刚才我们设alpha = 0.05,所以后面的Lower和Upper就是95%置信区间的下界和上界。
同时,做不做bootstrap都会得到一张图,表示各数据点在新旧模型中的分布。
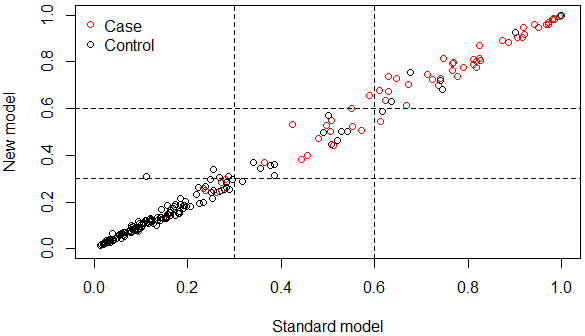
默认的Case和Control标签我觉得不太严谨,Case代表结局事件中编号为“1”的组,也就是发生了结局(死亡),Control为“0”,未发生。其实是positive和negative比较贴切吧。反正就这个意思。这张图也和重新分类表的意思差不多,看看就好。
• 再看PredictABEL包的做法
library(PredictABEL)
pstd pnew
先把两个模型中的预测风险值提出来,也就是模型中的fitted.value。这个包只能从预测风险计算,刚才的nricens包可以用模型,也可以用预测风险(把mdl.std和mdl.new参数换成p.std和p.new)。
reclassification(data = egData,cOutcome = 21,
predrisk1 = pstd,predrisk2 = pnew,
cutoff = c(0,0.30,0.60,1))
cOutcome是结局事件的列序号,刚才我们不是把event放到最后了么,即第21列,填上。两个预测风险值也相应填上。这里的cutoff跟刚才的不一样,还要填上前面的0和后面的1,成为完整的0~100%的区间。
然后得到一个重新分类表:

跟上边nricens做的差不多了。不过这个包没有bootstrap的选项。
接着看下面的结果,这里的分类NRI是咱们上回说的相加NRI,同样可以根据上一期的知识手动计算一下。记得咱们并没有设置bootstrap吧?可这里也有个95%置信区间,只是内部调用了一个更为简陋的只能计算连续NRI的improveProb()函数做的,而且连续变化的临界值也不太透明,遂不管了。
最后还有个IDI是指,发生和未发生结局事件样本的平均预测风险差异,在新模型中提高了0.44%。
这两个包当然各有优劣。nricens计算时可控制的参数较多,汇报起来显得华丽一些。PredictABEL计算结果则多了个IDI和大家喜闻乐见的p值。但也有学者表示,两个模型的差异未必要求p<0.05。
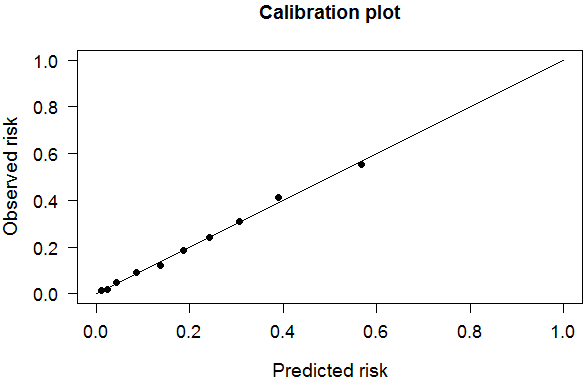
PredictABEL包还有很多有用的功能,比如可以做Hosmer- Lemeshow校准曲线,当然也附送p值(此处没贴出来):
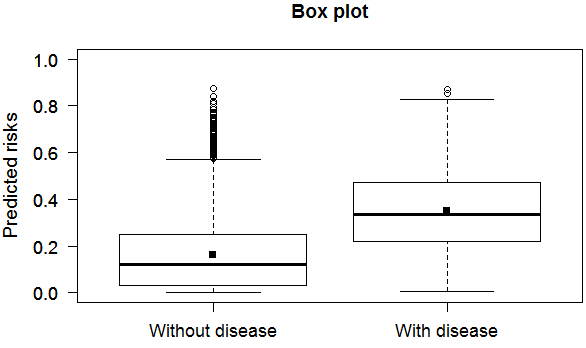
区分度箱形图:
两个模型的ROC曲线:
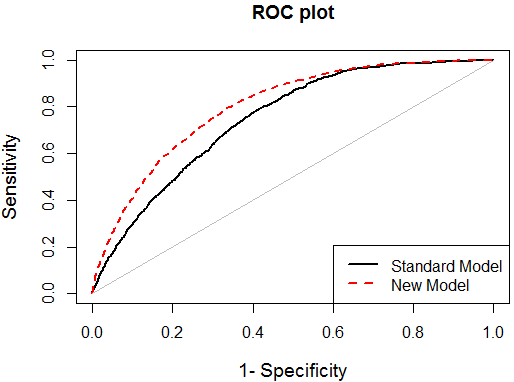
这都是评价一个模型很有价值的参考。





