在信息爆炸的时代,数据挖掘(Data Mining)成为从海量数据中提取有价值信息的关键技术。
其中,表格数据是最常见且重要的数据类型
,它结构清晰、易于理解,广泛存在于各行各业。数据挖掘的核心价值在于从这些表格数据中挖掘出隐藏的规律和趋势。
unset
unset
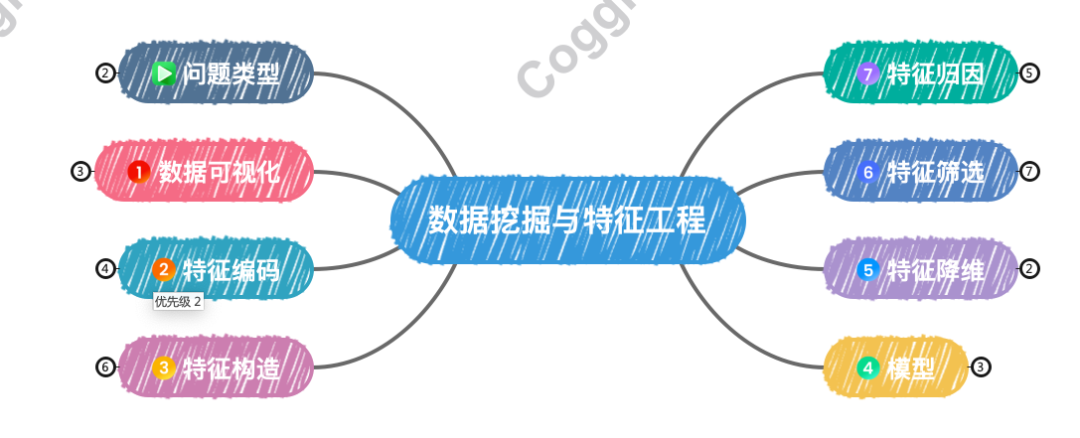
数据挖掘流程
unset
unset
数据挖掘是一个迭代的过程,需要不断地调整和优化各个步骤,以获得最佳的结果。
1. 问题定义 (Problem Definition)
-
明确目标:
首先需要明确数据挖掘的目标是什么,例如预测客户流失、识别欺诈交易、推荐产品等。
-
确定评估指标:
根据目标选择合适的评估指标,例如准确率、召回率、F1分数、AUC等。
2. 数据收集 (Data Collection)
-
确定数据来源:
根据问题定义,确定需要收集哪些数据,例如内部数据库、外部API、公开数据集等。
-
数据清洗:
处理数据中的缺失值、异常值、重复值等问题,确保数据质量。
3. 数据探索 (Data Exploration)
-
数据可视化:
使用图表、图形等方式探索数据分布、趋势、关系等,例如使用seaborn、Matplotlib等库绘制直方图、散点图、箱线图等。
-
特征工程:
对原始数据进行转换、组合、创建新特征等操作,以提高模型的性能。例如:
4. 模型构建 (Model Building)
-
选择模型:
根据问题类型和数据特点选择合适的模型,例如:
-
模型训练:
使用训练数据训练模型,并调整模型参数以获得最佳性能。
-
模型评估:
使用测试数据评估模型的性能,并根据评估结果调整模型。
5. 模型部署 (Model Deployment)
-
模型部署:
将训练好的模型部署到生产环境中,例如将模型封装成API、集成到应用程序中。
-
模型监控:
监控模型的性能,并根据需要进行更新和维护。
6. 结果解释 (Result Interpretation)
-
解释模型结果:
解释模型的预测结果,分析模型预测的流程,例如使用LIME、SHAP等方法解释模型的预测结果。
-
生成报告:
将数据挖掘的结果以报告的形式呈现,例如使用图表、图形等方式展示分析结果。
unset
unset
步骤1:问题定义
unset
unset
在数据挖掘的第一步,我们需要明确数据的类型和问题的类型,并通过历史类似问题和解决方案为后续工作奠定基础。
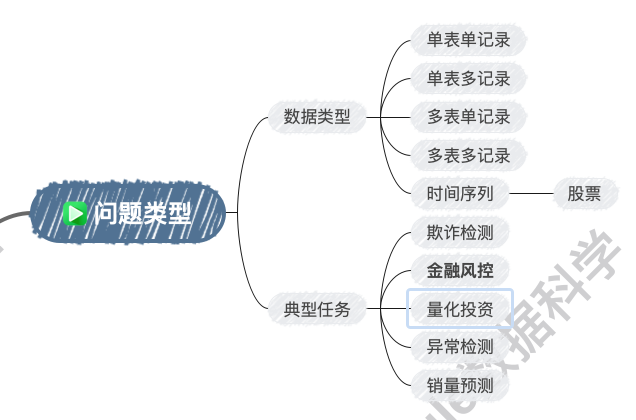
单表单记录
-
特点
:数据存储在一张表中,每条记录独立,没有时间或上下文关联。
-
示例
:客户基本信息表(客户ID、姓名、年龄、性别等)。
-
适用任务
:客户分群、用户画像构建、分类问题(如预测客户是否流失)。
单表多记录
-
特点
:数据存储在一张表中,但每条记录与时间或其他上下文相关,可能存在多条记录对应同一实体。
-
示例
:客户交易记录表(客户ID、交易时间、交易金额等)。
-
-
预测下一个值
:如基于历史交易记录预测下一次交易金额。
-
多表单记录
-
特点
:数据分散存储在多个表中,需要通过关键字段(如ID)进行关联。
-
示例
:客户信息表(客户ID、姓名、年龄) + 交易记录表(客户ID、交易时间、交易金额)。
-
-
特征工程
:通过多表关联构造新特征,如客户的平均交易金额、最大交易金额等。
-
复杂预测
:如结合客户信息和交易记录预测客户流失。
多表多记录
-
特点
:多个表中均存在多记录数据,通常涉及复杂的关联关系。
-
示例
:客户信息表 + 交易记录表 + 产品信息表。
-
-
多维度分析
:如结合客户、交易和产品信息分析销售趋势。
-
复杂建模
:如构建推荐系统,基于客户历史行为和产品特征推荐商品。
unset
unset
步骤2:数据可视化
unset
unset
在数据挖掘的第二步,我们目标是发现数据中的模式、异常和潜在关系,为后续的特征工程和模型构建提供依据。
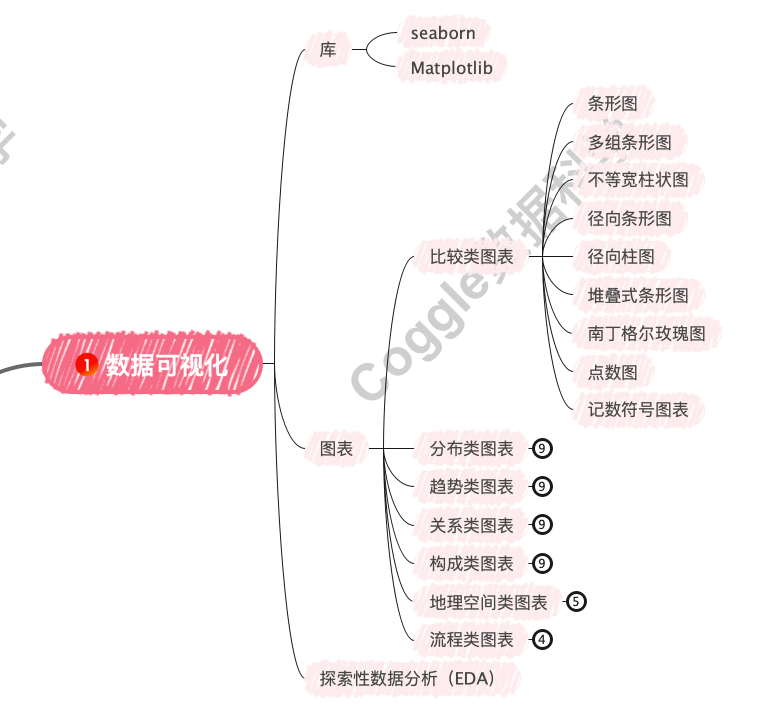
-
Matplotlib
:Python中最基础的绘图库,功能强大,支持高度定制化。
-
Seaborn
:基于Matplotlib的高级可视化库,提供更美观的默认样式和更简洁的API。
根据数据的类型和分析目标,选择合适的图表类型:
unset
unset
步骤3:特征工程
unset
unset
在数据挖掘的第三步,我们通过特征编码和特征构造将原始数据转换为适合机器学习模型使用的格式。这一步骤的目标是提取数据中的有效信息,增强模型的表达能力。
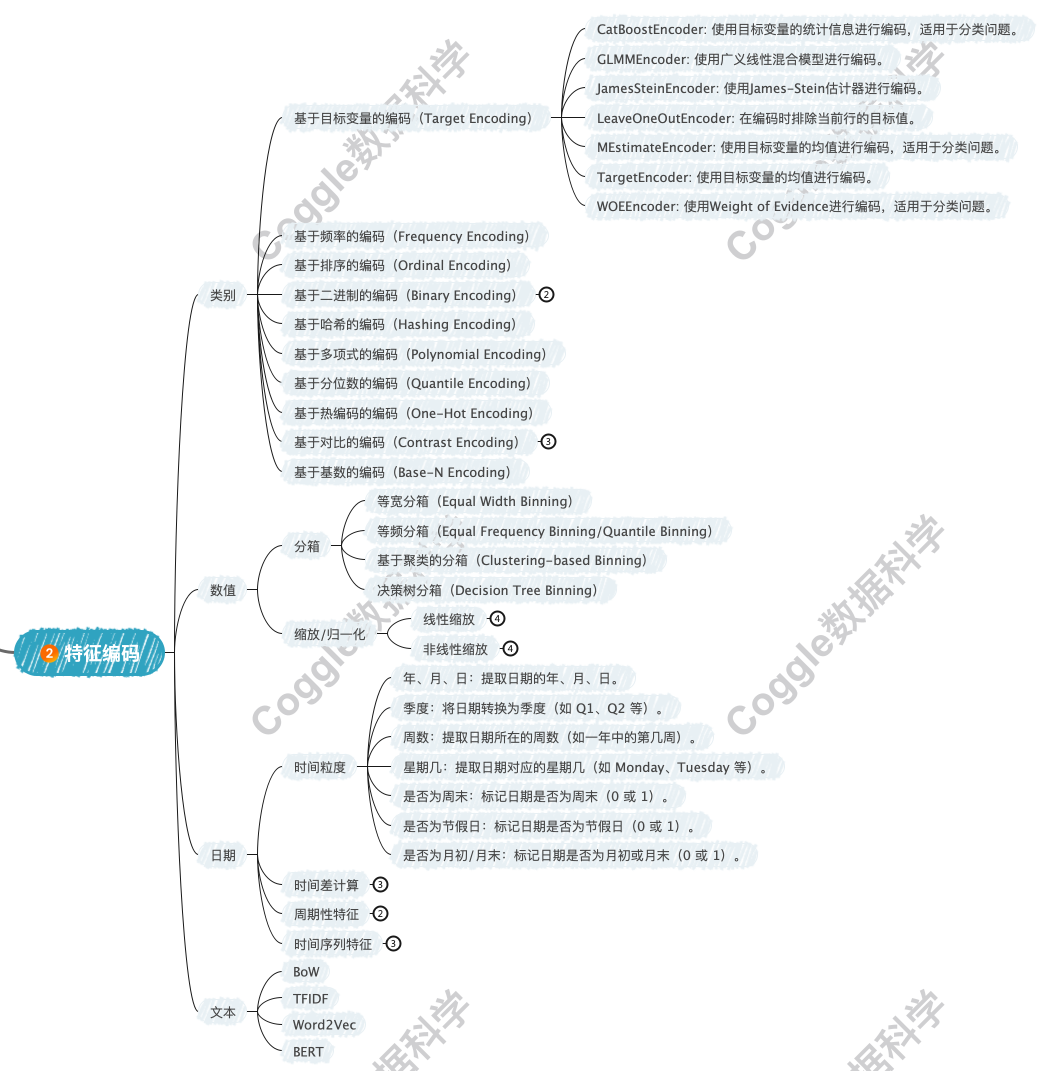
特征编码
特征编码是将非数值型数据(如类别型、文本型、日期型)转换为数值型数据的过程。以下是常见的特征编码方法:
特征构造
特征构造是通过组合、转换或创建新特征来增强模型的表达能力。
-
数值型特征:构造多项式特征(如平方、立方)或交互特征(如乘积、比值)。
-
类别型特征:构造交叉特征(如两个类别型特征的组合)。
-
unset
unset
步骤4:模型选择与训练
unset
unset
在数据挖掘的第四步,我们根据问题的特点选择合适的模型,并进行训练和评估。由于决策树模型具有解释性强、易于实现、对数据分布要求低等优点,通常作为优先选择的模型之一。
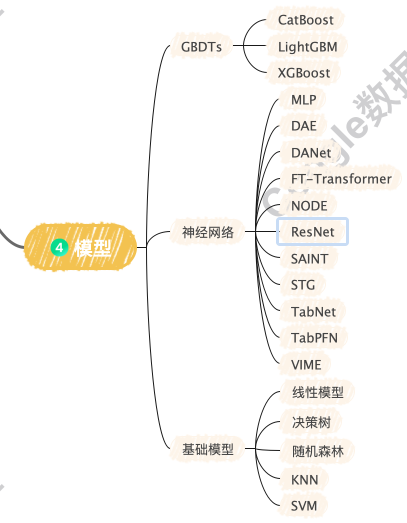
决策树模型在数据挖掘中具有以下优势:
-
-
对数据分布要求低
:不需要对数据进行严格的预处理(如归一化)。
-
支持多种数据类型
:能够处理数值型、类别型和混合型数据。
-
-
易于扩展
:可以通过集成方法(如随机森林、GBDT)提升性能。
unset
unset
步骤5:特征降维与特征增加
unset
unset
在数据挖掘的第五步,我们通过特征降维和特征增加来优化数据集,从而提高模型的性能和效率。特征降维可以减少数据的维度,去除冗余信息,而特征增加则可以通过构造新特征来增强模型的表达能力。
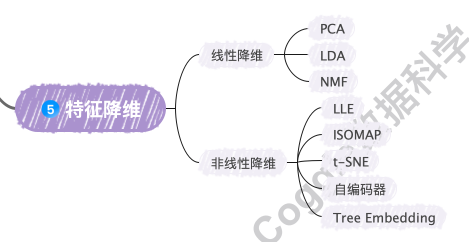
unset
unset
步骤6:特征筛选
unset
unset
在数据挖掘的第六步,我们通过特征筛选选择最相关的特征子集,从而减少过拟合的可能性,提高模型的精度和稳定性。特征筛选的目标是找到对模型预测最有贡献的特征,同时去除冗余和噪声特征。
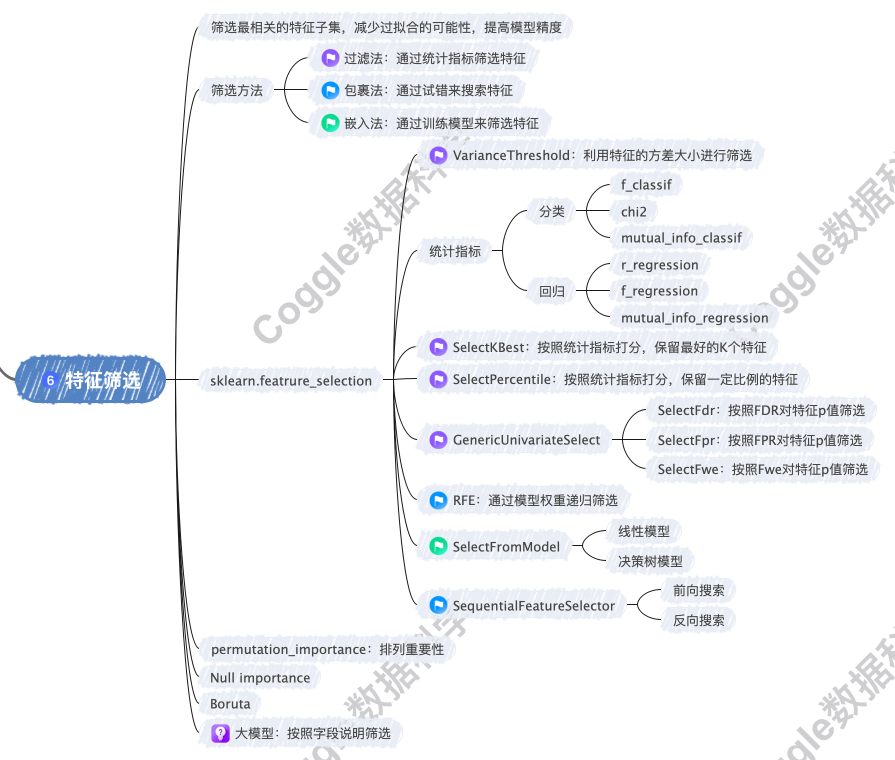
特征筛选方法可以分为三类:过滤法、包裹法和嵌入法。特征筛选的主要优点包括:
-
提高模型性能
:去除无关特征可以减少噪声,提高模型的泛化能力。
-
减少过拟合
:降低特征维度,减少模型复杂度,避免过拟合。









