
本文简要介绍发表于
ICLR 2018
的论文“
Graph Attention Networks
”的主要工作。这篇论文的方法(
GAT
)将A
ttention
机制引入到G
raph
中,使得G
raph
的每个节点可以为其邻居节点分配不同的权重,从而根据不同的重要性来获取邻居节点的特征。论文所提出的
GAT
网络在T
ransductive
和I
nductive
任务上均取得了S
ate-of-the-art
的效果。
基于
CNN
的方法被广泛使用并取得了巨大的成功,例如:图像分类、目标检测、语义分割等。但是
CNN
上具有参数共享特性的卷积核只适用于排列整齐的数据(
Euclidean Data
),包括语音、图像、视频等,在G
raph
结构的数据上却无能为力。近几年,关于G
raph
的应用和需求急剧增长,其中包括社交网络、交易网络和知识图谱等,甚至在常见的
CV
领域,判断目标间的视觉关系往往也和G
raph
密切相关。所以,越来越多学者将目光投向了图神经网络(
Graph Neural Networks
,
GNN
),期待这类方法能更好地帮我们解决图上的问题,而我们所要介绍的
Graph Attention Networks
(
GAT
),就是其中一个很优秀的方法。
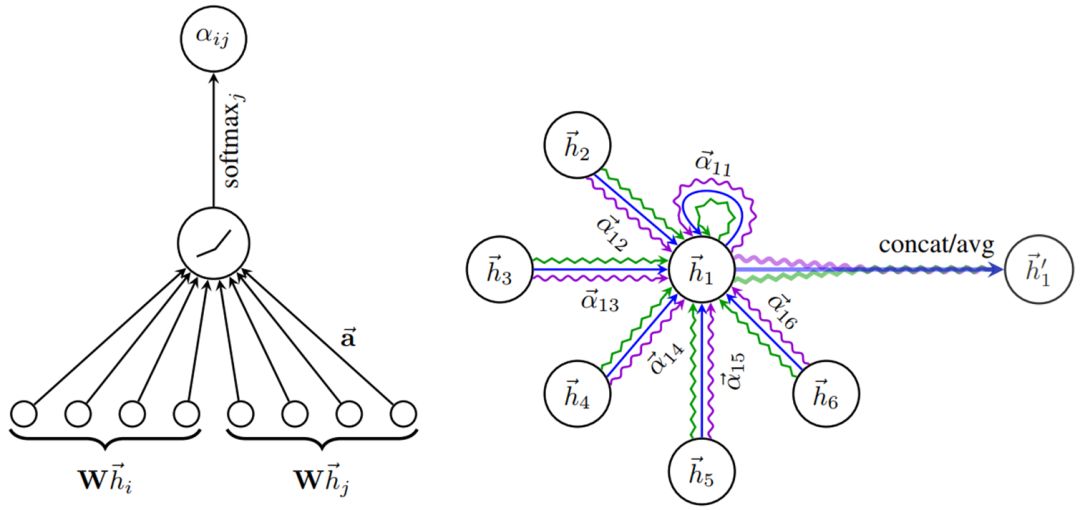
图
1.
左图表示文章所用的A
ttention
机制
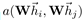 ;右图表示节点
1
和其邻居节点通过A
ttention
的方式作特征聚合。
;右图表示节点
1
和其邻居节点通过A
ttention
的方式作特征聚合。
论文的动机旨在引入A
ttention
机制到图上,从而让图上的每个节点能按一定的重要性去注意其周围的邻居节点,通过邻居节点的特征组合获取新的特征表达。其中,最为重要的是S
elf-attention
的操作:
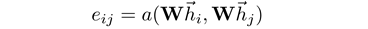
其中,
h
表示输入节点的特征向量,
W
是可学习权重。函数
a()
的实现方式有很多种(点乘、C
osine
距离、
MLP
等),它的作用是计算邻居节点
j
到中心节点
i
的重要性(相似性)。在计算出节点间的重要性系数
e
之后,为了让各个节点的系数可直接比较,还需要作下归一化:
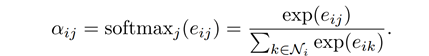
这里,主要是把节点
i
的邻居节点(通常也包括其自身)的重要性系数
e
输入到S
oftmax
函数中,从而将它们归一化为
0-1
间的概率值,从而得到最终的权重
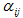 。在论文中,计算重要性系数
e
的函数
a()
采用了
MLP
层的实现,所以,完整的A
ttention
公式如下:
。在论文中,计算重要性系数
e
的函数
a()
采用了
MLP
层的实现,所以,完整的A
ttention
公式如下:
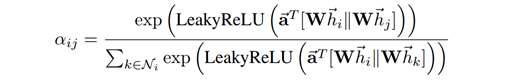
上式的
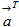 即表示一层
MLP
的权重向量。
即表示一层
MLP
的权重向量。
在获得这些A
ttention
的权重
之后,我们就可以按照这也权重来对邻居节点的特征作加权和,为中心节点
i
计算一个新的特征表示:
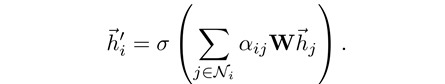
此外,
GAT
同样借鉴了T
ransformer
[1]
里面的M
ulti-head Attention
思想,即进行多次平行的A
ttention
后,将特征C
oncat
在一起,作为最终的特征输出:
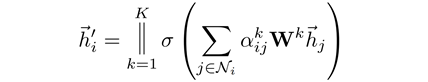
这里做了
K
次A
ttention
,再将各个特征C
oncat
在一起。
上面所介绍的就是
GAT
里面的A
ttention Layer
,完成一次这样的A
ttention
,相当于就是一层卷积,在
GAT
里面,我们可以堆积多个这样的A
ttention Layer
,来搭建一个完整的网络结构。
论文在T
ransductive
和I
nductive
两类任务上对方法作了实验验证,其中I
nductive
任务中测试的G
raph
在模型训练的时候并没有见过。
表
1. GAT
在论文引用数据集
Cora
,
Citeseer
,
Pubmed
上的表现
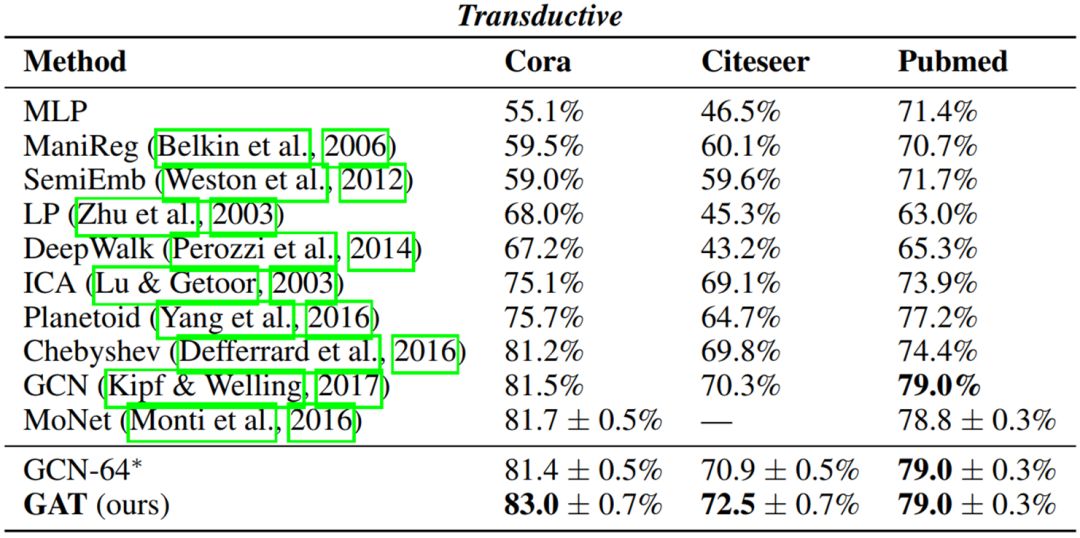
可以看到,
GAT
相较于其他方法在分类精度上有明显的提升,并取得了
SOTA
的结果。
表
2. GAT
在
PPI
蛋白质数据集上的表现
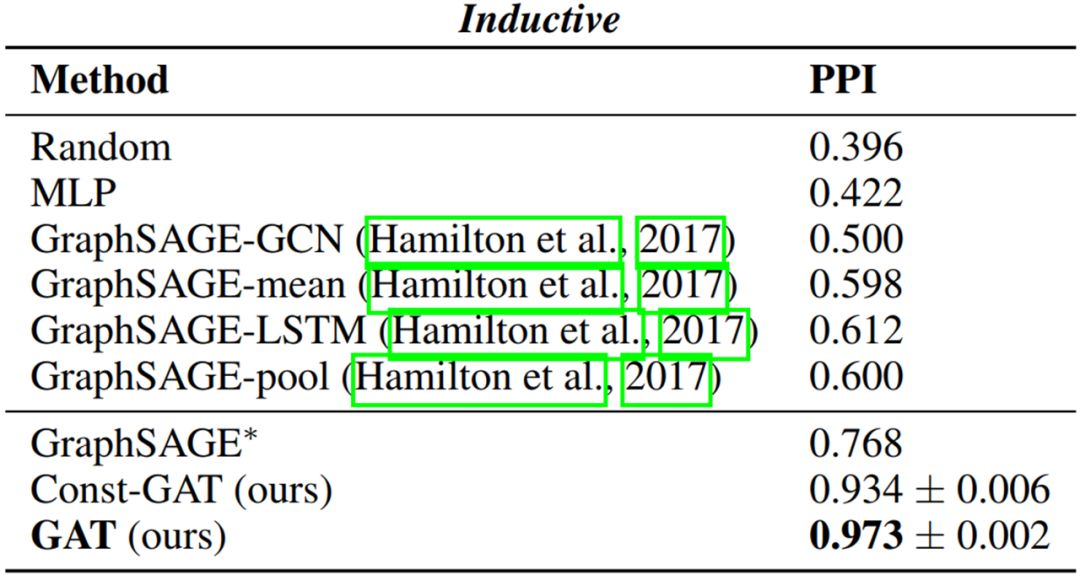
在这个实验中,
GAT
表现非常出色,相比于先前的方法具有非常大幅度的提升(
+20%
)。可见,
GAT
无论在T
ransductive
还是I
nductive
任务上都具有很大的优势和极强的适用性。
GAT
方法通过引入A
ttention
机制,使得每个节点可以感知其周围邻居的重要性,从而更有目的性地进行特征提取。
-
计算高效,不需要进行复杂矩阵运算(如矩阵求逆)。
-
相比于
GCN
[2]
,
GAT
可以为节点分配不同权重来作特征提取,其模型表达能力更强。
-
各节点共享的A
ttention
机制,
GAT
不需要访问整个G
raph
,并支持有向图和无向图。
-
GAT
可以同时关注某个节点的所有邻居,不需要对邻居节点排序、采样。
GAT开源代码:
https://github.com/PetarV-/GAT









