炸了!2017 Google I/O开发者大会北京时间昨晚召开,Google带来一整晚密集的信息发布,也再次彰显了Google在人工智能方面的实力。
从移动优先转变为AI优先的Google,在I/O大会的首日几乎所有话题都跟人工智能有关,量子位也对重点内容进行梳理如下。
核心要点:
-
第二代TPU发布,以及TPU研究云
-
为移动设备优化的TensorFlow Lite
-
AutoML强化算法,让神经网络设计神经网络
-
Google.ai上线,所有AI成果都在这里展示
相关数据:
-
月活安卓设备已达20亿部
-
5亿活跃的Google相册用户
-
Google地图每日导航超过10亿公里
-
人们每天观看10亿小时YouTube视频
以下是详细解读。
CEO:使AI触手可及
已经在Google工作13年的现任CEO Sundar Pichai首先登台。量子位把Pichai的开篇演讲摘要还原如下:

△
谷歌CEO Sundar Pichai
我们正在目睹计算领域的新转变:从移动优先到AI优先的世界。和以前一样,这迫使我们重新构想我们的产品,提供更自然、更无缝的交互方式。
所有的进步需要正确的技术架构。去年的I/O,我们推出第一代TPU,今天我们要发布下一代TPU:云TPU。新TPU对推理和训练都进行了优化。
我们认为,如果科学家和工程师们可以在指尖上,拥有更好、更强大的计算工具并展开研究,复杂的社会问题将有巨大的突破。
这也是Google.ai的驱动力。
我们希望让神经网络的创建变得更简单。现在设计一个神经网络非常耗时,所以我们创建了AutoML,可以让神经网络来设计神经网络。我们希望AutoML抵得上几个博士,并在三五年内满足更多开发者的需求。
看到AI已经开始逐渐实用令人激动,但真正要抵达AI优先的世界,还有很长的路要走。在AI普及化方面我们的工作越多,每个人就能越快受益。
Pichai上面提到一个新网站:
www.google.ai
。这个网站将用来展示Google和Google Brain团队的研究,包括各种有趣的实验等。

第二代TPU

第一代TPU在去年的谷歌I/O大会上发布,用于运行已训练完成的机器学习模型。而新一代芯片可同时支持模型的训练和学习。这款芯片带来了每秒180万亿次浮点运算的计算性能。
第二代TPU被称作“云TPU”,将通过谷歌云平台向所有人开放。谷歌云平台的开发者仍可以使用传统芯片,例如英特尔Skylake或英伟达Volta GPU去进行设计。
云TPU的推出再次表明,谷歌正在利用领先的技术,与公有云行业的其他对手实现差异化发展。
谷歌CEO皮查伊在I/O大会的主题演讲中表示:“我们希望谷歌云成为机器学习领域最优秀的云。这为重大进步打下了基础。”

为了使计算性能更强大,谷歌开发了订制的超高速网络,将64颗TPU连接至同一台机器学习超级计算机。这台超级计算机被称作“TPU舱”,带来了每秒11.5千万亿次浮点运算的能力,可用于训练单一的大型机器学习模型,或多个较小的模型。
为了证明TPU舱的性能,谷歌表示,如果想要训练最新的大规模翻译模型,那么使用32颗全球最强大的商用GPU需要一整天时间。作为对比,TPU舱只需1/8的性能,就能在6小时内完成对该模型的训练。
单个的云TPU和完整的TPU舱均支持谷歌开源的TensorFlow机器学习系统。
第一代TPU于两年前开始在谷歌公司内部部署,并被用在谷歌的多款产品,例如谷歌搜索、基于机器学习的谷歌翻译、谷歌语音识别,以及谷歌照片之中。
谷歌大脑高级研究员Jeff Deam本周表示,谷歌仍在使用CPU和GPU去训练机器学习模型。不过他预计,未来谷歌将越来越多地使用TPU。

与此同时,谷歌还发布了“TensorFlow研究云”。这是由1000颗云TPU组成的簇,在满足某些条件的情况下谷歌将免费提供给研究者使用。如果希望使用,那么研究者必须同意公开发表研究成果,或许还需要开源研究中的相关代码。
谷歌推出TensorFlow研究云的目的是加速机器学习的研究进展,并计划将其分享给哈佛医学院等学术机构。
对参与非公开研究的人士,谷歌计划启动云TPU Alpha项目。
TensorFlow Lite
在I/O上谈到Android的未来时,谷歌工程副总裁宣布,他们将推出一个专门为移动设备而优化的TensorFlow版本,称为TensorFlow lite。
用这个新框架,开发者可以创造更简洁的深度学习模型,让它们运行在Android智能手机上。不过,深度学习的训练过程还是需要在云端完成。
谷歌打算今年晚些时候推出TensorFlow lite API并开源。
Facebook今年F8开发者大会发布的Caffe2,和去年推出的Caffe2Go,也是这个思路。
让AI设计AI
谷歌想让AI变得更加“平易近人”,简化神经网络模型的建造过程是个好办法。
CEO劈柴哥在官方博客上说,现在,设计神经网络非常耗时,对专业能力要求又高,只有一小撮科学家和工程师能做。为此,谷歌创造了一种新方法:AutoML,让神经网络去设计神经网络。
谷歌希望能借AutoML来促进深度学习开发者规模的扩张,让设计神经网络的人,从供不应求的PhD,变成成千上万的普通工程师。
手动设计神经网络的难点在于,所有可能的模型都有着巨大的搜索空间,一个典型的10层神经网络,变化形式高达约10
10
种。
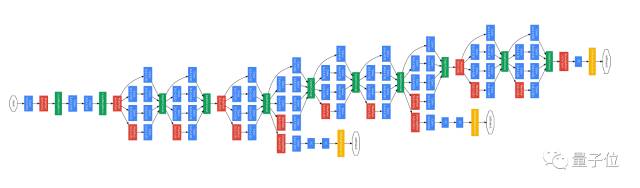
△
谷歌耗费数年探索出的GoogleNet网络架构
在AutoML中,一个主控的神经网络可以提出一个“子”模型架构,并用特定的任务来训练这个子模型,评估它的性能,然后,主控收到反馈,并根据反馈来改进下一个提出的子模型。
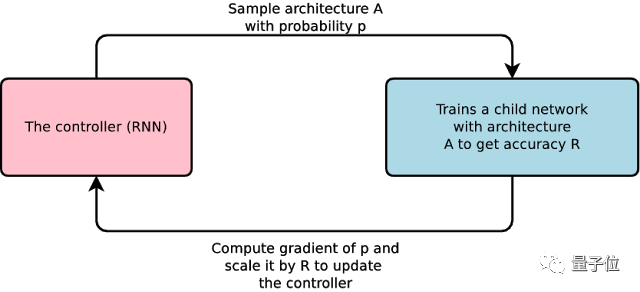
这个过程,简单来说就是:生成新架构-测试-提供反馈供主控网络学习。在重复上千次后,主控网络学会了哪些架构能够在已知验证集上得到更高的准确率。
谷歌用了两个经常作为基准的数据集来测试他们的模型,一个是图像识别领域的CIFAR-10,另一个是语言处理领域的Penn Treebank。在两个数据集上,自动设计的神经网络准确率都能与顶尖人类专家设计的网络媲美。
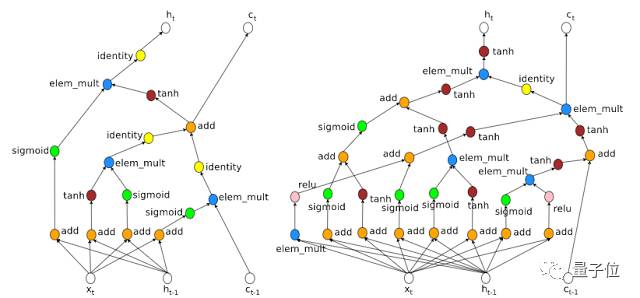
△
两个用于在Penn Treebank上预测下一个词的神经网络:左图出自人类专家之手,右图由算法自动设计
要深入了解自动搭建神经网络的算法,可以看看谷歌今年的两篇会议论文:
进化算法:
Large-Scale Evolution of Image Classifiers
https://arxiv.org/abs/1703.01041
Esteban
Real, Sherry Moore, Andrew Selle, Saurabh Saxena, Yutaka Leon Suematsu,
Quoc Le, Alex Kurakin. International Conference on Machine Learning,
2017.
强化算法:
Neural Architecture Search with Reinforcement Learning
https://arxiv.org/abs/1611.01578
Barret Zoph, Quoc V. Le. International Conference on Learning Representations, 2017.
其他
这次I/O大会还有很多其他有意思的看点,这里精选一些。
各种数字

月活安卓设备已达20亿部,还有5亿活跃的Google相册用户,每天产生12亿张照片或者视频。Google地图每日导航超过10亿公里。Google Drive云存储拥有8亿用户。人们每天观看10亿小时YouTube视频。
Lens