本文介绍了一种名为DELTA的高效方法,用于在三维空间中跟踪视频中的每个像素。该方法克服了现有方法的挑战,如计算效率低下和稀疏跟踪的限制,实现了大规模密集的三维跟踪。主要贡献包括高效的空间注意力架构、基于注意力的上采样器和对深度表示的全面实证研究。DELTA具有显著的优势,如在多个基准测试中实现最先进的精度,运行速度比现有方法快8倍以上。
DELTA是一种新颖的方法,能够高效跟踪三维空间中的每个像素,实现整个视频的精确运动估计。它克服了现有方法的挑战,如计算效率低下和稀疏跟踪的限制。其主要优势包括大规模密集的三维跟踪、高效率和最先进的精度。
DELTA的关键技术贡献包括高效的空间注意力架构、基于注意力的上采样器和对深度表示的全面实证研究。这些技术使DELTA能够在单次前向传递中捕获长视频序列中的数十万条三维轨迹,同时保持较低的计算复杂度。
为评估DELTA的性能,文章进行了多项实验,包括密集二维和三维跟踪结果的实验。实验结果表明,DELTA在准确性和运行时间方面都显著优于其他方法。此外,文章还展示了DELTA的实际应用效果,如在视频中的密集轨迹捕捉和精确运动估计。
虽然DELTA取得了显著的成果,但它仍有一些局限性,如时间处理窗口相对较短,可能无法跟踪长时间被遮挡的点,并且在处理少于几百帧的视频时表现最佳。未来的工作将包括克服这些局限性,并探索如何将单目深度估计研究的最新进展应用于改进DELTA的性能。
点击下方
卡片
,关注
「3DCV」
公众号
选择
星标
,干货第一时间送达
来源:3DCV
0. 论文信息
标题:DELTA: Dense Efficient Long-range 3D Tracking for any video
作者:Tuan Duc Ngo, Peiye Zhuang, Chuang Gan, Evangelos Kalogerakis, Sergey Tulyakov, Hsin-Ying Lee, Chaoyang Wang
机构:Snap Inc、UMass Amherst、TU Crete、MIT-IBM Watson AI Lab
原文链接:https://arxiv.org/abs/2410.24211
代码链接:https://github.com/xxx(soon)
官方主页:https://snap-research.github.io/DELTA/

1. 导读
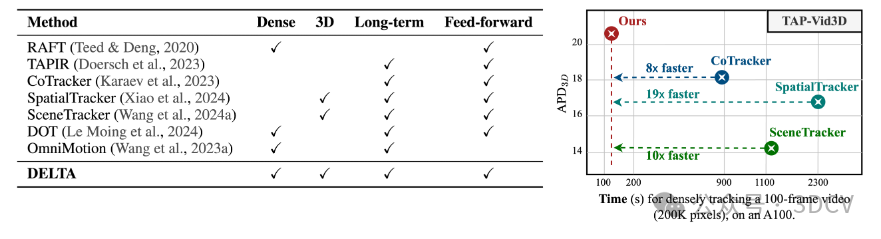
从单目视频中跟踪密集的3D运动仍然具有挑战性,特别是在长序列上以像素级精度为目标时。我们引入了DELTA,这是一种新颖的方法,可以有效地跟踪3D空间中的每个像素,实现整个视频的精确运动估计。我们的方法利用联合全局-局部注意机制进行低分辨率跟踪,然后利用基于变压器的上采样器来实现高分辨率预测。与受计算效率低下或稀疏跟踪限制的现有方法不同,DELTA提供大规模密集3D跟踪,运行速度比以前的方法快8倍以上,同时达到最先进的精度。此外,我们探讨了深度表示对跟踪性能的影响,并确定测井深度是最佳选择。大量实验证明了DELTA在多个基准测试中的优势,在2D和3D密集跟踪任务中实现了新的最先进的结果。我们的方法为需要在3D空间中进行精细、长期运动跟踪的应用提供了一个健壮的解决方案。
2. 动机
现有的运动预测方法难以进行短期、稀疏的预测,并且经常不能提供精确的3D运动估计,而基于优化的方法需要大量时间来处理单个视频。我们是第一个能够高效地跟踪每个像素在三维空间超过数百帧从单目视频,并实现最先进的精确度关于3D跟踪基准。
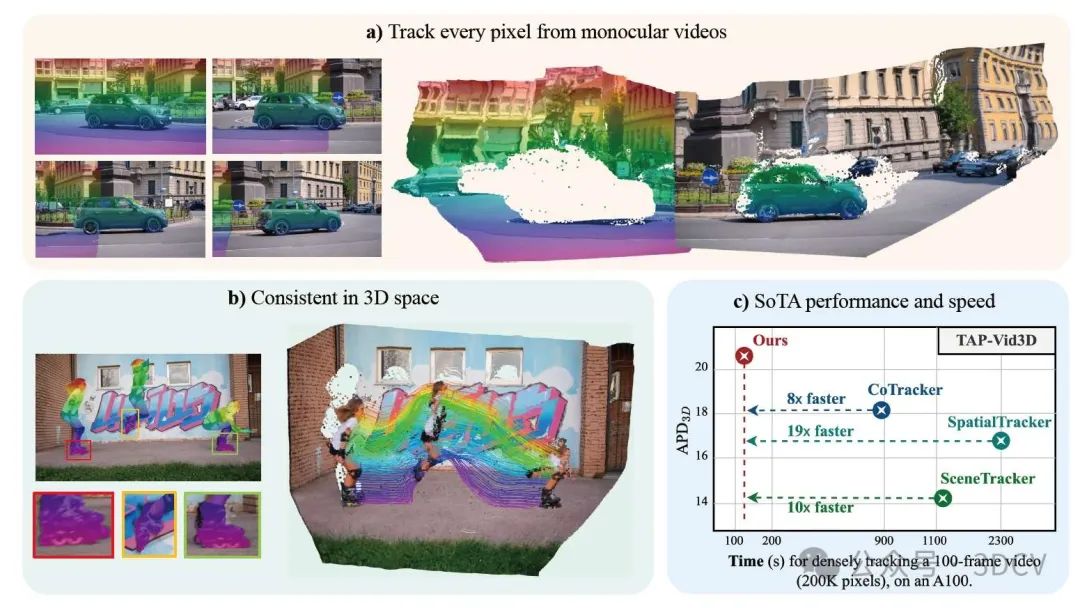
3. 效果展示
DELTA以前馈方式从视频中捕捉密集、长距离的3D轨迹。

4. 主要贡献
我们的关键设计选择包括:
• 一种高效的空间注意力架构,该架构能够捕获密集轨迹的全局和局部空间结构,同时保持较低的计算复杂度,从而实现密集跟踪的端到端学习。
• 一种基于注意力的上采样器,经过精心设计,能够提供高分辨率、准确的跟踪,并具有清晰的运动边界。
• 对各种深度表示进行了全面的实证分析,结果表明,对数深度表示能够获得最佳的3D跟踪性能。
这些设计使DELTA能够在单次前向传递中捕获长视频序列中的数十万条3D轨迹,对于100帧的视频,处理过程在两分钟内完成,比现有最快的方法快8倍以上,如图1所示。DELTA在2D和3D密集跟踪任务上进行了广泛评估,在CVO和Kubric3D数据集上均取得了最先进的结果,AJ和APD3D指标提升了10%以上。此外,它在传统的3D点跟踪基准上表现也具有竞争力,包括TAP-Vid3D和LSFOdyssey。
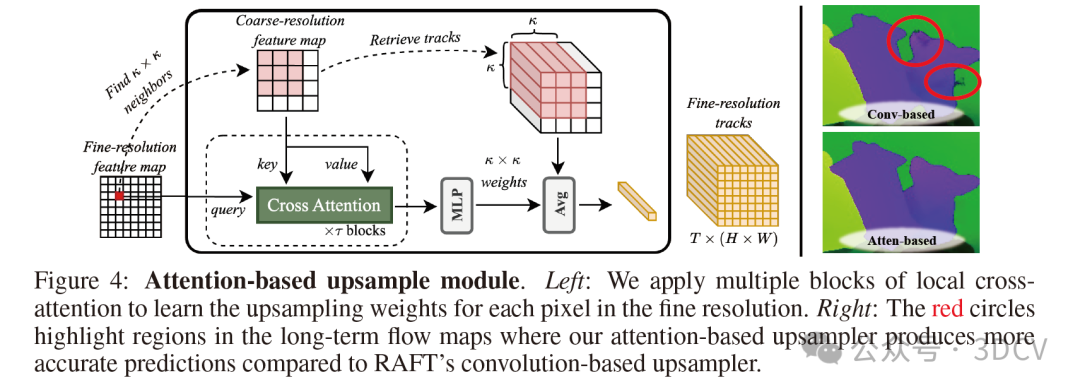
5. 方法
为了进一步降低计算成本而不牺牲准确性,我们采用了光学流中常用的策略:先在降低的空间分辨率下进行复杂计算,然后通过更轻量的层进行上采样。如图2所示,我们首先以原始分辨率的1/r²进行密集跟踪,从而将计算成本降低1/r²。然后,将降低分辨率的轨迹上采样到全空间分辨率。
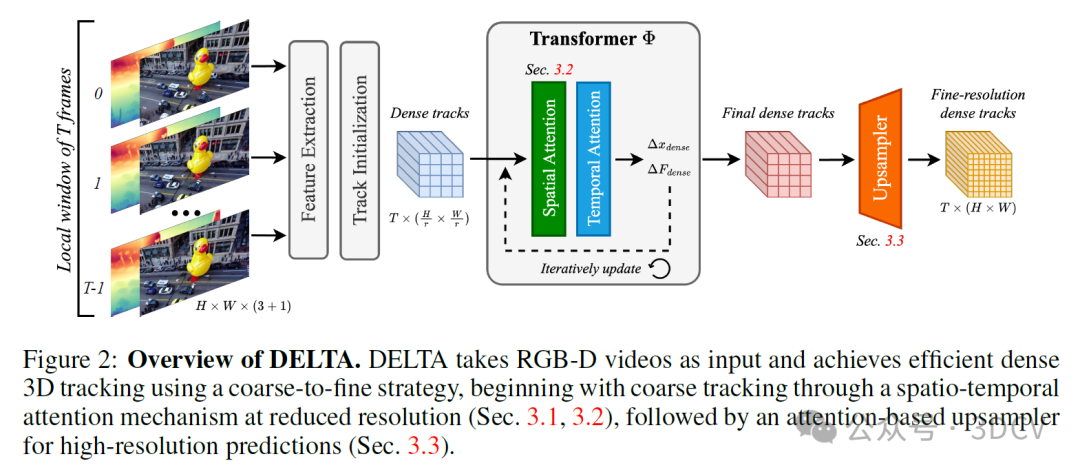
如图3所示,如果一帧内对所有标记(token)盲目应用空间自注意力,其复杂度为O(TN²),其中N为轨迹数量,这对于密集跟踪来说是不切实际的。为了降低复杂度,CoTracker引入了虚拟轨迹标记(token),这与DETR引入的可学习标记在概念上相似。它在轨迹标记和少量虚拟轨迹之间来回进行交叉注意力运算,而自注意力仅在虚拟轨迹内部应用。这可以将复杂度降低到O(TKN + TK² + K²T),假设虚拟轨迹的数量K远小于N。然而,这一降低仍然不足以实现高分辨率视频中每个像素的端到端跟踪。虽然在实际操作中,可以将像素分成不相交的组,并在每个组内分别进行注意力运算,但由于忽略了不同组之间标记的交互,这一策略是次优的。
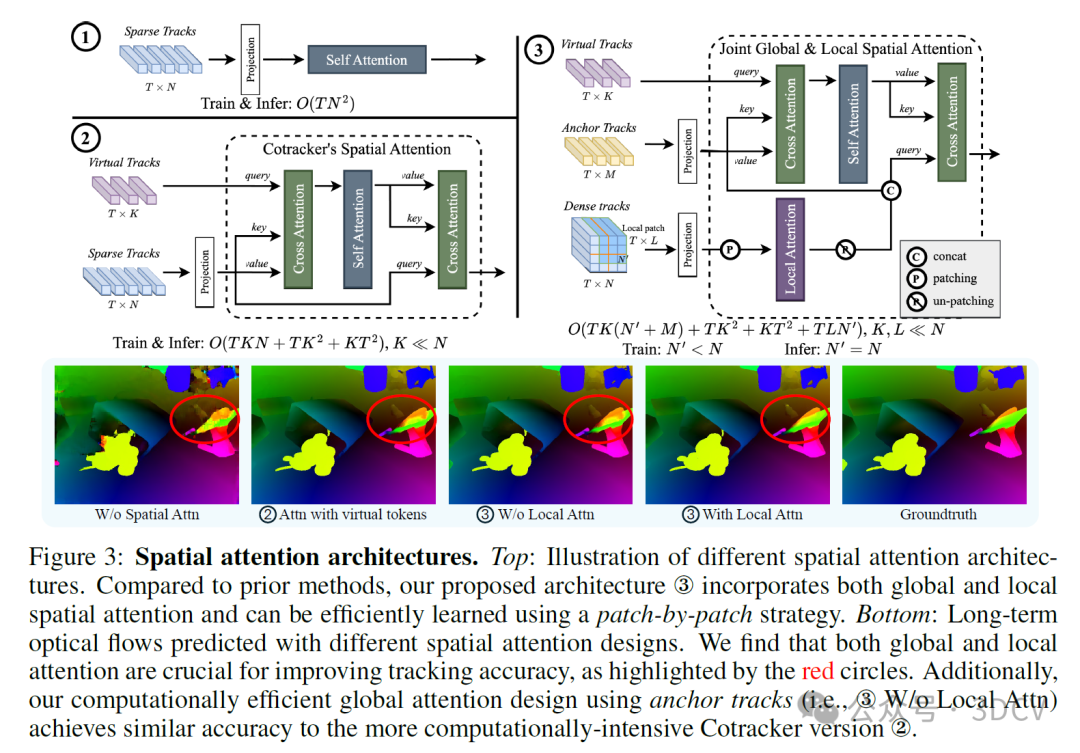
在从前一个模块中以降低的空间分辨率Hₜ×Wₜ提取轨迹后,我们的下一步是在单次前向传递中将它们上采样到全分辨率H×W。在光学流的背景下,一种常见的上采样方法是将每个精细分辨率像素的流表示为在粗分辨率中估计的最近邻流的凸组合。组合的权重是通过卷积神经网络学习的。相反,我们引入了一种基于注意力的上采样机制。我们在实验中证明了其有效性(见图4)。