听闻微软出了一款自动化测试工具Playwright,功能类似Selenium,Pyppeteer。又听闻它可以自动生成代码……


从此不写代码了
二话不说,先安装。
pdm init #搞个虚拟环境先
pdm add playwright
pdm run playwright install #安装浏览器驱动
然后,从此码农翻身的时刻到来了:
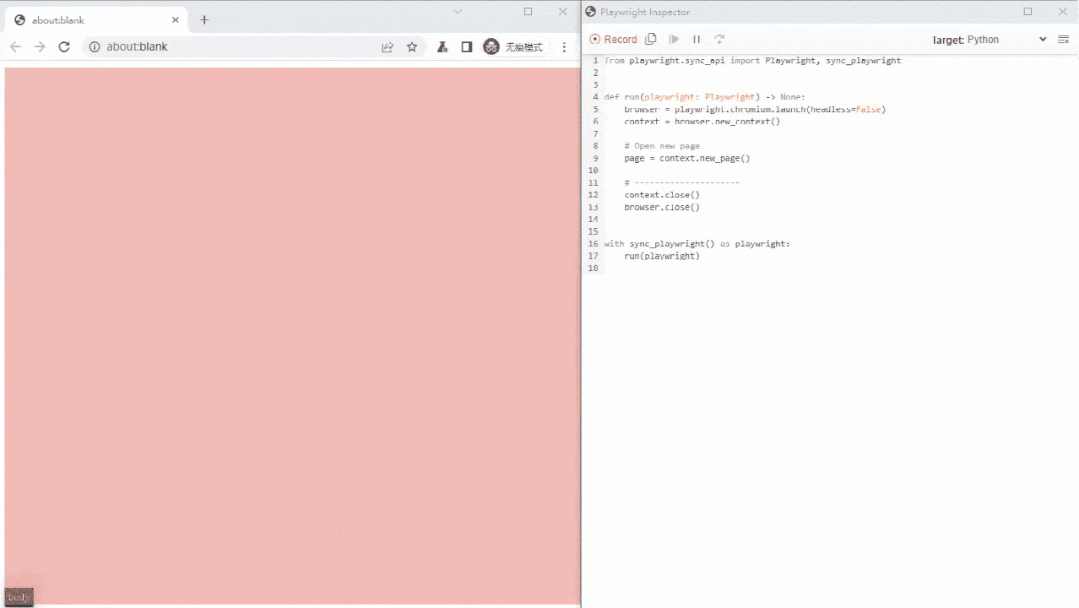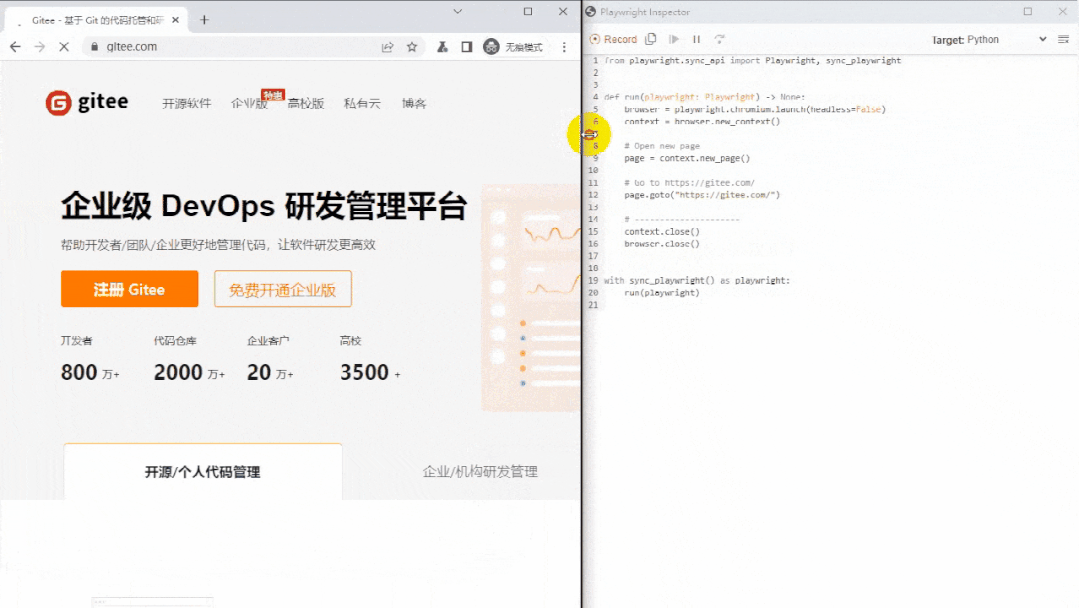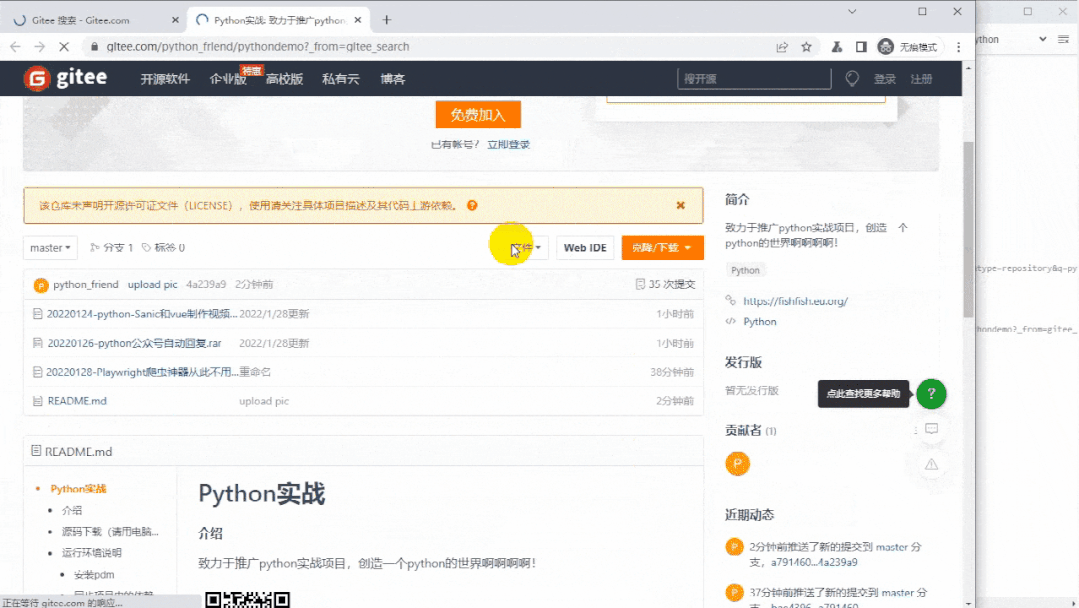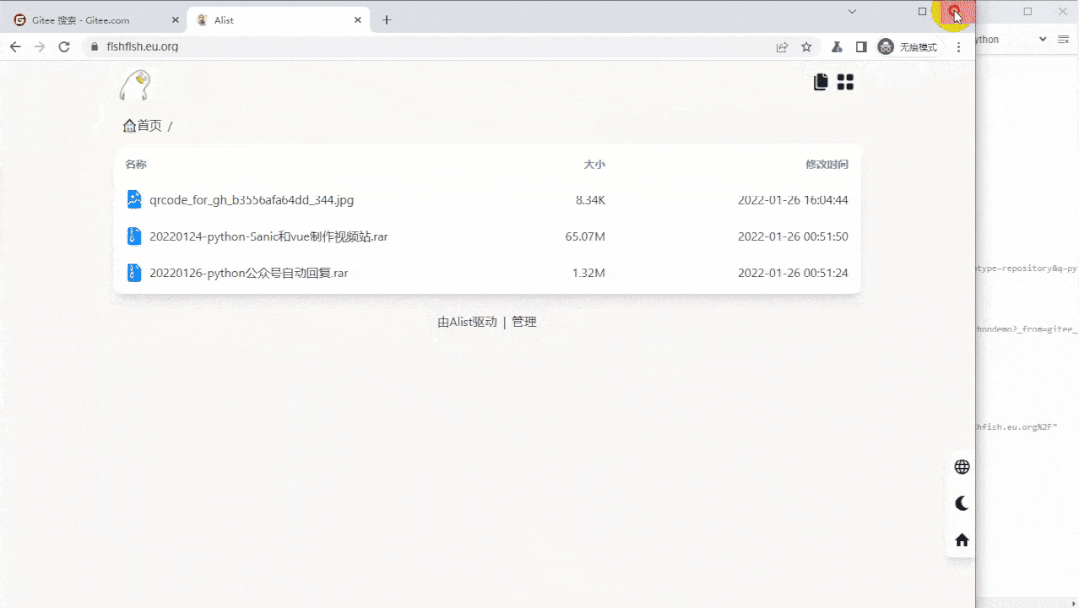
pdm run playwright codegen -o autorun.py
左边是浏览器,右边是同步生成的代码。
生成的代码:
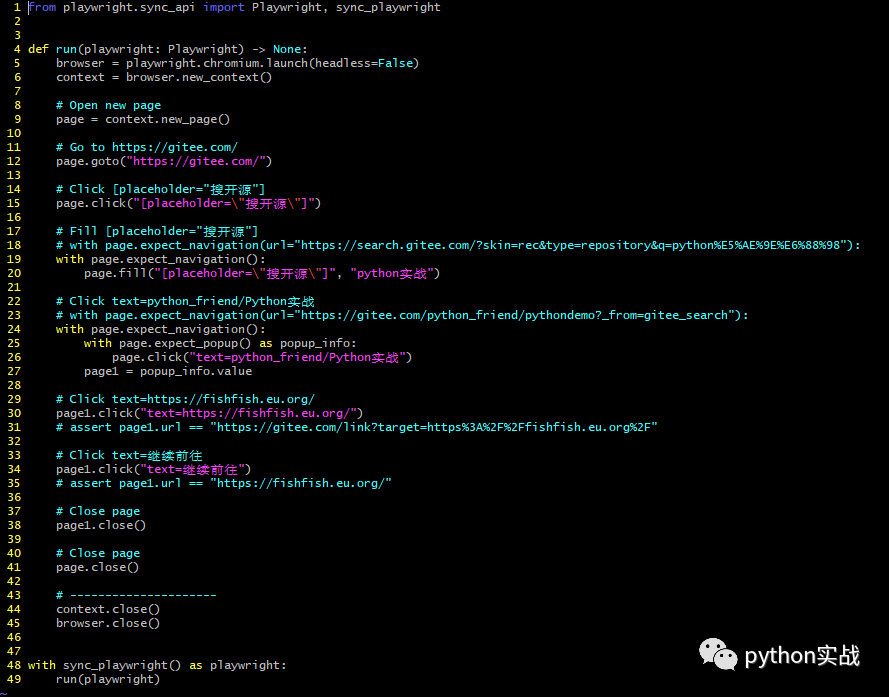
好家伙!直呼好家伙!本文结束,完结撒花。
抓取微信文章保存为markdown
还是干点实际的事情吧。
例如用来保存微信公众号文章,输出成markdown。
获取页面内容
def get_html_content(html_url,html_filename,step):
'''
获取html页面的内容,相当于ctrl+s
:param html_url: 抓取的url链接
:param html_filename: 输出的html文件名
:param step: 调整页面滚动速度,默认为500
'''
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto(html_url)
page.wait_for_load_state('networkidle') #等待网络加载完毕再进行操作
html = page.content()
with open(html_filename,'w',encoding='utf-8') as f:
f.write(html)
browser.close()
处理懒加载图片
经过上一步,发现一个bug,保存的html文件里没有把懒加载的图片给保存下来。
查看官方文档无果,只好添加一段javascript手动执行滚动页面。
# get_html_content.py
def get_html_content(html_url,html_filename,step):
'''
获取html页面的内容,相当于ctrl+s
:param html_url: 抓取的url链接
:param html_filename: 输出的html文件名
:param step: 调整页面滚动速度,默认为500
'''
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.set_default_timeout(50000)
page.goto(html_url)
page.wait_for_load_state('networkidle')
#设置滚动坐标初始位置
start_position = 0
#获取整个页面内容高度
scroll_Height = page.evaluate('window.document.body.scrollHeight')
while(start_position<scroll_Height):
#不断增加坐标
start_position = start_position+step
position = str(start_position)
#构造javascript
run_scroll = 'window.scrollTo(0,'





