
文章作者:杨楠楠 等
内容来源:《数据产品经理:实战进阶》
导读:以搜索为代表的策略产品经理,日常工作中一样会面临非常多的业务需求和badcase,有目标地满足需求和解决问题是容易的,但往往会面临另一个问题:当没有人提出具体需求时,怎样挖掘新的需求,推动搜索系统正常的迭代和运转?回答这个问题的过程,也是展现一个策略产品经理的思维方式和工作方法的过程。根据实际工作经验总结、需求的挖掘和系统的维护,可以从四个方面入手:从搜索策略的整体架构入手,从用户需求入手,从具体问题入手和从业务发展入手。其中整体架构是策略产品的独有部分,也是我们接下来花大量笔墨着重介绍的部分。
从整体架构入手是一个从下到上分层挖掘需求的方法。
架构是最终效果的基础,像一个房子的骨架,必须牢固无误才能进行上层建筑的搭建,同时又像一个结构精密、环环相扣的仪器,必须将每一个环节做到最好,才能保证最终运行状况最佳。从整体架构入手的意思就是做好巡检人,不断从每一个策略层和环节入手优化。
系统的架构主要依赖于技术架构,我们需要明确每一层是如何运转的,可以解决什么问题,达成什么效果,了解其原理和作用。但是在挖掘需求的时候,考虑得最多的是如何让每一层的效果更加符合业务特点和用户需求。
图1所示是一个搜索架构,我们以此为例,看如何从下到上分层优化。
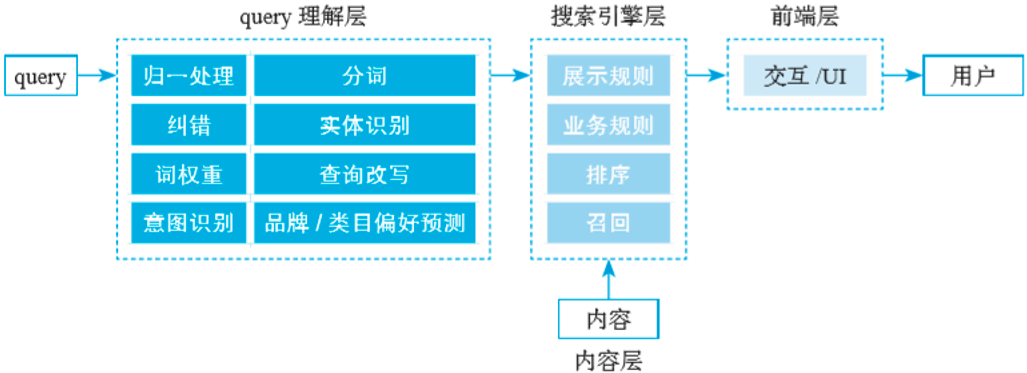
由图1所示的架构图可知,一个完整的搜索的流程基本包括query的输入、query的理解、搜索引擎内容召回、搜索引擎的排序、产品前端展示、最终呈现到用户面前。
1. query理解层优化
query理解层的主要作用是对query的处理、识别和理解,完成用户需求的解析,输出给搜索引擎,完成接下来的检索部分,也就是我们常说的NLP(自然语言处理)。NLP能对所有的文字语言进行识别和理解,所以目前在互联网公司的划分中,NLP往往作为搜索以外的独立团队,负责搭建基础的NLP功能,向各团队提供横向的支撑。以搜索为例,涉及的理解层的重要功能包括归一处理、分词、纠错、改写、实体识别、意图识别和品牌类目偏好。
我们通过一个实际的例子讲述一个词进入query分析层后,会对其进行哪些处理和计算。
输入query:“好yong洗发水、”。
通过人工判断,用户想要输入的其实是“好用洗发水”,其中“用”字可能是因为输入过程中的某些操作,变成了拼音,且多了一个“、”。“好用洗发水”里有两个关键词,一个是“好用”,一个是“洗发水”,很明显这两个词中“洗发水”才是目标的关键,用户想要找的是洗护品类中的洗发水品类。然后我们再来思考,一个电商平台中有那么多的洗发水,哪一款才是用户想要的呢?我们自己在挑选洗发水的时候最看重什么呢?答案应该是牌子,也就是说用户在挑选洗发水的时候非常看重品牌,这意味着我们在最终呈现结果时要注意把用户喜爱的品牌优先展示。
以下就是这个例子的query理解全过程。
1)把无意义的“、”去掉,就是归一过程;把“yong”纠正为汉字“用”,就是纠错。
2)“好用洗发水”按照汉语习惯断句为两个词“好用/洗发水”,即是分词。
3)分词后判断“好用”是修饰语,而“洗发水”才是实体,这就是实体识别。
4)在匹配过程中,洗发水类目实体词的权重明显高于修饰语,这就是权重计算。
5)判断洗发水是洗护品类下的洗发水类目商品,这是意图分析。
6)在洗发水意图之下计算哪种品牌才是用户最倾向的,这就是类目预测。如果用户的意图是“水”,而水对应“矿泉水”“护肤品的精华水”等多种类目,我们也需要进行类目的预测。
这个例子很好地呈现了query理解层到底在做什么,那么在这个环节中,产品经理可以做什么呢?首先需要做的是全面分析问题和逐步优化,这里可以尝试不断自问自查。
这样在没有遇到需求输入和明显问题反馈的时候,我们依然能够通过不断的case分析,从基础上进行详细优化。
我们再次举其中“类目偏好预测”的例子,拆解产品经理从中可以做什么工作。
第一层,依靠规则从无到有。没有做过意图识别—品牌/类目偏好预测的搜索,只靠文本的匹配,相关性会很低,搜索“水”,可能召回的是含有“水”字的某些水果,这时候就需要提需求,完成从0到1的识别。这个从0到1的过程用规则就可以完成,例如只要完全匹配到“类目表”中的类目,便判断为其对应的类目意图。如果匹配不到再来统计搜索该query下的后续相关行为分布,统计其中各类目占比,用这个占比粗糙地代表各品牌和类目的权重。
第二层,从有到提升准确率。完成之后,从线上回收数据,可以继续想,如何才能让识别和预测更加准确,用全局热度的判断方式是不是过于粗暴,如何通过完善规则的方式进行优化,例如之前只用了点击行为,是否可以引入下单行为?
第三层,配合搭建预测模型,完成从规则到算法的迭代。当规则过多、维护复杂且提升达到天花板的时候,就要考虑用算法解决问题,这时候产品经理需要提供训练模型的相关特征,或者直接给出标注样本,并且验收算法的准确率和召回率,这个过程也是算法产品经理的常规工作之一。
第四层,基于算法框架,不断寻找优化点。算法跑通之后,产品经理仍然要不断收集线上case,分析是否达到了预期的效果,不断反馈badcase,补充业务规则。这就是算法的日常维护。
以上四层是展示产品经理在“意图识别—类目预测”这项工作中的几种状态,每一层都不是逐一演化、不可跳跃的,完全可以在没有规则的情况下直接采用算法,产品经理在这个过程中不变的工作就是把握原理和业务诉求,其他的则随机应变。
2. 搜索层优化
搜索引擎部分便是策略经典的“召回→排序→精排→业务规则→展示规则”流程。
① 召回:
最简单的召回为命中即召回,这对于垂类行业短query已经足够,而对于中长字符串的召回,为了保证召回结果相关性,还需要定核心词求交等规则。
以资讯类内容为例,一篇文章词汇非常多,数以亿计的文章汇总之后,需要被检索的词汇量便难以计算,这给检索速度和系统的性能带来了极大挑战,所以为了提升检索速度,在对内容召回之前会建立内容的倒排索引。
这里的索引是内容的目录,倒排索引可以简单理解为离线维护的词和物品的关系表,是以物品的单个分词结果为目录,记录收录该分词结果的全部item,当我们检索一个词的时候,首先找到这个词,再从词入手查询被引用的物品,这样就能实现快速查询的目的。
为了提升效率,不是所有的字段都会参与倒排,以资讯类产品为例,资讯的标题、作者、正文部分是需要建立倒排索引的,而资讯下方的评论则不会参与。
② 排序与精排
搜索中的排序包含相关性、时效性、权威性、商业价值以及个性化等维度。
召回层和排序层的日常优化方向应该是最直接的,简单概括就是两个字:“全”和“准”。“全”意味着召回的内容要丰富全面,对应的指标是召回率;“准”意味着准确,对应的指标就是准确率。接下来我们详细看一下如何提升这两个指标。
召回率:
要求召回内容全面,但如何才能召回全面呢?优化大方向就是不断新增召回方案,由一路召回不断完善为多路召回,在某一范围内,召回路数越多,召回内容越全。
现在搜索常用的召回方案为文本命中召回,例如搜索“衣服”,会召回标题或简介中含“衣服”文本的物品,这是最为基础的召回方案。但因为用户的表达往往不够规范,同时物品的信息也未必全都是标准的文字信息,所以还需要补充很多召回策略。
例如标签召回,将物品重要信息通过人工或者机器的方式抽象成标签,再通过标签进行召回。
例如协同数据召回和embedding召回,这两种召回方式采用的是推荐的思路,前者是根据用户的交互行为,召回相似物品;后者是针对query和物品单独做向量,计算向量的相似度,进行临近召回。这两种召回方式都是现在常用的方法,尤其是后者,在搜索和推荐中效果显著。
例如多模态召回,除了基本的文本信息,内容的形态也越来越多,图片、视频、音频等都非常常见,所以除了文本之外的其他模态召回,也是可以探索完善的。
准确率:
要求召回内容准确,搜索的形态往往是返回多条数据,所以准确率通常体现在排序上,排序越往前的越需要准确,排序非常滞后的,用户曝光概率较小,可以在评估准确率的时候截断不作参考。
排序的方法无非规则、机器学习和深度学习几种,在排序上优化思路并对症下药,规则排序不断探索更多的排序因子、更合理的排序权重;机器学习分析更多排序特征;深度学习解释较为困难,对应的可以不断找badcase做优化反馈。
F1-score:
F1-score是统计学中用来衡量二分类模型精确度的一种指标,它同时兼顾了分类模型的准确率和召回率。F1-score是模型准确率和召回率的一种加权平均,F1-score=2pr/(p+r),最大值是1,最小值是0。其中p代表precision,即准确率;r代表recall,即召回率。
召回和排序作为搜索和推荐业务的基础,更多是研发工程师需要投入大量精力优化的,产品经理的参与形式更像是一块砖:研发工程师经验丰富,则产品经理可以适当放手,更多转向业务和配合;研发工程师思考有遗漏,产品经理则要义不容辞地参与到策略和算法中。虽然业界一直在探讨策略中产品的边界,但其实只要保证一切以最终结果为导向来工作就能获得不错的收获。
③ 业务规则
业务的需求往往很具体,仍以电商产品为例,今天需要给某个商家增加权重,明天需要给某些商品降权,或者直接过滤,或者要求展示的样式更加丰富,可以运营的空间更多,等等。综合整理各类需求,基本上可以按照以下几个方向来处理。
流量分配:例如给某一类内容做流量的倾斜,流量分配的方法有很多种,定位置、定比例、定数量、定权重。
动态通道:对于大量、长期但具体需求不固定的,可以设置专门通道,动态触发。
特殊干预:特殊干预属于粒度最细、最灵活的规则,可以支持query—item—位置—参数的详细具体配置。
业务规则层的优化目标可以概括为,将具体业务需求与通用的召回排序剥离开来,分层抽象处理为多类概括类型,并以灵活可配置的方案实现流量分配合理,满足用户需求和业务价值的平衡。
④ 展示规则
展示形式的变化重点在于两点:一是必要信息的展示;二是解决单一列表引起的用户视觉疲劳。对于前端展示规则的制定和优化,需要努力从以上两个方向考虑,具体如下。
3. 内容层优化
纵观当前互联网头部产品,例如微博、知乎、淘宝等都是先沉淀大量内容,后衍生搜索,慢慢培养出“微博搜热点”“万能的淘宝”“有问题知乎搜一下”等固定的用户认知,其中更有“微博热搜”这项全民产品功能,包罗当下所有一手热点;而以技术著称的搜索巨头,以浏览器占据流量入口,慢慢变为一款工具,更多满足用户有明显意图的临时搜索需求,用户用完即走,非常被动。
所以说决定搜索上限的并不是算法和策略,而是内容。
国内互联网在头条系的剧烈冲击中,几乎全部完成了以消磨时间为产品目标的转变,从中也能够看到各家对内容生态建设的重视程度。各大技术主导型的搜索产品紧急行动,把业务重点放在内容生态的建设上,以UC为代表的各家浏览器在首页做推荐,百度也在培养百家号,将大量的资源向其倾斜……以上这些举动都是为了从根本上填充优质内容,弱化搜索产品的工具属性,打造自己的产品壁垒,通过优质内容吸引用户。
内容的定义非常宽泛,不仅仅是资讯和文章,对于社区产品来说,评论也是内容;对于视频产品来说,长短视频都是内容。内容的生产方包括PGC、UGC以及界限越来越模糊的PUGC。但无论内容的载体、形态和生产方如何,对于内容的评估指标均有相似性,丰富度和质量度是监控重点。
① 丰富度及生产速度
内容的丰富度体现在数量上,包括存量绝对量和增量速度。以抖音为例,视频数量和日新增量是其核心指标。除此之外,对于很多标品产品,丰富度的评估很重要的一方面是跟行业内和竞品平台对比。
以“毒”这款产品经典的潮鞋品类为例,要跟潮牌鞋的整个行业来对比,确定缺失的SKU,尤其是其中的经典款和新款,这部分头部SKU是整个产品流量的重要来源,这个时候单纯地关注SKU数量意义就小了。
② 质量度
只有优质的内容才能吸引用户,在关注量的基础上强调质也很重要。
以知乎为例,虽然每个人都有评论和写文章的权限,但只有优质问题和优质回答才能为产品带来口碑,如何鼓励用户持续生产优质内容,是其内容生态建设的重点。
③ 热点时效
在内容生态建设中,热点时效是全部搜索产品的重中之重,需要通过外部竞对监控、站内搜索热度变化监控、同类内容关键词监控、重点内容人工监测,实现热点的识别、发酵和下发。能否第一时间抢到热点内容,是衡量一个平台或产品能力的重要维度。
④ 用户需求满意度
丰富度、质量度和热点是单纯针对item进行客观评估,用户需求满意度的评估是在此基础上,评估item与用户需求匹配度,这点在搜索上的体现非常典型。搜索会监控用户输入的查询词,其中越高请求代表用户需求越大,相应的结果品类和数量必须更多更丰富,而对于低需长尾品类,在丰富度和质量度上的要求就可以适当降低。
从上述指标中,我们就能看出对于内容的优化方向可以用“全”“优”“新”“热”四个字来概括。搜索并非内容的直接生产方,要在内容建设的环节中做好需求收集和反馈的角色,并且保证整个内容生态里的新热信息能够及时下发,这两点是除了正常的内容分发之外,搜索的重要任务。
4. 前端产品层优化
① 根据用户搜索习惯确定优化方向
前端产品设计遵循用户基本的搜索习惯,用户的搜索习惯往往包含以下几种。
用户搜索之前,意图不明确,需要更多的决策信息和方式搜索。
用户搜索中,已经可以捕捉用户意图,为了快速完成搜索,需要给出搜索提示。
用户搜索后,即已经获取大量符合初筛规则的信息,需要更加快速地定位到目标。与之对应的优化方向也显而易见。
搜索前,给用户热门内容或个性内容做引导,对应的常规产品是输入框内的默认词、中间页的热搜榜和热搜推荐等。
搜索过程中,点击输入框开始输入,需要在此过程中展示提示结果(sug),便于快速完成检索。
搜索后,通过产品设计缩小用户检索范围,并且根据用户需求变化设计搜索结果长列表,做好承接和兜底。
② 搜索产品中重要的场景设计
搜索产品和普通C端产品一样,也是有很多细分场景的,只不过因为搜索的策略隐藏在输入框后,表达并不直观,这里列举几种典型场景划分方式和优化思路。
按照需求分布。可分为头部需求场景、腰部需求场景和长尾需求场景,头部需求存在量大而且query表达较为规整的特点,越到长尾需求越分散,query也越多样性,对应到的NLP和召回排序策略也可以进一步拆分细化。
按照query类型划分。以电商产品为例,用户意图划分为衣服、3C产品、食物等,不同的意图也可以对应到不同的场景,例如衣服场景下的信息展示更强调样式和美观度,而3C产品的信息展示更突出品牌和参数。
按照召回效果划分。可分为普通场景、少无结果场景和低转化率场景,其中后两者是搜索中最重要的场景,需要给用户足够的提示和内容承接。
以少无场景为例,可以通过推荐给予更多相似内容填充结果。可以根据query相似度计算,给出推荐的相关搜索,同时在前端做好文案提醒。
当然还有更多的划分方式,重点是挖掘不同场景的特点,用户需求和问题,进而针对性地提出优化方案。
这样拆解下来,优化的内容就相对清晰了。以归一层为例,之前没有做字符过滤的需要过滤,没有做简体繁体转化的可以抓紧完善,做过的就继续提升识别率、准确率。
再比如意图识别,对于综合搜索,通过用户输入query的分析,发现近期对于音乐的需求增长明显,而音乐类的意图识别较差,则需要单独针对音乐品类进行着重优化,如何优化需要继续分析,用户query中包含音乐歌曲名称、歌手、作词、作曲以及大量与某一音乐节目相关的关键词,可见音乐搜索意图的增长来源于热门综艺的带动,这时候就需要单独对综艺以及其中重点的片段进行挖掘计算,以提升综艺相关query的意图识别准确率。
再举一个纠错的问题,某些潮牌电商,其商品的品牌多起源于国外,所以存在大量中英文混杂的query,这时候纠错就不能只做中文纠错,还需要把英文的纠错列为优化重点。
日常迭代来源于用户的需求—这条定理对全部产品来说都是通用的,需求分析、场景挖掘、定位问题、提出解决方案,这条优化路径大家都不陌生,在策略中也是一样的。用户需求的反馈按照直接程度,可以划分为显性表达和隐性表达,仍然以搜索为例,显性表达又可以划分为直接反馈和query。下面来一一介绍。
1. 用户的显性表达—直接反馈
当用户有诉求或遇到问题时,会通过某些途径直接表达反馈,这是最典型的显性表达,线上咨询、客服服务和投诉都属于直接反馈的方式。产品要定期收集和分析用户反馈的内容,总结当前的问题作为需求,对于搜索来说,也要通过产品设计,增加用户需求显性表达的收集通道。
例如微信读书的搜索,在搜索页底部做了一个悬浮提示“没搜到?把你想找的书告诉我们”,通过用户的主动反馈,了解用户对搜索内容侧的需求,不断完善填充内容。
用户的显性需求非常直接易懂,是需求的重要来源之一,但是也要考虑到一个问题,能够主动表达自己诉求、使用反馈或者投诉渠道的用户多为活跃用户,他们在全量用户中仅占小部分,而绝大部分用户都属于沉默用户,使用产品,但是从来不主动打分和提要求。这让显性需求的收集方式显得片面局限,因此需要其他方式辅助补充。
2. 用户的显性表达—query
query需求分析是搜索特有的分析方式,因为搜索是为数不多用户会主动输入明确信息的系统。推荐需要靠用户的行为、社交、地域等多维度信息来猜测用户兴趣,相比这下,搜索可以直接记录用户输入需求,就显得异常方便。
举个例子,某电商产品某段时间,用户的搜索query日志中,出现了大量的“××同款”,追溯原因是因为这位明星的某部剧上映,点击率高,深受粉丝喜爱,水涨船高,带动了衣服的需求。对于这个例子,背景和需求的定位都非常明显,接下来只需要辅以合理的落地策略。
3. 用户的隐性表达—用户行为
即便有query输入信息作为分析依据,也是不够全面的,我们还需要通过用户的行为来了解用户的需求。用户行为分析的方法、工具和展示形式非常多,我们以一条用户行为分析为例,从最细粒度展示需要从用户行为分析中获取什么信息,所有的用户行为分析汇总,就是我们要的最终结论。
抽取一条用户行为日志,整理如下:
query1_面霜,query来源_历史搜索词,结果页浏览深度_100,点击商品_无,query2_雅诗兰黛面霜,query来源_手动输入,结果页浏览深度_20,点击商品_雅诗兰黛油性面霜,点击位置_2,点击商品_雅诗兰黛干性面霜,点击位置_3,是否下单_是。
注意,以上是通过日志整理出来便于分析的假数据,商品信息为虚假信息。
通过这样一条用户行为,我们可以得到以下信息。
用户变更搜索词,从“面霜”变更为“雅诗兰黛面霜”,说明用户的类目需求是固定的,但是对于品牌的需求是不断具体明确的。
第一次浏览深度为100,但是点击商品为0,说明用户对第一次搜索的结果不满意。
第二次关注的商品有两个,但是最终成交下单的是第二个,与第一个对比,商品的类目品牌都一致,但是护肤品的性质不同,说明后者比较符合用户的肤质。
从一条用户行为数据中我们就可以得出这么多信息,并且有与之对应的解决方案。
如何让用户在不需要变更query的情况下,快速定位到商品。为了减少用户品牌的query补充,需要对搜索结果做类目预测,最简单的类目预测方式是统计用户在某一个query下商品品牌的点击量及比例,按照这个比例分值做不同品牌商品的召回或者排序,用以解决品牌问题。
既然定位到用户在美妆护肤品类下非常关注的参数有肤质,那么可以继续调研联想,是否还有用户关注度较高的其他参数,能否将这些直接作为结果页的筛选项,帮助用户快速定位所需商品。
以上就是一条最为基础的用户行为分析,而一个需求的抽象是建立在大量的用户行为分析基础上,但是万变不离其宗,做好一条分析,是做好全部分析的前提。
1. 日常数据监控
每个产品都有完整的数据指标体系,可以监控整个系统是否异常,这部分分析方法在第2章已详细说明,这里不再赘述。
2. 专项分析
专项分析与日常监控不同,其意义在于“重点问题重点分析”。自己负责的产品模块中哪些属于重点问题,这应该是每个产品经理需要第一时间明确的事情。仍然以电商搜索为例,梳理自己的“重点专项”。
某年因为商家合作模式调整,导致众多商家退出平台,商品类别和总量都大量减少,这时候通过最简单的经验判断,也能确定这对搜索的流量和转化都会有影响。因此需要专门针对内容的缺失对搜索影响进行分析和量化,确定流量和收入的损失具体是多少,需要按照损失量级做一些拉活或促销活动。
从数据和具体的问题入手分析,都是基于现状的分析,基于现状分析最大的局限性在于很难快速捕捉整个行业的最新动向,从微小的变化里发觉并抓住未来机遇。如果陌陌只在不断打磨现有产品的路上飞奔,可能会成为更好的陌生人交友软件,却会错失短视频风口,无法顺利转身,成为短视频和直播的巨头。
对行业有分析,对业务有整体思考,也是一个初级产品经理向高级产品经理进阶的必备技能。这个过程的训练,最简单直接的方法是分析竞品,高阶一点的是关注和分析行业动向,再高阶则需要靠沉淀的信息和果敢决策,能谋善断,才能抓住别人无法抓住的机遇。这方面并没有速成的方法和固定的公式,是考验每一个产品经理能否走向更高层次的重要一步。
搜索整体架构是大厦之基础,用户需求是攻坚目标,具体问题是破局关键点,业务发展是长期蓝图,经常从这四个方面提取需求,复盘项目,才能保证全面的提升。
——文章来源:《数据产品经理:实战进阶》 机械工业出版社
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个三连击呗~~

福利时间:本期活动为大家带来5本正版新书。在文末留言区留言谈谈你对数据产品经理的看法,2020年10月15日20点前,我们将在评论点赞超过5的留言中选取5个最有意思的评论,赠送正版图书1本。赠书由机械工业出版社华章公司提供,在此表示感谢。注:等不及的小伙伴也可以点击下面的购买按钮直接拿下哦。会员推荐:
DataFun会员计划重磅发布!多重权益加持,为你筑就数据科学家之路!扫码了解更多:

文章推荐:
用户画像从0到100的构建思路
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请超过500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、点赞、在看,给个三连击呗!👇










