作者简介:鲍捷老师是文因互动的创始人和CEO,他的微信号 baojie_memect。本文授权转发。
序
Tim Berners-Lee昨天拿到了2016年度的计算机科学最高奖:图灵奖。他获得这个奖,实至名归。领域中人一直都认为他得奖只是时间问题。
Tim 的一生有两个伟大的贡献(当然,他还有很多其他的贡献):一、互联世界的文档,即万维网(Web)的发明及其规模化的努力,包括 W3C 的工作;二、互联人类知识的努力,包括语义网(Semantic Web)、互联数据(Linked Data)、开放数据(Open Data)、知识图谱(Knowledge Graph)等。第一个贡献已经广为人知,第二个贡献还在发展中,知道的人不多。但是我以为,第二个贡献将会是比第一个贡献更大的贡献。
Tim 也是一位伟大的思想家。他总是从全人类的角度去思考技术问题。普通的设计师从 user 的角度思考问题,伟大的设计师从 human 的角度思考。而 Tim Berners-Lee 是从 humanity 的角度去设计。 可以毫不夸张地说,Tim Berners-Lee 是当今人类神经系统的总设计师。他的工作,在推动历史的进程。他领先于大多数的工业领袖至少十年在进行布局和推动。他又善于组织和影响,对于学术界和欧美政府的最高层,他都能施加影响一步步地推进具体的实施。
Tim 说过,Web 从来不仅是技术的发明,更多的是一种社会的创造。无论是 HTTP 还是 PageRank,无论是 Wiki 还是 Facebook,人的因素是主导因素。开放、交流、合作,新一代的 Web 的技术,必然还是要以人的需要、长处、局限、价值为出发点。技术只是一小部分,社会模式的变迁才是最根本的。
在 RPI、MIT 和 W3C 工作期间,笔者有幸近距离和 Tim 一起工作。 Web 和 Semantic Web 是如何兴起的?Web 的未来是什么?我们遇到的困难和可能的出路是什么?今年1月笔者曾在人民大学做了一次演讲。本文基于这次演讲,简单回顾了 Tim 当年对 Web 的设想,和 Web 从文档互联走向知识互联的历程,并对未来做了一些猜想。
一、Web作为杀手级应用
什么是杀手级应用?Wikipedia 上的定义说,杀手级应用就是说它能够使这个应用或技术,从小众走向大众,极大地提高它的使用人数的应用。
随便举几个杀手级应用的例子: ATM 机,跟 Web 和人工智能没关系,但是我们可以想一想,这是什么技术的应用?数据库技术和网络技术。若我们抽象地向我们的外婆解释,什么是数据库?什么是网络?她根本听不懂;但是如果你说这有一个机器,你把一张塑料卡片给它,它把钱给你,可能就听懂了。这就是杀手级应用。
那还有什么样的杀手级应用?Visicalc 有多少人听说过?70 年代末兴起了电子表格技术,电子表格技术是什么?从纯技术角度,可以说电子表格没有解决什么实质性问题,电子表格能解决的所有问题,数据库都能够解决。70 年代初已经有数据库了,那到了 70 年代末为什么又有了电子表格呢?我们想,一个只有初中文化水准的文员,他能够用好数据库吗?那么在 70 年代末兴起的这个电子表格,它要解决的不是面向机器的问题,是面向人的问题,他把原来只有极少数的写 SQL 能够享受到的对数据管理的快乐,让千千万万只有中学文化水平的人,也能够用到。这是电子表格的意义,所以后来有了 Excel。现在电子表格已经成了百亿级的一个大产业。
那么再看另外一个,这个是什么?

这是世界上第一个图形界面的浏览器。第一个 Web Server 是 1990 年 Tim Berners-Lee 在 CERN 写出来的,那个时候已有一个浏览器,但是那浏览器是命令行的浏览器( line by line 的 browser),那种浏览器是只有非常少数的人可以用的。到了 1992 年的时候,另外一个工程师写出来这个浏览器 Erwise,图形界面基于 X-window 的。到了 1993 年的时候,有了 Mosaic 后来演变成了 Netscape,这也是一个杀手级应用。
我们想一下,实际上 Internet 并不新,60 年代就已经有 Internet;超文本也不新,80 年代就已经有了超文本,但为什么一直到了 1994 年(那年全球也只有 3000 个网站),Web 才真正成为一个现象级的工具?因为在这之前没有这样的杀手级应用。Browser 就是这样的杀手级应用,所以说我们看 1993 年有了 Mosaic,1994 年就有了 Amazon,这不是偶然的,这都是杀手级应用对一个领域带来的冲击。
当我们回来看 Web 本身,它也是一个杀手级应用,实际上 Web 是因特网( Internet) 的一个应用,但现在在大众媒体上,可能大家不会区别。大家都说“互联网”,大家谈互联网的时候,通常实际上在谈万维网(Web)。那么底层的从数据链路层,到 IP 层,到传输层到表现层,大家在日常的媒体中是不会看到这些区别的,Web 只是最上面的这么一些协议:HTTP,HTML,URI。这三个协议构成了 Web的基础。
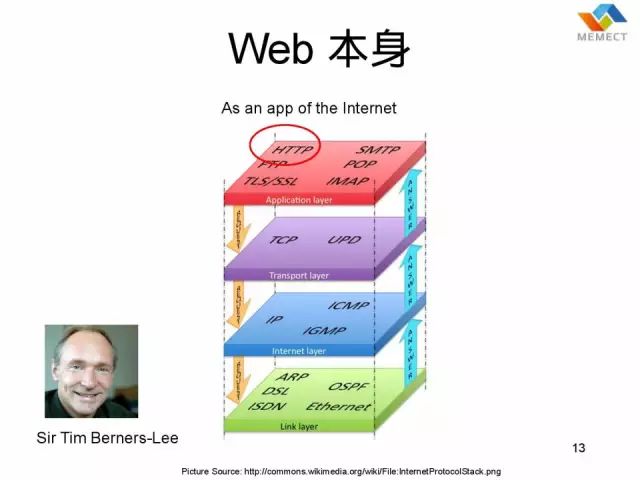
Web 本身是怎么产生的?实际上这些技术在 Tim 发明 Web 十几年之前都已经有了。为什么到了 1991 年的时候,才出现 Tim Berners-Lee 这个人把它们汇总在一起呢?
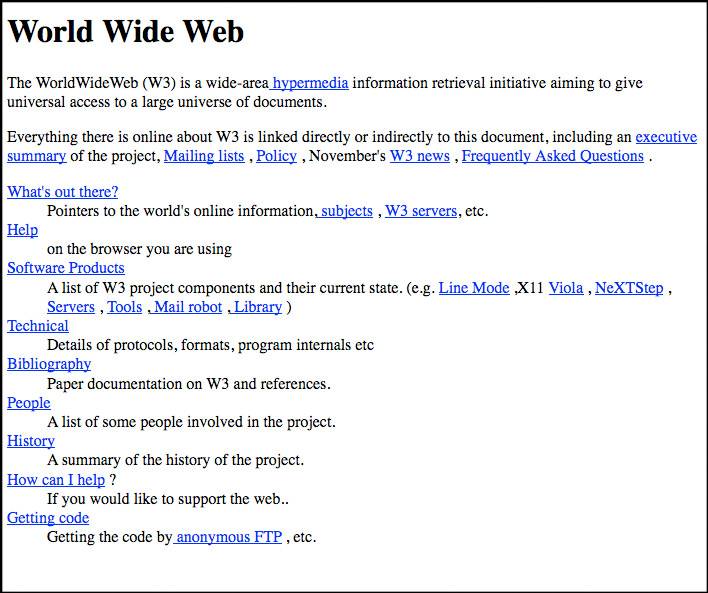
这个我们现在看到的是号称是世界上第一个 Web Page。这是在大概 1990 年圣诞节的时候, Tim Berners-Lee 在他自己的个人电脑上写的。当时这个 Web 只有他自己那一台电脑在看。从他写了第一个 Web 页面,到后来欧洲原子能组织内部,他花了差不多一年时间,说服所有人来用 Web。大部分人都不相信那个东西有什么价值。后来他又足足花了两年的时间,到全世界各地去做路演,才有非常少的人相信这个东西是有价值的。
TED 上有一个演讲——我是怎么拒绝 Tim Berners-Lee 的,就是有一个人在一个会议上,遇到了 Tim Berners-Lee,Tim Berners-Lee 告诉他,你现在做的东西(百度全书应用)很好,你应该把这个百度全书应用和因特网结合在一起。他很困惑,他说我为什么要把这个东西和因特网结合在一起,这会有任何价值吗?(相关TED Talk 链接:Ian Ritchie 我是怎么拒绝 Tim Berners—Lee ? ;Tim Berners-Lee ) 这不是一个偶然的例子,如果你去看《
Weaving the Web》
这本书的话,书里讲了很多。
二、Web的三个目标
一个新的技术在刚刚诞生的时候,都是不完备的,绝大多数人在那个时候,是没有办法理解这个技术能带来怎样颠覆性的价值。Web 是这种,Semantic Web 是这样,知识图谱也是这样,所以我们在这个发展的过程中,经历了很多被人瞧不起,被人认为没价值的日子。这本书我强烈地推荐大家每个人都去看一看,不仅仅是研究 Web 的人要看,我认为这本书对于人工智能的研究,对于互联网的工程师、产品经理、运营经理,也是有很大的意义的。

我看完这本书就思考一个问题,什么叫知识?知识是怎么产生的,如果我们想构造一个知识的互联的网络,或者知识的管理的网络,最重要的事情是什么?Tim Berners-Lee 的答案就是
互联、开放和自由
。这本书也有中文版
《编织-万维网之父》,这本书已经绝版了,在淘宝上有卖的。
Tim Berners-Lee 在这本书里,讲了他在1990 年的时候——实际上 是1989 年——在一个 proposal 里面讲了三件事情,当时他很乐观,他认为给他六个月时间,他可以把这些事情都干了。事实是已经过去 25 年了,这些事情还没有做完。这三件事情是什么呢?
第一件事情就是一个互联的文档的 Web,一个 Document Web,这件事情他确实做完了,然后之后又花了 15 年时间去完善。
第二件事情叫 Semantic Web,我们每一个文档背后实际上都承载着人的知识。我们如何让这个文档不仅仅被人来阅读,而且也可以被机器来阅读呢?知识是什么,
知识是一种结构
,当我们有一种机器可读的结构的时候,我们实际上就有了一个知识的网络。

从 1999 年开始,他开始力推 Semantic Web。到了 2001 年的时候,他和 Jim Hendler,Ora Lassila 一起,在《科学美国人》上面发了这篇文章阐述了一个理念,如果我们有了结构化数据,用知识去标注的网络应用的能力话,我们能够实现怎样神奇的一些应用。实际上他描述的很多东西,我们现在已经实现了,比如像 Siri,IBM Watson, 就是 Tim Berners-Lee 在十几年前就已经描述的一些设想。当时认为是科幻,现在已成现实。
他 proposal 的第三部分,说我们有了知识以后还要怎么样?最重要的是
人
,Web 在往前走的每一步,它核心的思考,它真正能够带来的知识和最有价值的数据,不是机器,而是人产生出来的。所以如何让机器、人、知识能够关联在一起,这是 Tim Berners-Lee 最主要的思考。他在设计里面提出来,我们不但要能够读这些数据,更重要的是我们能够让人非常容易地去创造这些数据。当时还没有 Wiki 这个概念,但他描述了这样一个系统,实际上就是一个 Semantic Wiki 系统。
我们花了25年的时间,大概实现了他的第一个目标,然后第二个目标实现了一半。所以 Web 只走完了上半场,还有下半场要走。
三、从万维网到语义网
我们在剩下的 25 年时间内,从现在起到 2040 年,要实现另外一半目标。在《科学美国人》这篇文章里面,Tim Berners-Lee 再一次表达了他充分的乐观。我们刚才提到了,他第一次说花六个月时间就可以实现那个 proposal,最后证明他把这个任务的困难程度低估了一个数量级。同样,在这篇文章里,他再次低估了这个任务的复杂程度,他认为我们十年之内就能实现 Semantic Web ,但事实上没有做到。到了 2007 年、2008 年的时候,整个行业的人就已经发现,可能我们要花 30 年的时间,才能实现这个梦想,在 2007 年感觉 30 年后很远,但现在已经到 2017 年了,我们发现其实这个估计是挺靠谱的一件事情,我们下面细说为什么这个估计是靠谱的。

这是我从 W3C 的前语义网技术负责人 Ivan Herman 的一个 slides 里面偷来的。他是 2010 年讲的,在 2005 年的时候,他认为这个技术已经发展到什么程度呢?就是在前面这种 Innovator 这种层面,到了2010年的时候,他认为已经到了 Early Adopters ,他这个估计应该说是对的。
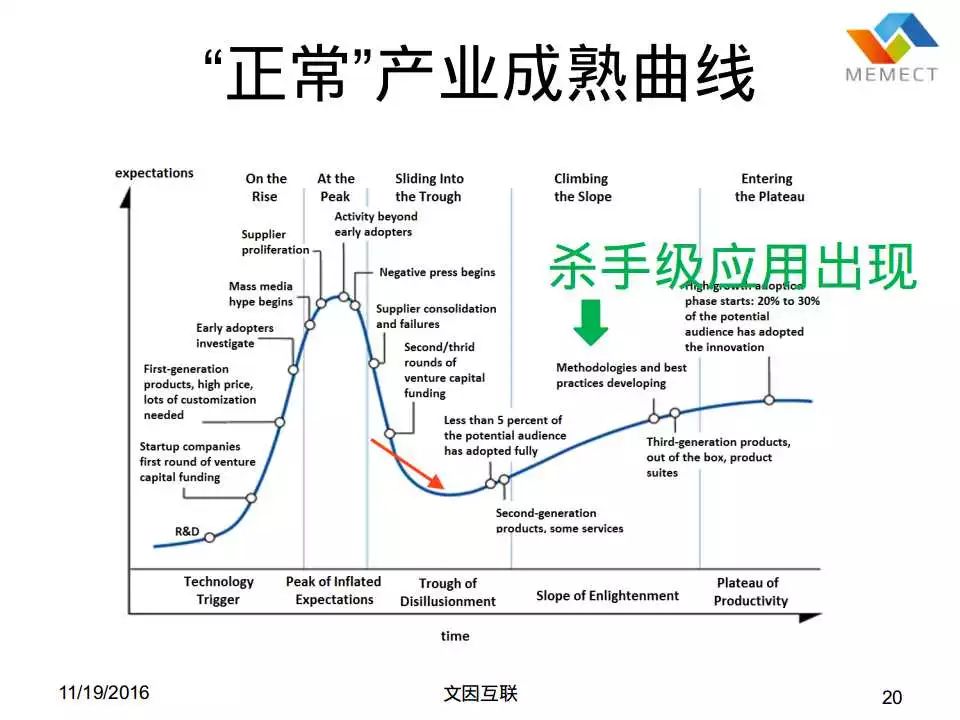
这样一个曲线对于正常的学科的发展是没有问题的,大家肯定也在其他地方看到过的,叫技术成熟度曲线。一般情况下,一开始一个技术没有什么人知道,过了一段时间之后,大家觉得这个技术太牛逼了,然后到了一个顶点;后来顶点过去以后,到达低谷,觉得你是骗子,大家开始失望,没有人投资了;经过一段时间的冬天,然后后来发现其实也不全然是欺骗,还是有合理的因素的,慢慢往回爬,最后爬到一个 majority,到成熟市场,通常“正常”的技术是这么来爬的。那么对于”正常”的技术,到了这个阶段的时候,就是一次冬天回去之后,往上爬的这个阶段,杀手级应用就会出现了。
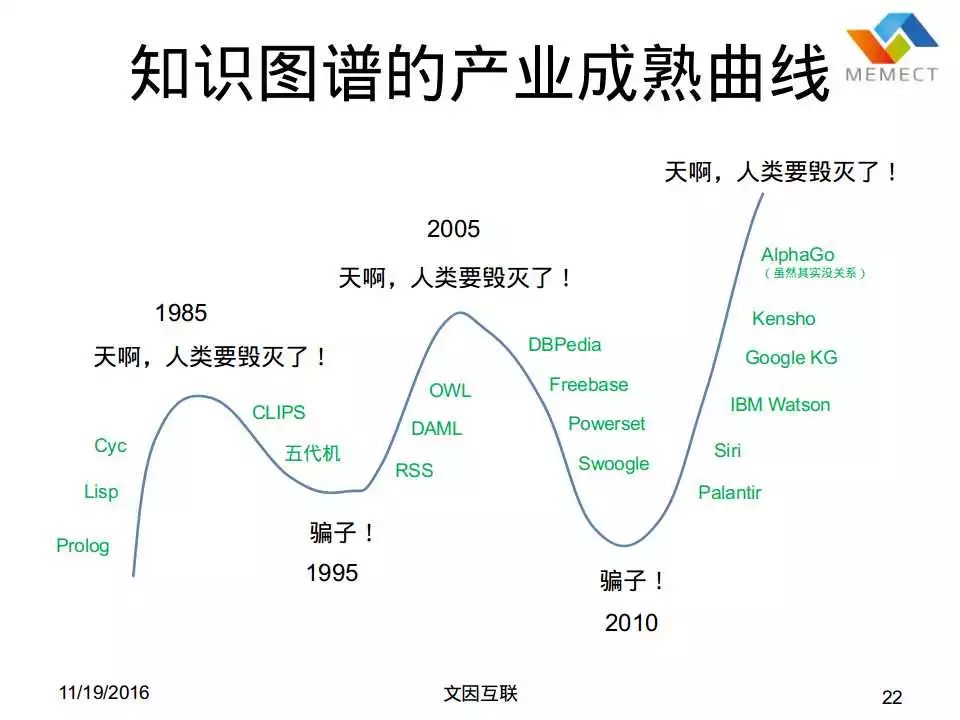
但是我们知道人工智能技术不是“正常技术”,人工智能的技术的成熟曲线是这个样子的,差不多每过十年,我们要被人骂一次,我们是骗子。
那么具体来看,对于知识图谱技术,我们已经被人骂了几次。实际上其实这个曲线前面还有几次,我就没有画了,其实从 60 年代开始就有了。我们就从 80 年代开始讲,那时候我们有一大堆叫 Lisp Machine,当时是认为如果我们有了 Lisp,如果我们有了 Prolog,我们可以把整个人类所有的知识都建模。有个公司叫 Cyc,它就是努力想把整个人类的知识全部用逻辑表达出来。到了 80 年代末的时候,日本人被忽悠得很厉害,说我们要有五代机。所以这个时候就产生了很大的一个泡沫,果不其然到了90年代中期的时候,大家说骗子。那个时候的博士生是非常悲摧的。
然后到了 90 年代末,慢慢地又开始往前跑了,当时 Guha 在苹果发明了 RSS,后来 1997 年的时候在苹果发明出来了 RDF。后来到了 1999 年的时候,RDF 成为了行业标准,然后DARPA(美国国防高级研究计划局) 成立了 DAML 工作小组。到了 2000 年前后的时候有了 OWL,整个语义网有了这样一种新希望。大家又开始觉得太厉害了,人类又要毁灭了,但事实证明又不是。所以大概从 2003 年、2004 年往后走,大家发现这个技术没有想的那么牛逼,很多问题解决不了。所以开始往下走。到了 2010 年的时候,虽然我们已经做了非常多的很好的工作,比如 Freebase 这样的工作,但当时基本上 Semantic Web 毕业的博士生找不到本职工作。
四、从语义网到知识图谱
到了 2012 年的时候,突然又开始加速往前跑,以谷歌的知识图谱(Knowledge Graph)的发布作为一个标志。但实际上如果我们抛开媒体对我们的报导,跟这个行业真正的发展其实是没有什么关系的,这个行业的技术是一直往前走的,哪怕在“低谷”的这个阶段,也是有非常多的扎实的工作,在不断地推进。像 DBpedia 这样的系统在 2006 年、2007 年做出来的时候,大多数人压根认识不到它的价值。后来 Watson 发现只有用这个技术,才能够把最后 10个百分点的 precision 提高上去,没有其他任何技术能够做到,这时候这个技术才进入了媒体。但在进入媒体之前大量的工作,一直都在水下酝酿。
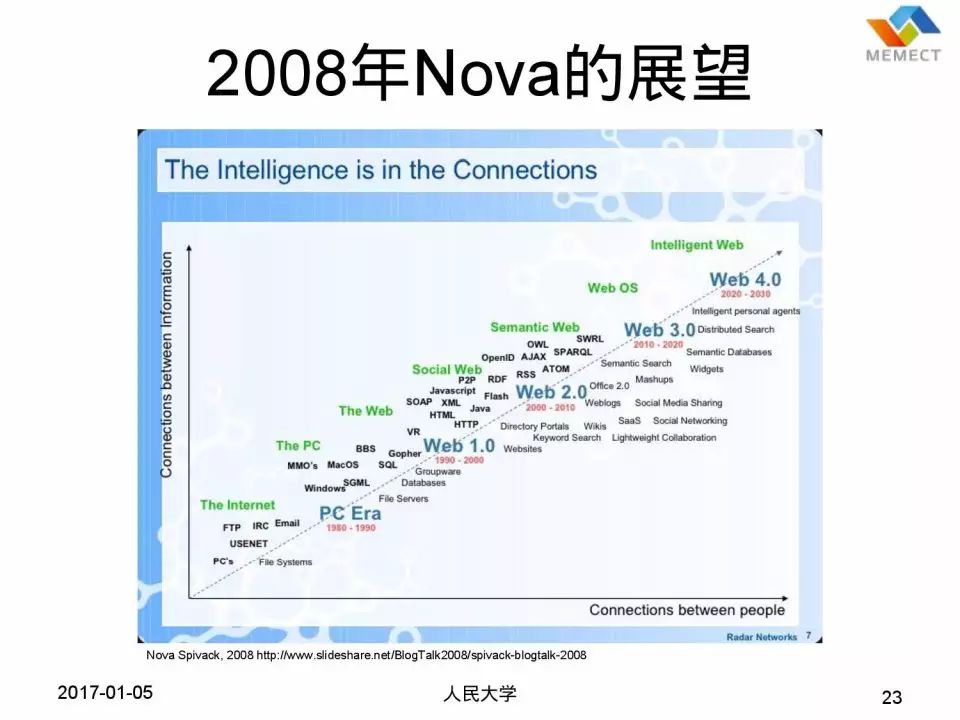
这个是 Nova Spivack (Twine、Bottlenose的CEO) 在 2008 年的时候做的一个预测,在 2008 年大家已经发现了,这个 Tim Berners-Lee 的预测是不准的,我们低估了这个任务的困难程度。所以他把 Web 分为 Web 1、2、3、4,Web 2 就是 Social Web,当时发现 Social Web 已经很成功了。他认为到了 2020 年的时候,我们能够实现 Semantic Web。那么现在我们在 2017 年,还有三年时间到 2020 年,我们能实现 Semantic Web 吗?好像也不能,所以他也低估了这个问题的困难程度。他认为 Web 4.0 是 Intelligent Web,我认为这个设想还是比较靠谱的,但是对于 Semantic Web 这个规划,还是有点乐观了。
这件事情其实要分为两步来走,要把这个分成 Data 和 Intelligence 两件事情分开来讲。我刚才提到的一个低潮里,不仅仅是那些小公司在这个低潮里面活不下去,大公司也活不下去。并不是说这些大公司垮台了,谷歌、雅虎当时都有很多 Semantic Web Activities,表现是大部分的这些这种项目最终都失败了。比如说谷歌在 2008 年、2009 年,Rich Snippets 这个项目无疾而终——当然到后来有一部分演化成了 Schema.org ,所以不是完全的失败。这样的项目还有非常非常多,包括当时的标准化的努力,RDF 和 OWL 从某种程度上来说是成功的。但是从 2007 年、2008 年到 2010 年的 RIF 和 OWL2,可以说是不成功的。当时的大部分的这些公司最后也都完蛋了,像 Hakia,Powerset,Twine,这些当时这种网红级的公司,最后也基本上没有一个能活到 2010 年之后的,所以在这个时候大家是很被鄙视的。
但是到了 2012 年前后的时候,我们又实现反弹了。实际上很多工作在 2009 年、2010 年就已经开始,比如 2009 年的时候,在 Tim Berners-Lee 推动下,我们有了开放政府数据。2006 年的时候,我们有了互联数据,也是 Tim Berners-Lee 推动的。2010 年的时候我们有了图数据库,我们终于在 RDF 数据库之外,有了另外一个选择。到了2010 年、2011 年是两个标志性的项目,一个是Siri,一个是 IBM Waston 。打了两剂强心针,大家发现这东西真的有用。
到了 2011 年的时候,Palantir 实现了 2.5 亿美元的收入。以前从来没有一个用语义技术的公司,能够做到这一点。大家发现这个东西不仅是技术上有用,在经济上也有用了。Palantir 是一个本体编辑器。现在它的年收入是 20 亿美金。
2012 年的时候这是最大的一件事情,谷歌把 Freebase 给买了之后,改了一个名字叫 Knowledge Graph。谷歌的示范效果是显而易见的。大家一看谷歌用了,所有人都跟着用,微软有了Trinity,当时搜狐、百度国内一堆互联网公司,每一家都开始搞 Knowledge Graph。
2013 年的时候美国这边有了 Kensho,一个金融的知识图谱的应用,到了 2015 年的时候,知识图谱这个词开始变为媒体的宠儿了。2016 年的时候,中国市场上出现各种对话机器人,智能音箱,我觉得可能有上百家,这个背后都是要用到知识图谱。这一块最早应该是 2012 年的时候,出门问问。这样的公司也非常非常多。
五、知识图谱翻身的背后
所以我们现在可以看到知识图谱技术,已经在过去的五年当中,完美打了一个翻身仗。但是冰冻三尺非一日之寒,就是说我们能够从被人鄙视到大家都觉得这个技术有一点用,实际上是这十几年背后整个领域不懈的努力,才有了今天这一点点的成绩。我们今年看到的知识图谱,实际上是许许多多的上千个各种不同的项目,在过去十几年里面,不停实验,最后留下的一点点精华。
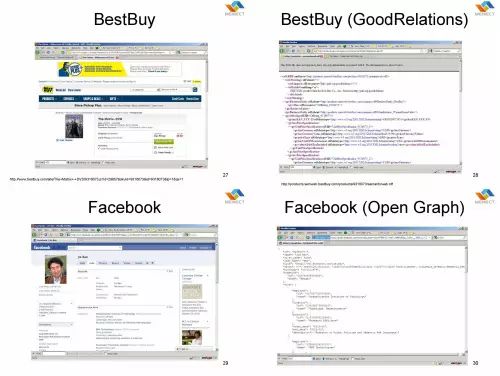
比如说上图,Bestbuy 的商品元数据。其实目前这一堆截图,都是我在 2008 年到 2010 年做的事情。但当时做的很多事情,中国现在还没有。其实在每一个领域,我认为在这里面,在中国如果把这个模式复制过来都是有机会的。Bestbuy 它每一个商品描述页,这是我们人看到的页面,那么这是机器看到的页面,它背后有一个 Ontology,叫 GoodRelations。
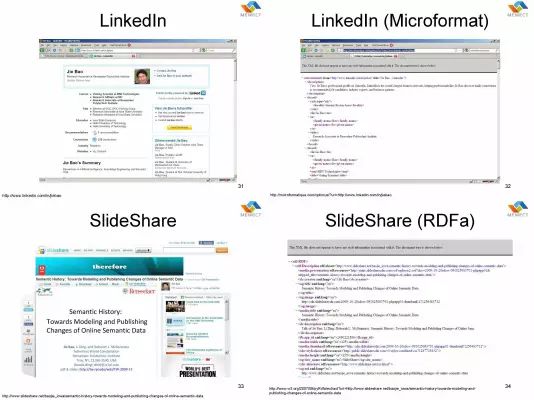
这个是 Facebook,这是我们大家能够看到的页面,它背后的 Metadata 是什么呢?这个是 Open Graph。这个是LinkedIn, 他的背后有 Microformat 的 Metadata。这个是 SlideShare, 这个背后是 RDFa 格式的 Metadata。这是 IMDb,这背后是另外一种 Microformat 的 Metadata。
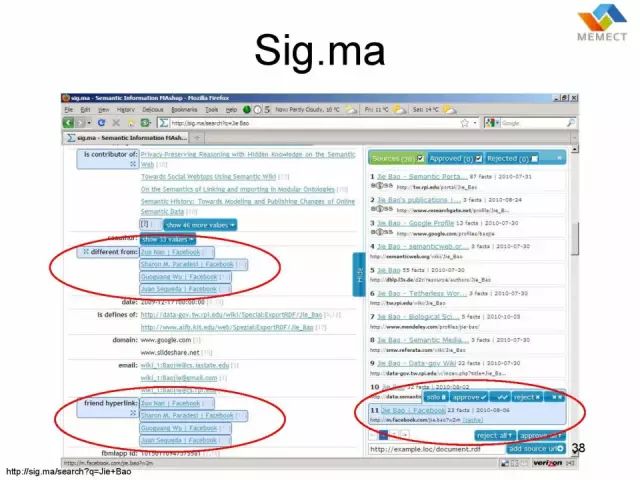
这是 Sig.ma,它实际上是一个 Semantic Data Aggregation 的 Portal,目前这个网站已经下线了。对网上能够找到的每一个实体(entity),比如说人、公司,这每一个都是实体,它把每一个实体的数据做了一个聚合,当时这上面有我的一个页面,图例是关于我个人简历的一个聚合。
我们不仅有各种所谓直接创造出来的语义数据,还有各种通过现有的数据,映射过来的数据。
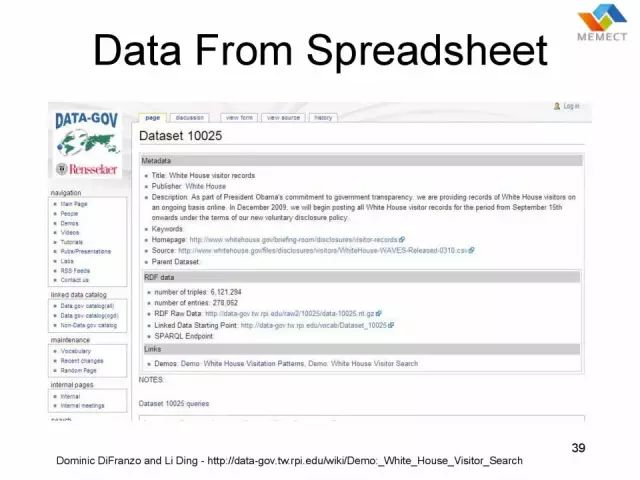
这是我们当时在 RPI 做的一个工作。就是有大量的政府的数据,他们基本上是用电子表格(spreadsheet)的方式来发布的,我们在上面做了各种规划整理的工作,把它变成了 RDF 的格式,然后提高了数据质量。这是它当时的原始的数据格式,就是在美国政府 Data.gov 这个网站上面,美国各个部门,从联邦政府开始,强制公开数据的发布。然后这上面的数据,大部分都是很脏的数据,它背后的各种数据集,基本上是未经整理的。所以在 RPI,我们就做了这样一个整理。Jim Hendler 是领导者,他发挥了对白宫的影响力。丁力是第一个项目经理。Tim Berners-Lee 影响了英国首相,推动了英国类似的项目。
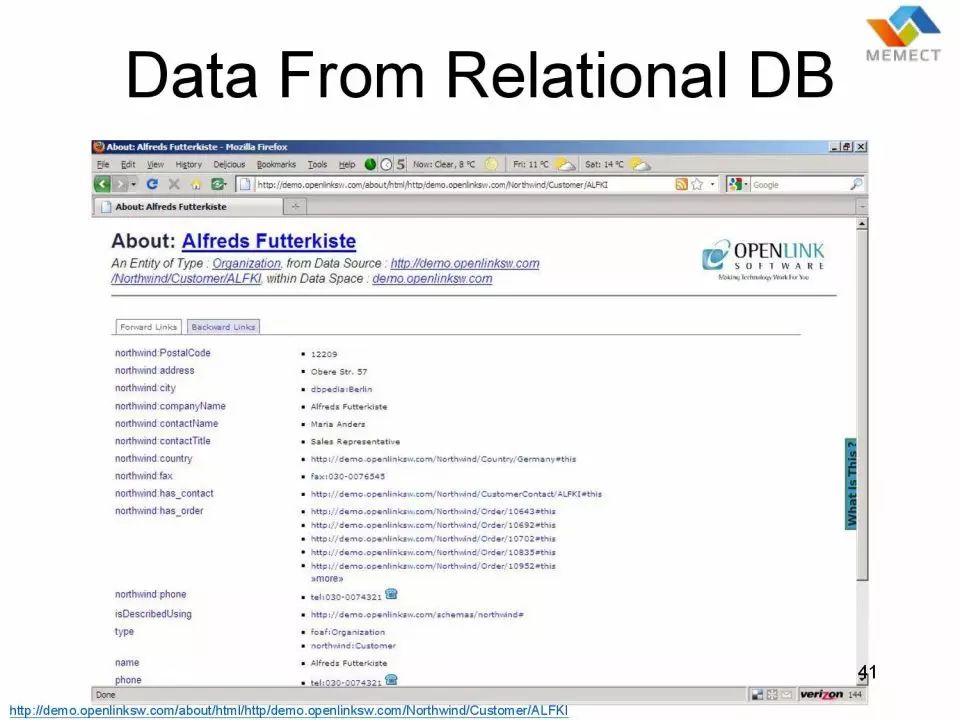
这是 Open Link 这个公司,他们发布的数据库叫 Virtuoso,是它的一个应用,可以把数据库数据变成 RDF。后来在 W3C,也有一个标准叫 R2R,就是 Relational Database to RDF这样一个标准,规范的是我们如何把现在大量已经存在的结构化数据放到网上来。讲一句题外话,当初 Tim Berners-Lee 在发明 Web 的时候,大多数人不相信这个东西有用,他做了两件事情,第一个是他把 FTP 映射到 Web上来了,第二个是他把 CERN 的电话号码本映射到Web 上来了,就是充分地利用现有的数据来 bootstrap 一个新技术。所以刚才提到的从 Excel,从电子表格到结构化数据,把它放在网上,是我们赶超的一些小技巧。我们(文因互联)现在做的,把股转书里面的那些 PDF 文件里面的数据放在网上,其实也是类似的。
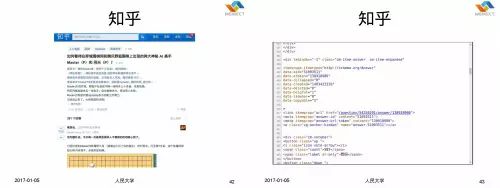
这是我今天早上刚刚截的知乎上面的页面。左边是人看到的知乎的页面,右边是机器看到的知乎的页面,这是什么?其实这是 HTML5 的一些 Semantic Annotations。
所以我们看到的绝大多数的网页,只要你用心看看它的 HTML 源代码,你都可以发现背后的 Semantic Metadata,所以从数据的角度来说,Semantic Web 其实是已经实现了。
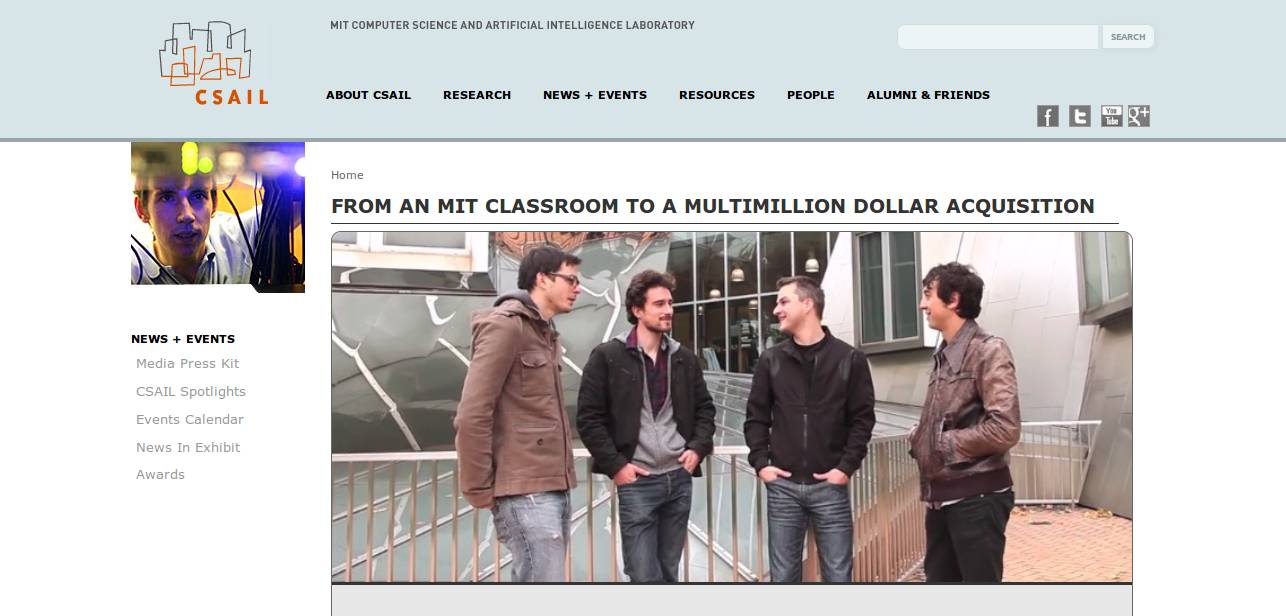
我就举个更具体的小例子吧,这四个哥们,是我在 MIT 的时候认识的,2010 年的1月份,我们有一个叫 Linked Data Entrepreneurship Program,也是 Tim Berners-Lee 组织的,就是一些学生做一些培训,在三天之内教他们RDF 是什么样子等等,然后让他们去找一个应用,自己去做一些小例子。然后这四个哥们,就做了一个菜单的应用,他说我能不能帮助餐馆,把他们点菜的菜单给放到网上去。听起来好像是个很简单的主意,但他们执行得非常好,这四个人也很有企业家的素质,他们很快就拿到了投资,最后融到了 400 万美元的风投。他们做了两年之后,把这个公司给卖掉了,卖了 8000 万美元,这是我亲眼看到的一个用语义技术来创造财富的例子。

当然这样的例子还有很多,在美国做 Semantic Search 的公司还有 200 家,在每一个垂直领域里都有,这上面列的是一些大公司,但实际上小的公司比这多得多,要多一个数量级。所以我们回过头来看,在 2007 年的时候 Gartner 做了这个预测,他预测到 2017 年,majority of Web pages are decorated with some form of semantic hypertext。这个确实我们已经做到了。
这个翻身的过程中,Tim Berners-Lee 起到了巨大的作用。2006 年的链接数据,2009 年的政府开放数据,W3C 一直发挥的社区引导作用,都是 Tim 直接领导的结果。可以说,除了他,也没有第二个人在领域出现执行偏差的时候,能够发挥这么大的影响力来实事求是地纠正。他不断地总结,在他的 Design Issues 里,不断反思 Web 发展的一些原则性问题。这些思考通常指导着之后多年的实践。
六、五个问题
好,通过这些例子我们学到了什么?在之前的 15 年当中,我们经历了被人鄙视的阶段,我们也在最近五六年里面打了一个翻身仗。那我们现在应该反思一些基本的问题,










