简仁贤表示,机器人同样代表了商业的品牌,一言一行都需要十分慎重,而不以语义理解为基础的回答是不可控的。因此,竹间智能花了大量的时间和企业进行磨合,结合企业的数据和他们搜集的数据,定制模型,并在用户使用的过程中继续打磨模型,以此使技术尽快落地,给用户提供良好的体验,使人工智能更好地融入人群。
撰文 | 邱陆陆
编辑 | 藤子
「我们希望做情感机器人,希望透过机器更智能地理解一个人。」随着计算能力的提升、神经网络的步步深入,配以图像识别、语音识别的人工智能已经逐渐变得能够「听见」、「看见」。然而在竹间智能创始人简仁贤看来,这还远远不够。「不仅看得到,还可以看得懂,不仅听得到,还可以听得懂。」简仁贤认为,以此为基础进行交互,才是机器人最终的目标。
2015 年 8 月,简仁贤创办竹间智能,想要将电影《Her》(《她》)中所描绘的,那个具有丰富情感,能读懂、看懂、听懂、有记忆的人工智能带入现实世界。而那时,机场的机器人会安慰匆忙赶飞机的乘客「不要急,还来得及」,商场的机器人能识别顾客属于油性皮肤、由于过度操劳而黑眼圈加深,并有针对性地进行导购,电商平台的机器人,在买家吐槽「快递箱破了」时,能通过简短的数轮对话判断买家是想要退货还是单纯发泄情绪,并提供对应方案。

竹间智能创始人简仁贤
对有产品经验、习惯做战略规划的创业者来说,他们创业的动力可能不是手头的某项技术,而是对市场需求的判断:这判断可能是在一些现象里初现端倪的「消费者需要什么」,也可能是无迹可寻的「我认为消费者应该需要什么」。然后,哪怕这个目标看起来远在千里之外,他也可以据此逐步倒推出每一个阶段的技术需求,比对当前的资源与局限,一往无前地推进。
从计算机视觉到自然语言理解,全面而深入的技术储备
为了实现「能与人交互的情感机器人」,竹间智能几乎在人工智能涉及的每个领域都进行了有广度、有深度的技术储备。
例如基于人脸图像的计算机视觉技术,竹间智能就储备了包括基础的人脸侦测、人脸识别、人脸关键点检测技术,以及多项更贴近应用场景的技术,例如自动驾驶场景下的疲劳侦测技术、用于营销受众分析的注意力分析技术、与 AR 密切相关的视线追踪技术等。
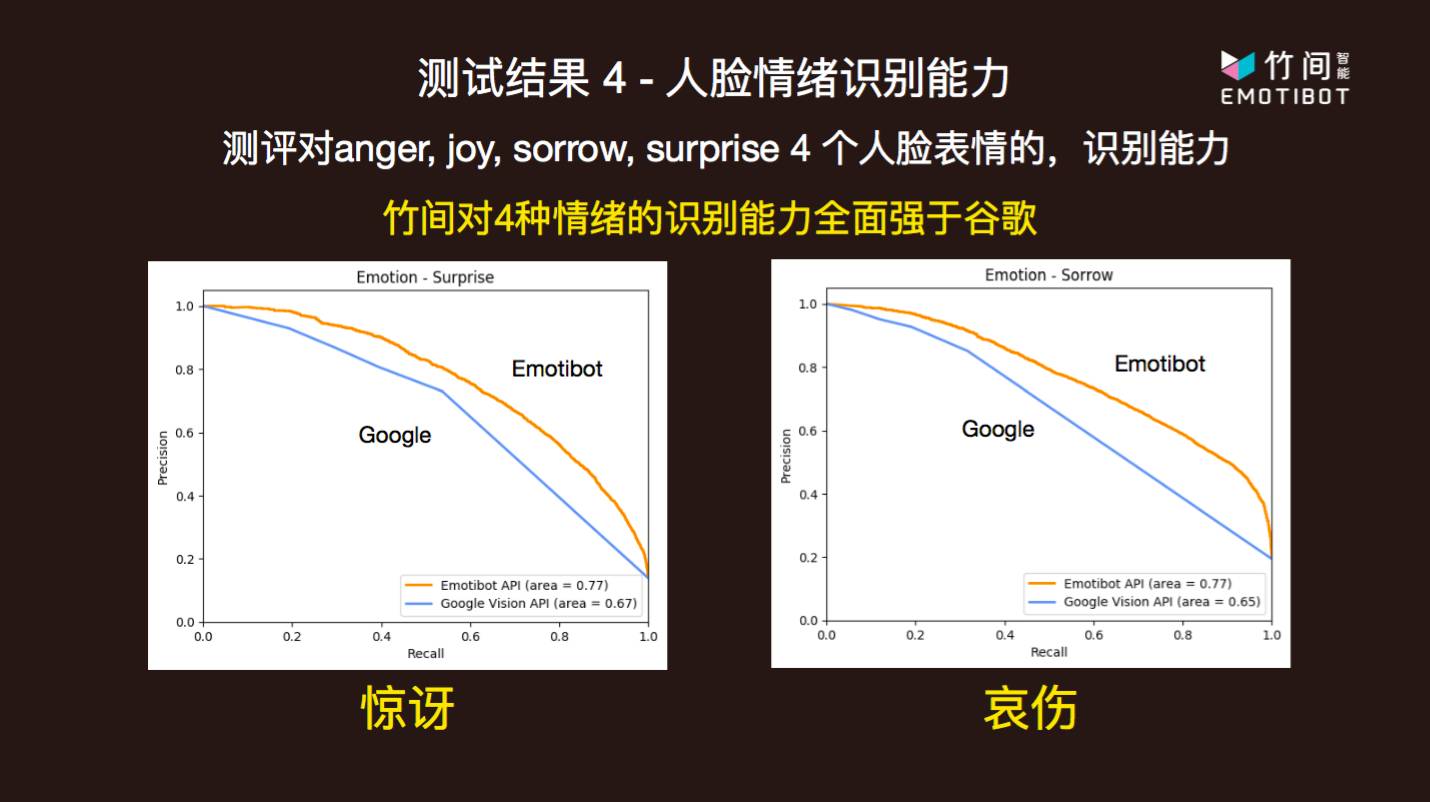
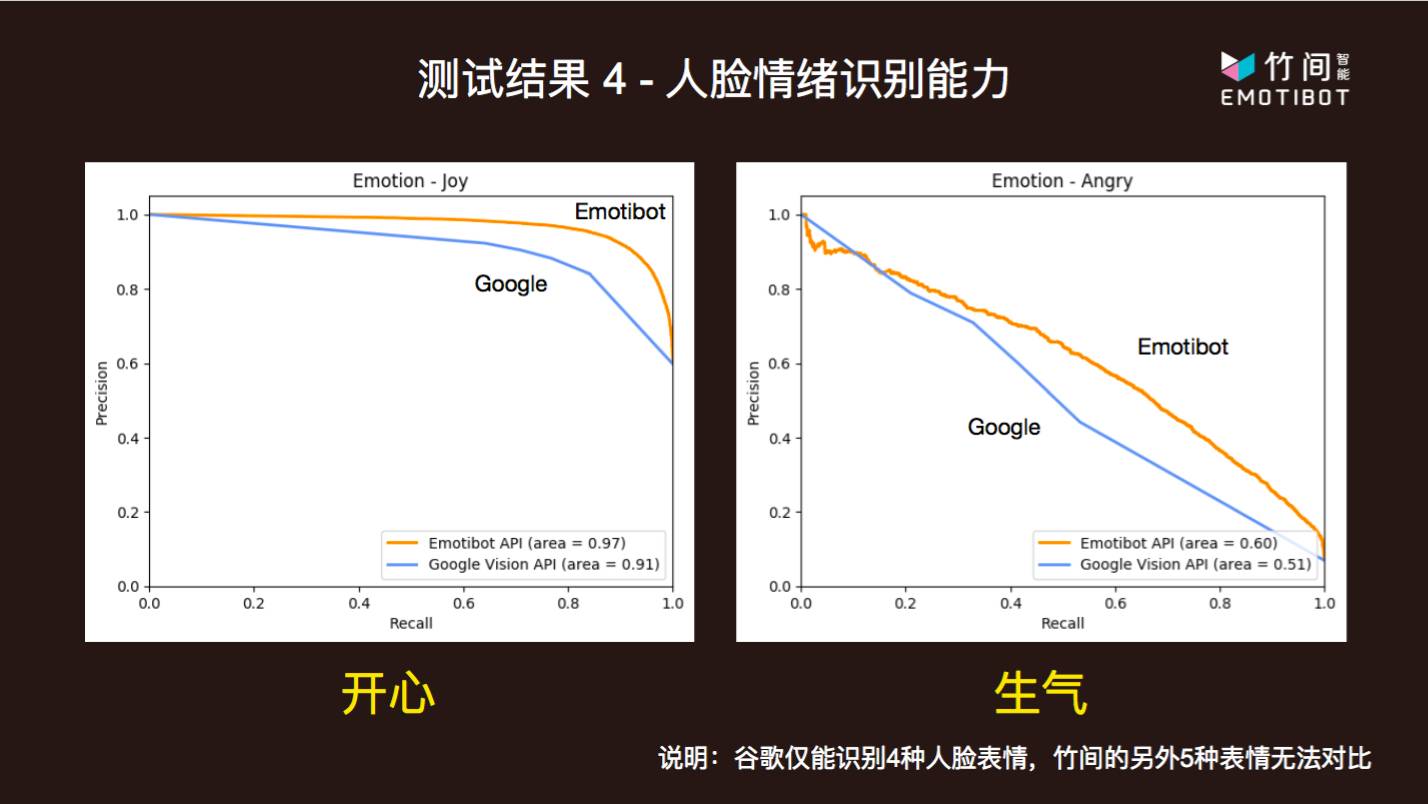
简仁贤以多模态情绪识别为例,对技术储备的精细程度做了一个具体的描述。传统的人脸表情情绪识别通常包括开心、生气、哀伤、惊讶,这些是表现型相对明显、检测难度比较小的情绪种类。然而「最容易检测到」并不等同于「最有用」,有一些与「微表情」高度相关联的、无意识、小幅度、检测难度较高的情绪种类,其实对于理解人的意图至关重要。例如,在一个问答过程进行期间,人类在机器做出解释后什么都没有说,或者只是给出一些语气词「嗯……」,几乎没有给出任何有信息量的反馈,这时,机器就需要借助语言之外的表情信息判断接下来的动作,而沉默对应的感情通常并不激烈:例如,用户的沉默有可能代表困惑、正在思索,那么机器此时就理应进一步给出解释。类似这样的场景还有很多,因此竹间在传统的四种表情情绪识别类型之外,又添加了害怕、反感、轻视、困惑和中性五种情感的识别。更多的维度意味着更广泛的应用场景。除此之外,竹间智能也提高了模型在各个维度上的识别能力,准确度和召回率都很好。
竹间智能以香港中文大学发布的 Expression in- the-Wild (ExpW) Dataset 作为测试集,将自己的情绪识别 API Emoti-Face 与谷歌云提供的也有情绪识别功能的 Google cloud vision API 进行了对比,并在共有的开心、生气、哀伤和惊讶四个维度上,取得了优异于谷歌的准确率和识别能力。
在 9 种情绪识别之外,竹间本着「做透人脸」的原则,还开发了 22 类人脸基本属性识别和 15 类皮肤质量识别算法。而这,也只是竹间智能的计算机视觉方面技术储备的冰山一角。如同简仁贤所说,相比于公开发表论文,公司更愿意选择为技术申请专利。
而为了让算法达到「商用」的标准,对于模型的训练数据有极为严格的要求。用现有的公开数据集,可以达到 40-50% 的准确率水准,但是这距离模型能够投入商用还有非常大的距离。因此公司自行收集了用于训练和测试的数据。花了大量的时间、精力,甚至返工多次,来做各种图像标注。「采集数据的工作我们就做了一年半多。」简仁贤表示。
采集数据是从研发标注工具开始的。情感标注的难点在于,它是一个包含主观判断的过程。同样一个人、一个表情,可能会带给基准不同的众多标注员以不同的感想,每张图片如果只标注一次,则容易存在错标或者过于主观的情况,从而影响模型的效果。因此,一个商业可用的情绪情感模型,必须多次标注、交叉检验。而且,不仅标注的类型准确很重要,标注的打分标准统一也很重要。例如当模型发生变化的时候,打分的逻辑也会随之变化。因此,竹间设计了专用的标注工具,主要优化了多个标注员的协作和评估与交叉检验过程,并设计了一个自动化的质量监控流程,能够很容易地按批次检验数据质量,剔除不合格数据返回重做。同时,工程师们还提炼出了一套针对标注人员的训练流程,力图从各个角度确保得到的数据是准确的、高质量的。最终,竹间标注了超过一百多万张图像数据用于各类与人脸相关的问题。其中,小部分是从公开数据集中精选而来,大部分从视频等情绪变化非常明显的素材中自主采集。
有了数据,就可以有针对性地开发算法了。在图像方面,市面上比较著名的模型有多伦多大学 Hinton 组的 Alex Krizhevsky 所开发的,赢得了 ILSVRC2012 的 8 层神经网络 AlexNet,谷歌研究院赢得了 ILSVRC2014 的 22 层深度神经网络 GoogLeNet。而竹间开发了自己的模型 CastNet,整合了 ResNet 模型、Inception 模型的思路,同时包含并行(parallel)结构,和堆叠(stack)结构。
在准确率相近的情况下,能在各种平台上超越 GoogLeNet 的速度,差距最大的平台甚至能快接近十倍。由于竹间智能考虑到带宽、云端 GPU 占用等限制,会把一部分模型部署在机器人等终端设备上,因此运算的高效性是至关重要的考虑因素。
模型在 CVPR 2017 的 Affect-in-the-wild 挑战中拿到了最佳效果奖。

而效果卓越的计算机视觉还并不是竹间智能投入最多的部分。「公司在语义理解、语言交互等自然语言处理方面的投入占到了 75%」。除了技术本身,还有技术在金融、电商特定应用场景下的深耕。「我们虽然是以情绪识别起家,但语义理解水平已经达到了中文领域的国内最好。」简仁贤对此十分自信。
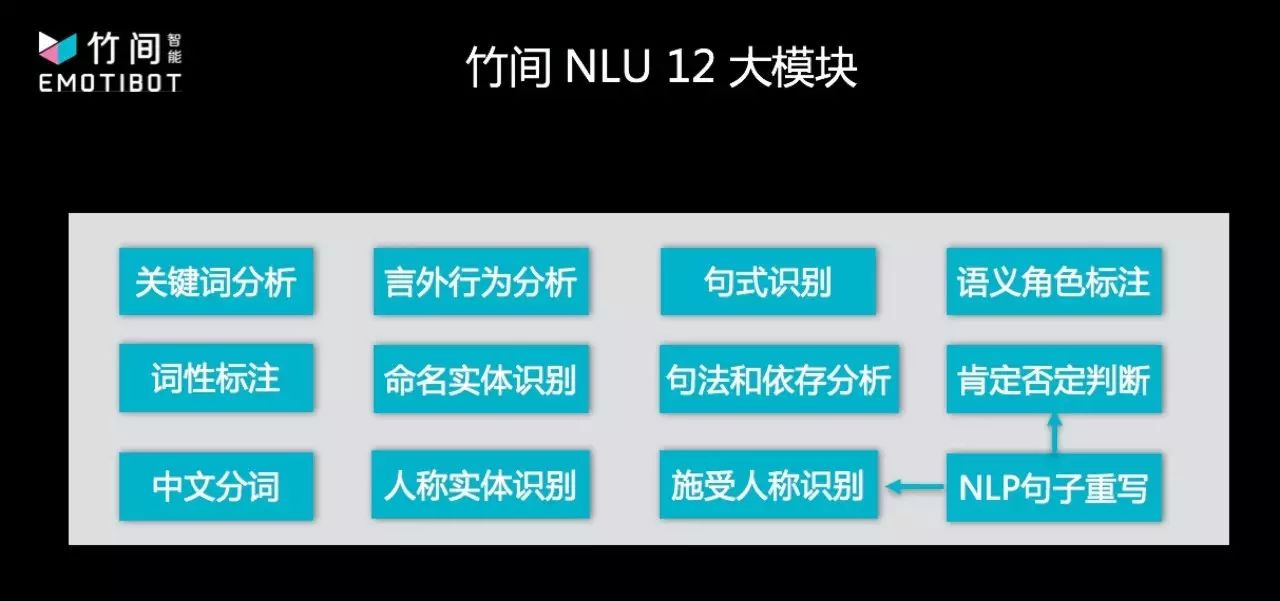
简仁贤介绍,他们从做情感情绪入手,深入到意图理解,再将意图与情绪情感应用到语义上面。语义的理解课题,就像情绪情感课题一样,纯粹的传统的 NLP 方法,或者纯新式的现代深度学习,都无法解决数十年中解决不了的问题。因此,竹间智能把做情绪同样的方式应用到语义理解中,以传统的 NLP 技术打底,加上语言学结构,再加上新的机器学习、深度学习的方法,融合地去把整个语义理解抽象化然后做降维,对于语义理解,真正做到语义层面的抽象和理解,而不是字词层面的分析。据介绍,竹间智能的语义理解算法包含四十余个模块,已经迭代到了第四代,尝试了对抗生成网络等众多新方法。
竹间智能研发团队超过 100 人,在过去两年,努力通过技术积累获得竞争力优势。「我们希望,在三到五年后,当服务机器人变得普遍,我们能够为所有机器人提供一个大脑,而且是一个有情感的大脑。」简仁贤如是说。
从能用、有用到好用的技术落地之路
如果把能交互的、有感情的机器人作为最终目标,除了不断推进技术之外,另一个目标就是让技术融入人类的生活与工作场景,做到「能用」、「有用」、「好用」。
技术目标可以划分为三个阶段。
例如,对于自然语言处理来说,第一阶段就是习得词性、语法结构分析能力,了解用户在使用语言时的一些固定搭配,能够通过制定规则来进行关键词检索,实现语料匹配;第二阶段是实现语义理解,能够在特定的场景中从对话的上下文中获得信息,并进行多轮对话;第三阶段则是在语义理解的基础上,理解交互中包含的感情,甚至能够通过推理获得语言中的言外之意。










