【新智元导读】
刚刚,DeepSeek的GitHub星数,超越了OpenAI!V3的Star数,如今已经碾压OpenAI最热门的项目。机器学习大神的一篇硬核博文,直接帮我们揭秘了如何仅用450美元,训出一个推理模型。
就在刚刚,历史性的一刻出现了。
DeepSeek项目在GitHub平台上的Star数,已经超越了OpenAI。
热度最高的DeepSeek-V3,Star数如今已达7.7万。
 做出这一发现的网友们,第一时间截下了图
做出这一发现的网友们,第一时间截下了图
可以说,这是开源AI历史上的一个里程碑!
而DeepSeek-R1,更是仅用了3周时间,就超越了「openai-cookbook」。
前有App Store登顶,今有GitHub超越,网友们高呼:永远不要低估开源社区的力量!
如今,DeepSeek的势头越来越猛。
相信大家都发现,DeepSeek的服务器简直要爆了。

甚至就在昨天,DeepSeek还不得不官宣:暂停API充值。
原因当然就是因为,用户的热情实在太火爆,服务器真扛不住了。
最近,关于DeepSeek的一些流传甚广的说法,也纷纷有专家辟谣了。
其中一个广为流传的说法是DeepSeek绕过了CUDA。
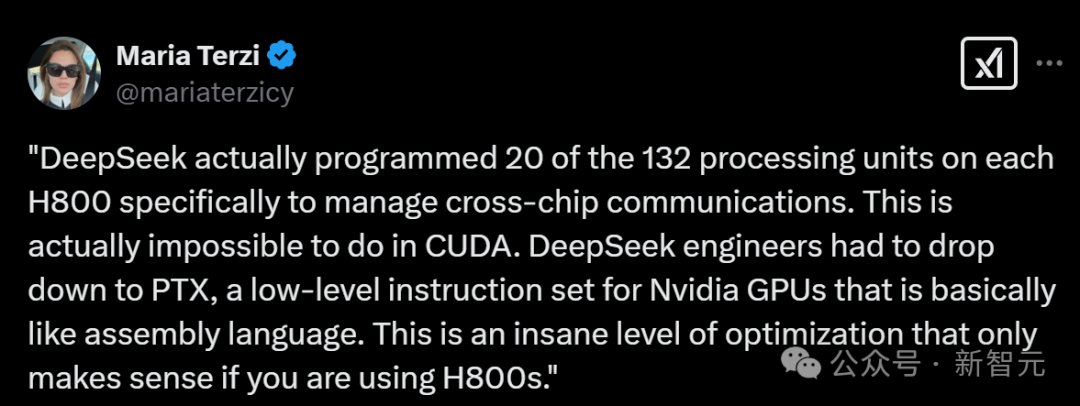
这源于DeepSeek的论文中提到,模型采用了PTX编程,通过这样的定制优化,让模型能更好地释放底层硬件的性能。
 「我们采用定制的PTX(并行线程执行)指令并自动调整通信块大小,这大大减少了L2缓存的使用和对其他SM的干扰」
「我们采用定制的PTX(并行线程执行)指令并自动调整通信块大小,这大大减少了L2缓存的使用和对其他SM的干扰」
严谨来说,DeepSeek通过编写PTX解决了跨芯片通信瓶颈,虽然复杂,但降低了开销、提升了效率。
本质上,PTX仍然是位于CUDA驱动层内部的一个组件,是英伟达CUDA编程模型的一部分,能将CUDA源代码(C/C++)转变为机器指令的一个中间阶段。
在运行时,PTX会进一步被编译成在GPU上运行的最终机器码(SASS)。
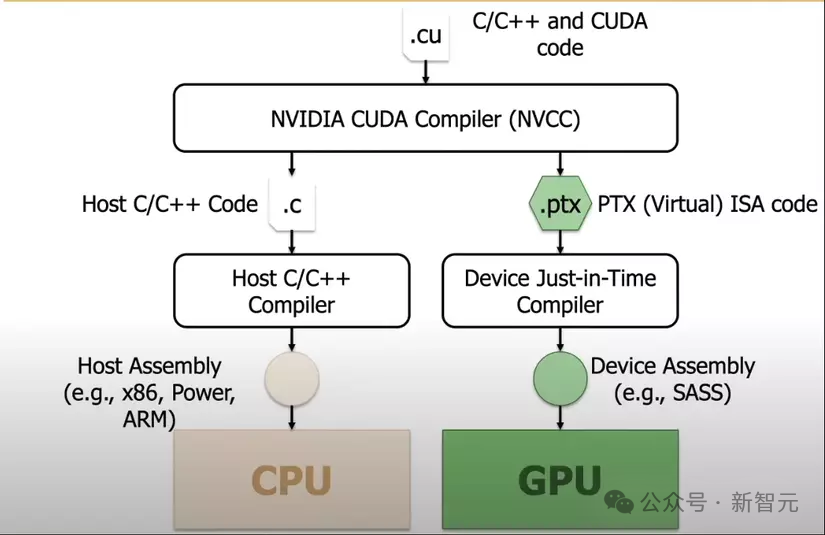
而DeepSeek团队的聪明之处就在于,用这种方法能更好地实现对底层硬件的编程和调用。
这种主动优化,无论在H800还是H100上都能提高通信互联效率。
因此,DeepSeek仍然没有摆脱CUDA生态。
而关于DeepSeek-R1的另一个谣言,就是R1的训练成本大约是600万美元。
 之所以有这个说法,来源于DeepSeek-V3论文中的相关论述
之所以有这个说法,来源于DeepSeek-V3论文中的相关论述
开发者大神Sebastian指出,很多人都混淆了DeepSeek-V3和DeepSeek-R1。(前者要早1个月)
其中,DeepSeek-V3中宣称的550万美元,是基于GPU成本、GPU小时数、数据集规模和模型规模等估算出来的。
但DeepSeek团队从没公开过R1确切的GPU小时数或开发成本,目前已有的任何成本估算都只是猜测。
除此之外,Stability AI前研究总监Tanishq Mathew Abraham也在最近的博文中指出,R1在V3基础上进行的强化学习,以及最终训练前团队的大量的小规模实验和消融研究都未包含在内。
更何况还有研究者的薪资,据传已经跟OpenAI、Anthropic等顶级机构的薪资相当(高达100万美元)。
DeepSeek V3和R1发布后,将怎样搅动此后的LLM江湖?
预算紧张的情况下,怎么开发推理模型?
最近,机器学习大神Sebastian Raschka的这篇长篇博文,为我们做出了硬核预测,并且破除了不少民间对DeepSeek的误解。

Sebastian表示,很多人都来询问自己对DeepSeek-R1的看法。
在他看来,这是一项了不起的成就。
作为一名研究工程师,他非常欣赏那份详细的研究报告,它让自己对方法论有了更深入的了解。
最令人着迷的收获之一,就是推理如何从纯强化学习行为中产生。
甚至,DeepSeek是在MIT许可下开源模型的,比Meta的Llama模型限制更少,令人印象深刻。
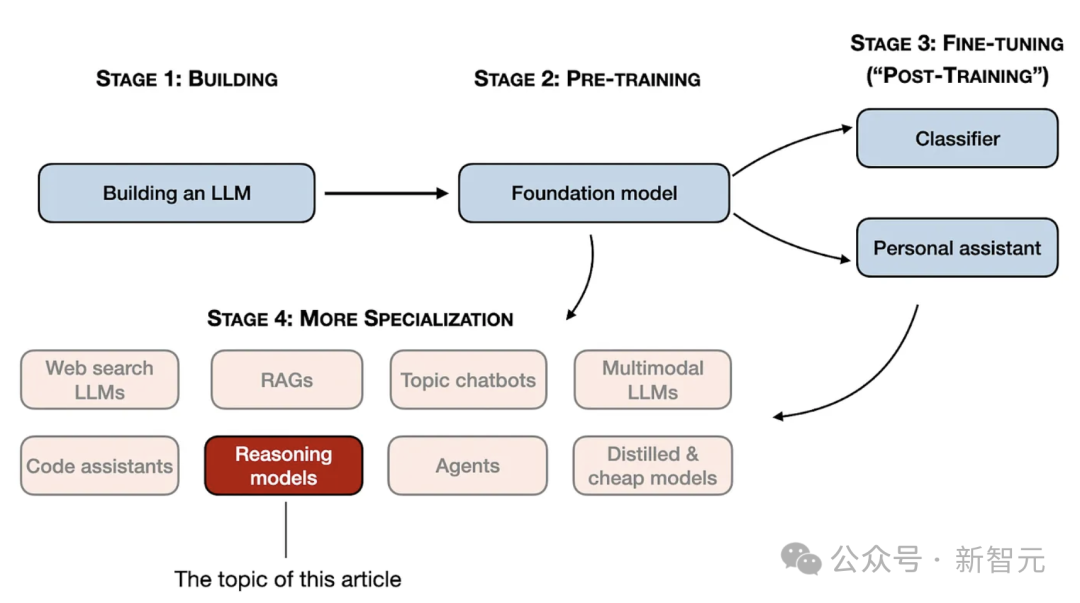
在本文中,Sebastian介绍了构建推理模型的四种方法,来提升LLM的推理能力。
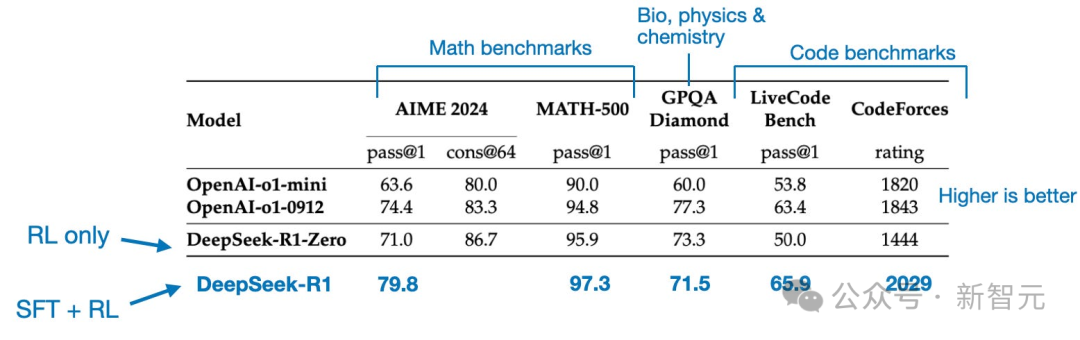
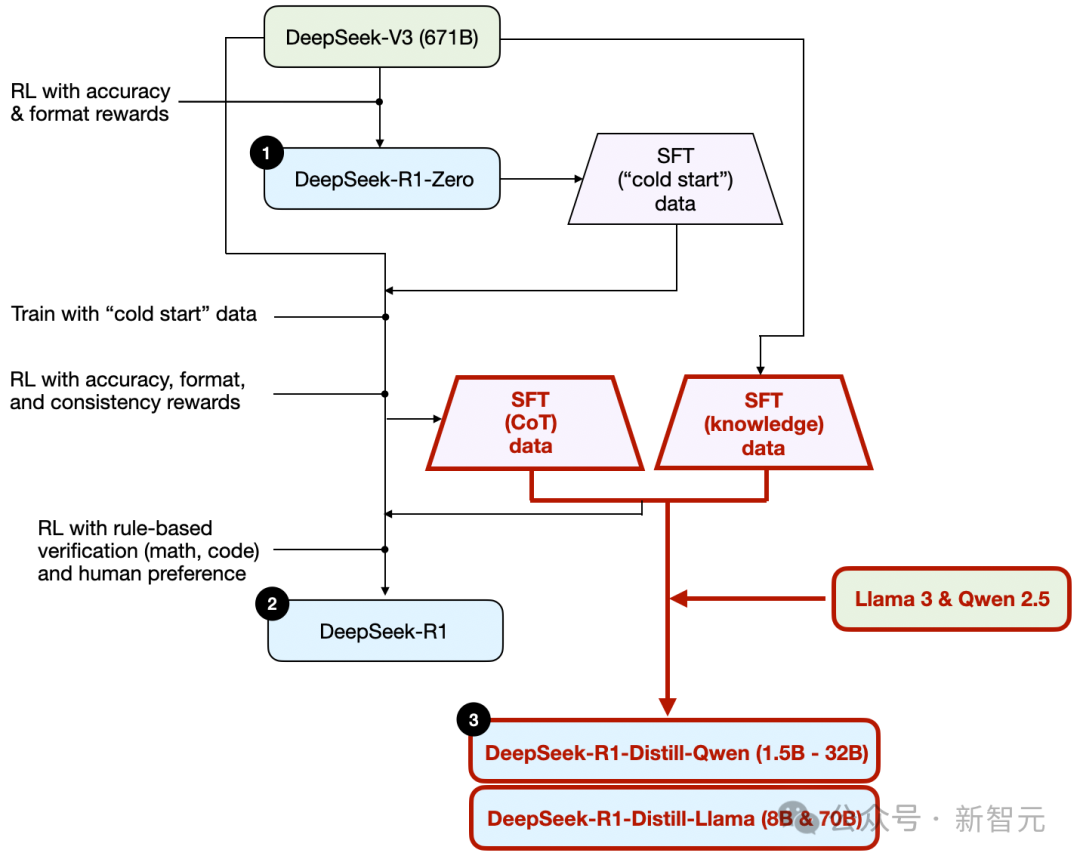
图中总结了DeepSeek R1的训练流程。
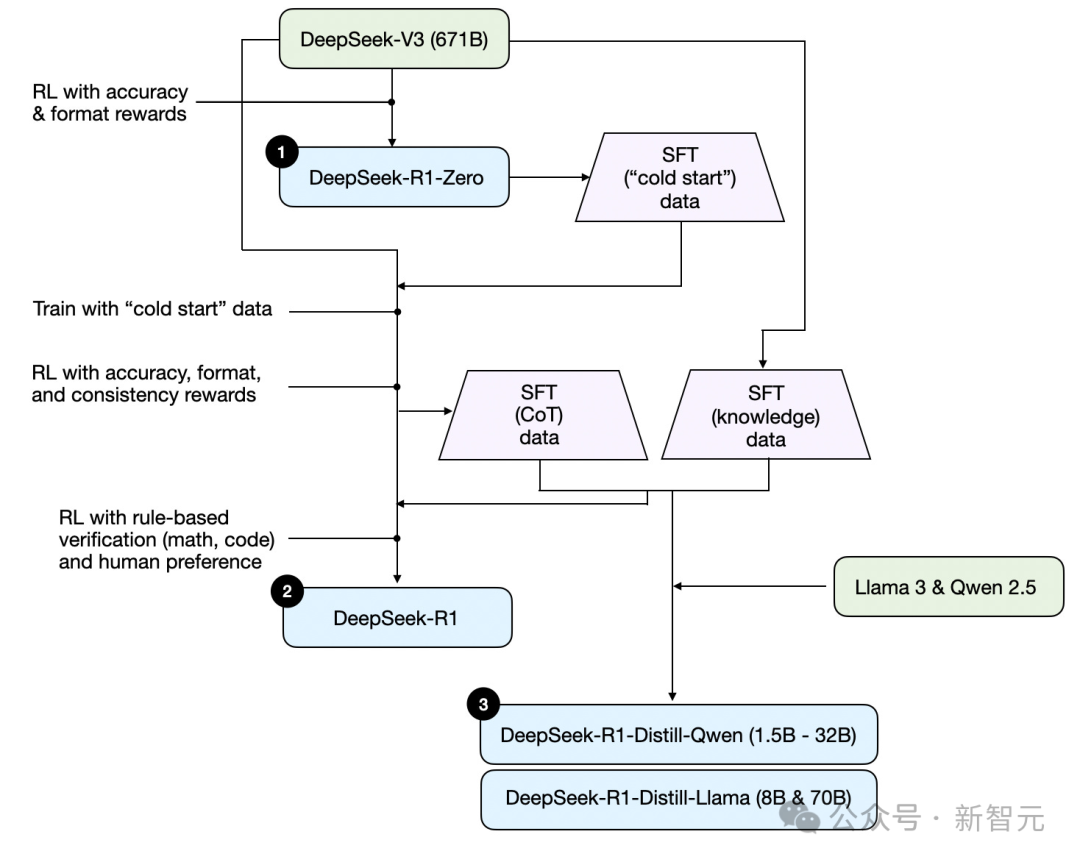
(1)DeepSeek-R1-Zero:该模型基于2024年12月发布的DeepSeek-V3。研究团队采用RL进行训练,并使用了两种奖励类型。这种方式称为冷启动训练,因为它没有采用RLHF中的SFT步骤。
(2)DeepSeek-R1:这是DeepSeek的旗舰推理模型,构建于DeepSeek-R1-Zero基础上。团队通过额外的SFT阶段和进一步的RL训练,对模型进行了优化。
(3)DeepSeek-R1-Distill:利用前述步骤中生成的SFT数据,团队对Qwen和Llama模型进行了微调,以增强它们的推理能力。尽管不是传统意义上的蒸馏,但该过程是用DeepSeek-R1的输出,来训练较小的模型(Llama 8B和70B,Qwen 1.5B–30B)。
推理时扩展
想要提升LLM的推理能力,或者是其他任何能力,有一种方法叫推理时扩展,就是在推理过程中增加计算资源,让输出的结果质量更高。
人类在解决复杂问题时,如果思考时间更充裕,往往能给出更好的答案。
有一种推理时扩展的简单方法,是巧妙的运用提示工程。思维链(CoT)提示法是一个经典例子,在处理复杂问题时,通常能得到更准确的结果。

另一种推理时扩展的方法是使用投票和搜索策略。
一个简单的例子是多数投票方法,让LLM生成多个答案,然后通过投票选出正确答案。
同样,也可以使用束搜索(beam search)和其他搜索算法来生成更好的响应。
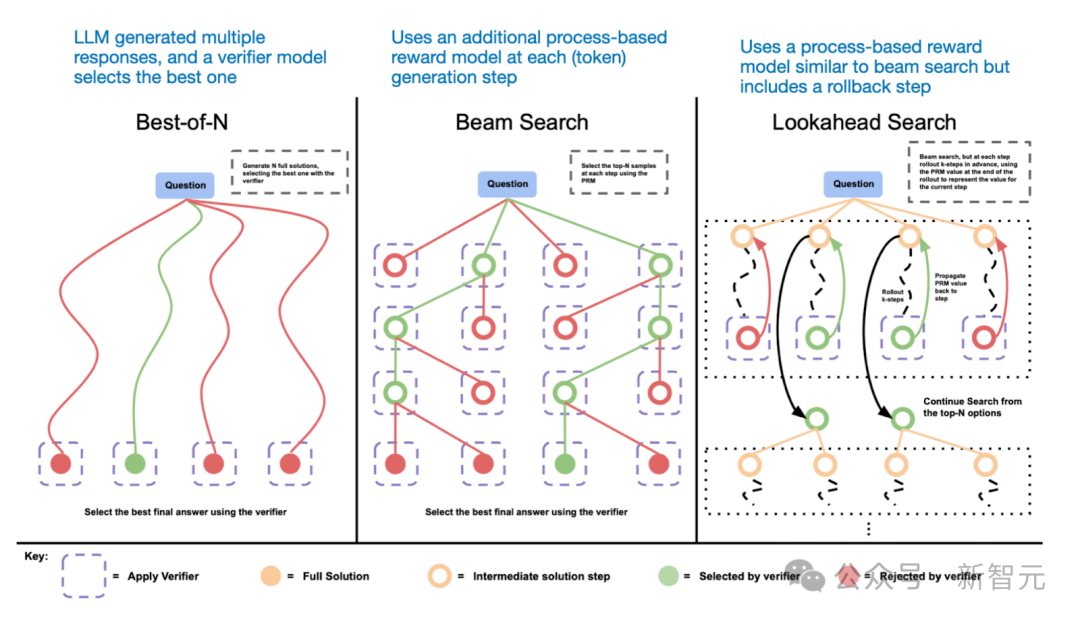
推测OpenAI的o1和o3模型使用了推理时扩展。此外,o1和o3可能还运用了与DeepSeek R1类似的RL流程来训练。
纯强化学习(RL)
DeepSeek R1论文中的一个亮点是,推理行为可以通过纯强化学习(RL)产生。
通常在RL训练之前,会先进行SFT,但DeepSeek-R1-Zero完全通过RL训练,没有初始的SFT阶段。
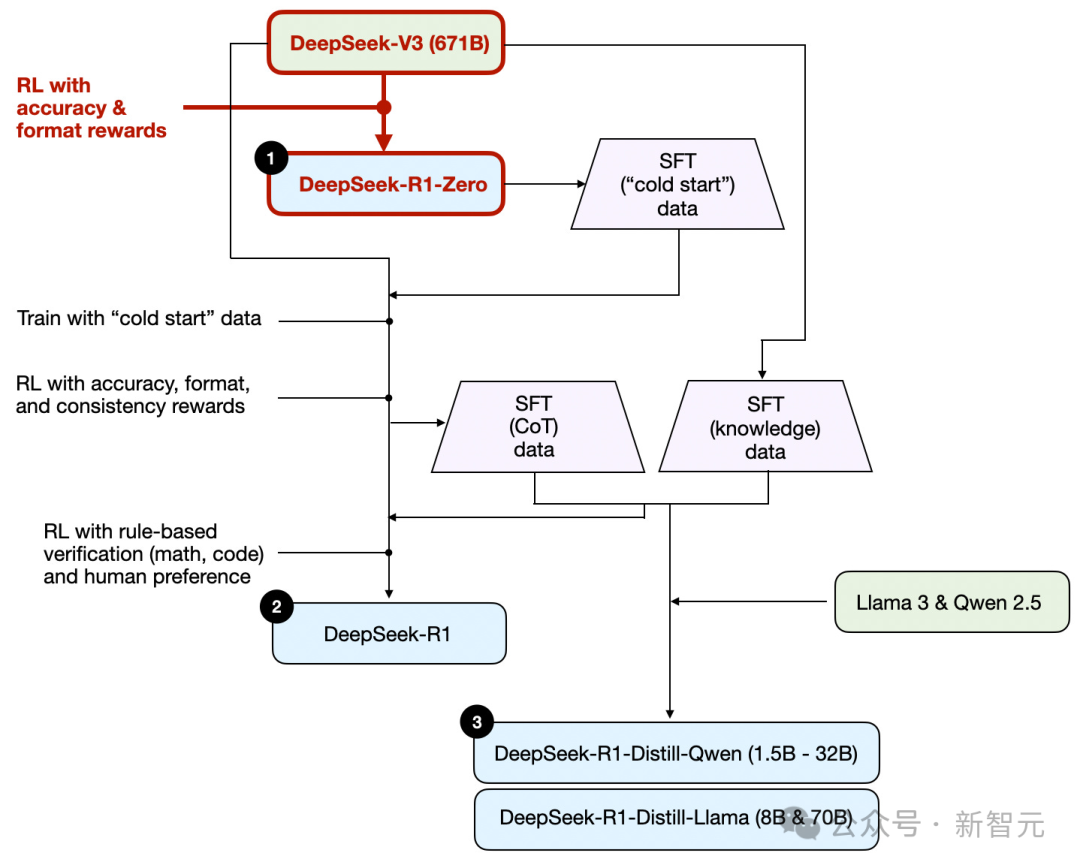
DeepSeek-R1-Zero的一个关键区别是它跳过了SFT阶段。
在奖励机制上,DeepSeek没有采用基于人类偏好的奖励模型,而是采用了准确性奖励和格式奖励。
- 准确性奖励,是用LeetCode编译器来验证编程答案,并用确定性系统评估数学回答。
- 格式奖励,则靠LLM评判器,保证回答符合预期格式,比如把推理步骤放在标签里。
让人意外的是,靠这种方法,LLM就能发展出基本的推理能力。
研究人员观察到「顿悟时刻」:模型开始在回答中生成推理过程,即使没有专门训练它这么做。

尽管R1-Zero并不是性能最优的推理模型,但它通过生成中间的思考步骤展示了推理能力。这证明用纯强化学习(RL)开发推理模型是可行的。
监督微调和强化学习(SFT+RL)
旗舰模型DeepSeek-R1通过结合额外的SFT和RL,提升了模型的推理表现。
在RL之前进行SFT是常见的做法,标准的RLHF流程就是如此。OpenAI的o1模型很可能也是用类似方法开发的。

如图所示,团队用DeepSeek-R1-Zero生成了冷启动SFT数据。通过指令微调训练模型,接着又进行了一轮RL。
在这一轮RL中,保留了DeepSeek-R1-Zero的准确性奖励和格式奖励,还新增了一致性奖励,来避免语言混杂。
RL结束后,又开始新一轮SFT数据收集。在这个阶段,用最新的模型生成了60万条CoT SFT示例,同时用DeepSeek-V3基础模型创建了另外20万条SFT示例。
上述样本随后被用于另一轮RL训练。在这个阶段,对于数学和编程问题,还是用基于规则的方法进行准确性奖励。对于其他类型的问题,则用人类偏好标签来评判。
经过多轮训练,DeepSeek-R1的性能有了显著提升。
纯监督微调(SFT)和蒸馏
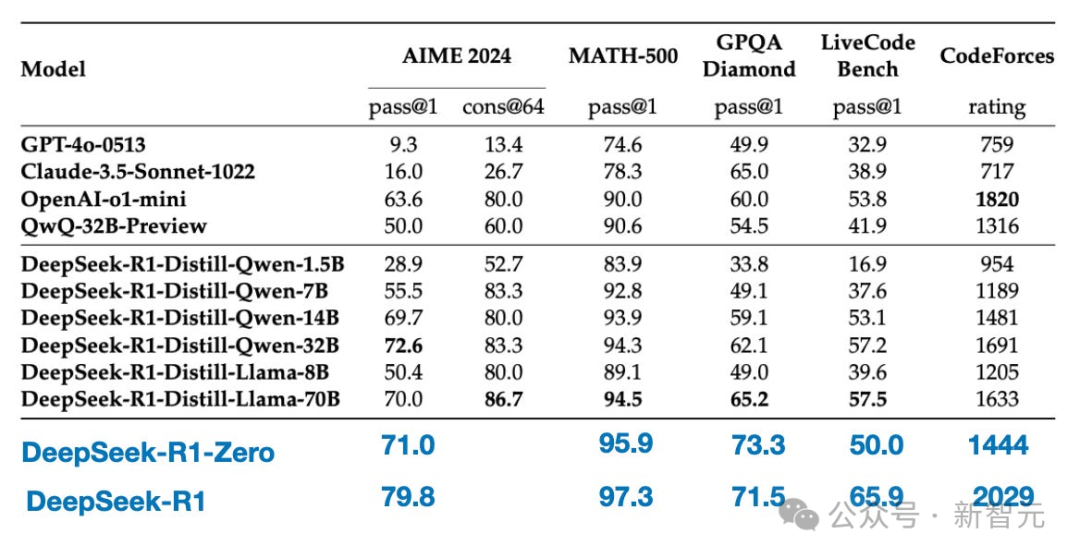
到目前为止,已经介绍了三种用于改进LLM推理能力的方法,最后是模型「蒸馏」。
这里「蒸馏」是指用较大LLM生成的数据集对较小的LLM(如Llama 8B和70B以及Qwen 2.5模型,范围从0.5B到32B)进行指令微调。
实际上,这个蒸馏过程中的SFT数据集,和之前用来训练DeepSeek-R1的数据集是一样的。
为什么开发蒸馏模型?可能有两个关键原因:
1
较小的模型更高效。
小模型运行成本更低,还能在配置较低的硬件上运行。对研究人员来说很有吸引力。
2
纯SFT的案例研究。
这些模型展示了在没有RL的情况下,单纯靠SFT能把模型优化到什么程度。
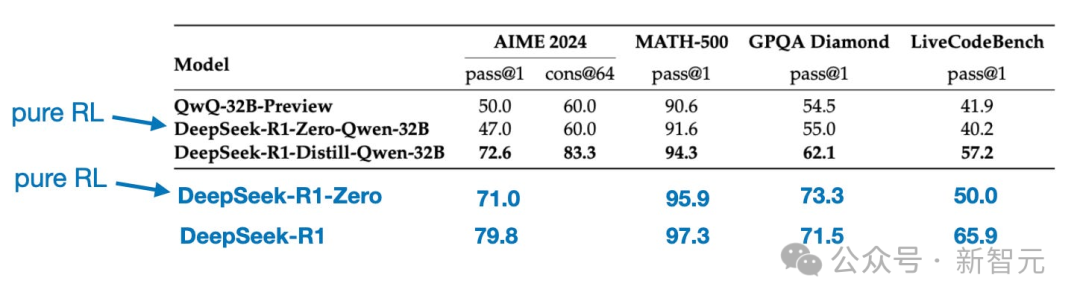
团队将DeepSeek-R1-Zero中的纯RL方法直接应用于Qwen-32B。
结果表明,对于较小的模型,蒸馏远比纯RL更有效。
仅靠RL可能不足以让小模型具备强大的推理能力,在高质量推理数据上进行SFT,或许是对小模型更有效的策略。
接下来一个有趣的方向是把RL+SFT和推理时扩展结合起来,OpenAI的o1很有可能是这样做的,只不过它可能基于一个比DeepSeek-R1更弱的基础模型。










