
作者:乐雨泉(yuquanle),湖南大学在读硕士,研究方向机器学习与自然语言处理。
欢迎志同道合的朋友和我在公众号
"AI 小白入门"
一起交流学习。

01
写在前面
近些年来,注意力机制一直频繁的出现在目之所及的文献或者博文中,可见在
NLP
中算得上是个相当流行的概念,事实也证明其在 NLP 领域散发出不小得作用。
这几年的顶会 paper 就能看出这一点。
本文深入浅出地介绍了
近些年的自然语言中的注意力机制包括从
起源、变体到评价指标
方面。
据 Lilian Weng 博主[1]总结以及一些资料显示,Attention 机制最早应该是在视觉图像领域提出来的,这方面的工作应该很多,历史也比较悠久。
人类的视觉注意力虽然存在很多不同的模型,但它们都基本上归结为给予需要重点关注的目标区域(注意力焦点)更重要的注意力,同时给予周围的图像低的注意力,然后随着时间的推移调整焦点。
而直到 Bahdanau 等人[3]发表了论文《Neural Machine Translation by Jointly Learning to Align and Translate》,该论文使用类似
Attention
的机制在机器翻译任务上将翻译和对齐同时进行。
这个工作目前是最被认可为是第一个提出
Attention
机制应用到 NLP 领域中的工作,值得一提的是,该论文2015年被 ICLR 录用,截至现在,
谷歌引用量为5596
,可见后续nlp在这一块的研究火爆程度。
注意力机制首先从人类直觉中得到,在nlp领域的机器翻译任务上首先取得不错的效果。简而言之,深度学习中的注意力可以广义地解释为重要性权重的向量:
为了预测一个元素,例如句子中的单词,使用注意力向量来估计它与其他元素的相关程度有多强,并将其值的总和作为目标的近似值
。
既然注意力机制最早在 NLP 领域应用于机器翻译任务,那在这个之前又是怎么做的呢?
传统的基于短语的翻译系统通过将源句分成多个块然后逐个词地翻译它们来完成它们的任务,这导致了翻译输出的不流畅。
不妨先来想想我们人类是如何翻译的?
我们首先会阅读整个待翻译的句子,然后结合上下文理解其含义,最后产生翻译。
从某种程度上来说,神经机器翻译(NMT)的提出正是想去模仿这一过程。而在NMT的翻译模型中经典的做法是由编码器 - 解码器架构制定(encoder-decoder),用作 encoder 和 decoder 常用的是循环神经网络。
这类模型大概过程是首先将源句子的输入序列送入到编码器中,提取最后隐藏状态的表示并用于解码器的输入,然后一个接一个地生成目标单词,这个过程广义上可以理解为不断地将前一个时刻 t-1 的输出作为后一个时刻 t 的输入,循环解码,直到输出停止符为止。
通过这种方式,NMT解决了传统的基于短语的方法中的局部翻译问题:
它可以捕获语言中的长距离依赖性,并提供更流畅的翻译。
但是这样做也存在很多缺点,譬如,RNN 是健忘的,这意味着前面的信息在经过多个时间步骤传播后会被
逐渐消弱乃至消失
。
其次,在解码期间没有进行对齐操作,因此在解码每个元素的过程中,焦点分散在整个序列中。对于前面那个问题,LSTM、GRU 在一定程度能够缓解。而后者正是 Bahdanau 等人重视的问题。
02
Seq2Seq 模型
在介绍注意力模型之前,不得不先学习一波 Encoder-Decoder 框架,虽然说注意力模型可以看作一种通用的思想,本身并不依赖于特定框架(比如文章[15]:Learning Sentence Representation with Guidance of Human Attention),但是目前大多数注意力模型
都伴随在 Encoder-Decoder 框架
下。
Seq2seq 模型最早由 bengio 等人[17]论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》。
随后 Sutskever 等人[16]在文章《Sequence to Sequence Learning with Neural Networks》中提出改进模型即为目前常说的 Seq2Seq 模型。
从广义上讲,它的目的是将输入序列(源序列)转换为新的输出序列(目标序列),这种方式不会受限于两个序列的长度,换句话说,两个序列的长度可以任意。
以 NLP 领域来说,序列可以是句子、段落、篇章等,所以我们也可以把它看作处理由一个
句子(段落或篇章)
生成另外一个
句子(段落或篇章)
的通用处理模型。
对于句子对,我们期望输入句子 Source,期待通过 Encoder-Decoder 框架来生成目标句子Target。
Source 和 Target 可以是同一种语言,也可以是两种不同的语言,若是不同语言,就可以处理翻译问题了。
若是相同语言,输入序列 Source 长度为篇章,而目标序列 Target 为小段落则可以处理文本摘要问题 (目标序列 Target 为句子则可以处理标题生成问题)等等等。
seq2seq 模型通常具有编码器 - 解码器架构:
-
编码器 encoder: 编码器处理输入序列并将序列信息压缩成固定长度的上下文向量(语义编码/语义向量 context)。期望这个向量能够比较好的表示输入序列的信息。
-
解码器 decoder: 利用上下文向量初始化解码器以得到变换后的目标序列输出。
早期工作仅使用编码器的最后状态作为解码器的输入。
-
编码器和解码器都是循环神经网络,比较常见的是使用 LSTM 或 GRU。

编码器 - 解码器模型
03
前面谈到在 Seq2Seq 结构中,encoder 把所有的输入序列都编码成一个统一的
语义向量 context
,然后再由 decoder 解码。而 context 自然也就成了限制模型性能的瓶颈。
譬如机器翻译问题,当要翻译的句子较长时,一个 context 可能存不下那么多信息。除此之外,只用编码器的最后一个隐藏层状态,感觉上都不是很合理。
实际上当我们翻译一个句子的时候,譬如:
Source: 机器学习-->Target: machine learning
。当decoder要生成"machine"的时候,应该更关注"机器",而生成"learning"的时候,应该给予"学习"更大的权重。
所以如果要改进Seq2Seq结构,一个不错的想法自然就是利用 encoder 所有隐藏层状态解决 context 限制问题。
Bahdanau等人[3]把 attention 机制用到了神经网络机器翻译(NMT)上。传统的 encoder-decoder 模型通过 encoder 将 Source 序列编码到一个固定维度的中间语义向量 context,然后再使用 decoder 进行解码翻译到目标语言序列。
前面谈到了这种做法的局限性,而且,Bahdanau 等人[3]在其文章的摘要中也说到这个 context 可能是提高这种基本编码器 - 解码器架构性能的瓶颈,那 Bahdanau 等人又是如何尝试缓解这个问题的呢? 别急,让我们来一探究竟。
作者为了缓解中间向量 context 很难将 Source 序列所有重要信息压缩进来的问题,特别是对于那些很长的句子。提出在机器翻译任务上在 encoder–decoder 做出了如下扩展:将翻译和对齐联合学习。
这个操作在生成 Target 序列的每个词时,用到的中间语义向量context是Source序列通过 encoder 的隐藏层的加权和,而传统的做法是只用 encoder 最后一个时刻输出
 作为 context,这样就能保证在解码不同词的时候,Source 序列对现在解码词的贡献是不一样的。
作为 context,这样就能保证在解码不同词的时候,Source 序列对现在解码词的贡献是不一样的。
想想前面那个例子:Source: 机器学习-->Target: machine learning (假如中文按照字切分)。
decoder 在解码"machine"时,"机"和"器"提供的权重要更大一些,同样,在解码"learning"时,"学"和"习"提供的权重相应的会更大一些,这在直觉也和人类翻译也是一致的。
通过这种 attention的 设计,作者将 Source 序列的每个词(通过encoder的隐藏层输出)和 Target 序列 (当前要翻译的词) 的每个词巧妙的建立了联系。
想一想,翻译每个词的时候,都有一个语义向量,而这个语义向量是Source序列每个词通过 encoder 之后的隐藏层的加权和。
由此可以得到一个 Source 序列和 Target序列的对齐矩阵,通过可视化这个矩阵,可以看出在翻译一个词的时候,Source 序列的每个词对当前要翻译词的重要性分布,这在直觉上也能给人一种可解释性的感觉。
论文中的图也能很好的看出这一点:

生成第t个目标词

更形象一点可以看这个图:
现在让我们从
公式层面
来看看这个东东 (加粗变量表示它们是向量,这篇文章中的其他地方也一样)。 假设我们有一个长度为n的源序列x,并尝试输出长度为m的目标序列y:

作者
采样bi
directional RNN作为encoder(实际上这里可以有很多选择),具有前向隐藏状态
 和后向隐藏状态
和后向隐藏状态
 。为了获得词的上下文信息,作者采用简单串联方式将前向和后向表示拼接作为encoder的隐藏层状态,公式如下:
。为了获得词的上下文信息,作者采用简单串联方式将前向和后向表示拼接作为encoder的隐藏层状态,公式如下:

对于目标(输出)序列的每个词(假设位置为t),decoder网络的隐藏层状态:

其中
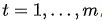 ,
语义向量
,
语义向量
 是源(输入)序列的隐藏状态的加权和,权重为对齐分数:
是源(输入)序列的隐藏状态的加权和,权重为对齐分数:

(注意:这里的score函数为原文的a函数,原文的描述为:
 is an alignment model)
is an alignment model)
对齐模型基于
 (在i时刻的输入)和
(在i时刻的输入)和
 (在t时刻的输出)的匹配程度分配分数
(在t时刻的输出)的匹配程度分配分数
 。
是定义每个目标(输出)单词应该考虑给每个源(输入)隐藏状态的多大的权重(这恰恰反映了对此时解码的目标单词的贡献重要性)。
。
是定义每个目标(输出)单词应该考虑给每个源(输入)隐藏状态的多大的权重(这恰恰反映了对此时解码的目标单词的贡献重要性)。
在Bahdanau[3]的论文中,作者采用的对齐模型为前馈神经网络,该网络与所提出的系统的所有其他组件共同训练。因此,score函数采用以下形式,tanh用作非线性激活函数,公式如下:

其中
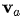 ,
,
 和都是在对齐模型中学习的权重矩阵。对齐分数矩阵是一个很好的可解释性的东东,可以明确显示源词和目标词之间的相关性。
和都是在对齐模型中学习的权重矩阵。对齐分数矩阵是一个很好的可解释性的东东,可以明确显示源词和目标词之间的相关性。

对齐矩阵例子
而decoder每个词的条件概率为:

g为非线性的,可能是多层的输出
 概率的函数,
概率的函数,
 是RNN的隐藏状态,
是RNN的隐藏状态,
 为语义向量。
为语义向量。
随着注意力机制的广泛应用,在某种程度上缓解了源序列和目标序列由于距离限制而难以建模依赖关系的问题。现在已经涌现出了一大批基于基本形式的注意力的不同变体来处理更复杂的任务。让我们一起来看看其在不同NLP问题中的注意力机制。
其实我们可能已经意识到了,对齐模型的设计不是唯一的,确实,在某种意义上说,根据不同的任务设计适应于特定任务的对齐模型可以看作设计出了新的attention变体,让我们再回过头来看看这个对齐模型(函数):
 。再来看看几个代表性的work。
。再来看看几个代表性的work。


-
Luong[4]等人文献包含了几种方式:

-
以及Luong[4]等人还尝试过location-based function:
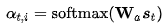
这种方法的对齐分数仅从目标隐藏状态学习得到。
-
Vaswani[6]等人的Scaled Dot-Product(^):

细心的童鞋可能早就发现了这东东和点积注意力很像,只是加了个scale factor。当输入较大时,softmax函数可能具有极小的梯度,难以有效学习,所以作者加入比例因子
 。
。
-
Cheng[7]等人的Self-Attention(&)可以关联相同输入序列的不同位置。 从理论上讲,Self-Attention可以采用上面的任何 score functions。在一些文章中也称为“intra-attention” 。
Hu[7]对此分了个类:

前面谈到的一些Basic Attention给人的感觉能够从序列中根据权重分布提取重要元素。而Multi-dimensional Attention能够
捕获不同表示空间中的term之间
的多个交互,这一点简单的实现可以通过直接将多个单维表示堆叠在一起构建。
Wang[8]等人提出了coupled multi-layer attentions,该模型属于多层注意力网络模型。作者称,通过这种多层方式,该模型可以进一步利用术语之间的间接关系,以获得更精确的信息。
05
Hierarchical Attention
再来看看Hierarchical Attention,Yang[9]等人提出了Hierarchical Attention Networks,看下面的图可能会更直观:

Hierarchical Attention Networks
这种结构能够反映文档的层次结构。模型在单词和句子级别分别设计了两个不同级别的注意力机制,这样做能够在构建文档表示时区别地对待这些内容。
Hierarchical attention 可以相应地构建分层注意力,自下而上(即,词级到句子级)或自上而下(词级到字符级),以提取全局和本地的重要信息。
自下而上的方法上面刚谈完。那么自上而下又是如何做的呢?让我们看看Ji[10]等人的模型:

Nested Attention Hybrid Model
和机器翻译类似,作者依旧采用encoder-decoder架构,然后用word-level attention对全局语法和流畅性纠错,设计character-level attention对本地拼写错误纠正。
那Self-Attention又是指什么呢?
Self-Attention(自注意力),也称为intra-attention(内部注意力),是关联单个序列的不同位置的注意力机制,以便计算序列的交互表示。它已被证明在很多领域十分有效比如机器阅读,文本摘要或图像描述生成。
比如Cheng[11]等人在机器阅读里面利用了自注意力。当前单词为红色,蓝色阴影的大小表示激活程度,自注意力机制使得能够学习当前单词和句子前一部分词之间的相关性。

当前单词为红色,蓝色阴影的大小表示激活程度
比如Xu[12]等人利用自注意力在图像描述生成任务。注意力权重的可视化清楚地表明了模型关注的图像的哪些区域以便输出某个单词。

我们假设序列元素为
 ,其匹配向量为
,其匹配向量为
 。让我们再来回顾下前面说的基本注意力的对齐函数,attention score通过
。让我们再来回顾下前面说的基本注意力的对齐函数,attention score通过
 计算得到,由于是通过将外部u与每个元素
计算得到,由于是通过将外部u与每个元素









