选自OpenAI
机器之心编译
作者: Ryan Lowe等
参与:吴攀、Smith
让智能体(agent)学会合作一直以来都是人工智能领域内的一项重要研究课题,一些研究者也认为合作能力是实现通用人工智能(AGI)的必要条件。而除了合作,让智能体学会竞争可能也是实现这一目标的一大关键。近日,OpenAI、麦吉尔大学和加州大学伯克利分校的几位研究者提出了一种「用于合作-竞争混合环境的多智能体 actor-critic」。之后,OpenAI 发布博客对这项研究进行了解读,机器之心对该解读文章进行了编译介绍。
让智能体能在其中为资源进行竞争的多智能体环境是实现通用人工智能之路的垫脚石。
多智能体环境(multi-agent environment)有两个实用的属性:第一,存在一个自然的全套考验——环境的难度取决于你的竞争者的能力(而且如果你正在和你的克隆体进行对抗的话,环境就可以精确地匹配出你的技术水平)。第二点,多智能体环境没有稳定的平衡态(equilibrium):无论一个智能体多么聪明,总会有让它变得更智能的压力。这些环境和传统环境相比有很大的不同,并且要想掌控它们我们还需要大量的研究。
我们已经设计了一个新算法 MADDPG(Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments),可用于多智能体环境中的中心化学习(centralized learning)和去中心化执行(decentralized execution),让智能体可以学习彼此合作和竞争。

用来训练 4 个红色智能体追逐 2 个绿色智能体的 MADDPG。红色智能体已经学会和「同伴」进行团队合作来追逐单个绿色智能体,以获得更高的奖励。同时,绿色智能体学会了彼此分散,并且当它们中的一个正在被追逐时,另一个就会尝试接近水源(蓝色圆圈)以躲避红色智能体。
MADDPG 对 DDPG(https://arxiv.org/abs/1509.02971)这种强化学习算法进行了延伸,并从 actor-critic 强化学习技术上获得了灵感;也有其他研究团队正在探索这些思路的变体和并行实现的方法,参阅以下论文:
Learning Multiagent Communication with Backpropagation:https://arxiv.org/abs/1605.07736
Learning to Communicate with Deep Multi-Agent Reinforcement Learning:https://arxiv.org/abs/1605.06676
Counterfactual Multi-Agent Policy Gradients:https://arxiv.org/abs/1705.08926
我们把仿真实验中的每一个智能体都当作「演员(actor)」,并且每个演员都从「批评家(critic)」那里获得建议,从而来帮助 actor 去决策哪些动作在训练过程中应该被强化。传统上,critic 会设法去预测在一个特定状态中一个动作的价值(value,即将来期望得到的奖励),这个奖励会被智能体(actor)用来更新它自己的策略(policy)。和直接使用奖励(reward)相比,这无疑是更加可靠的,因为它可以根据具体情况来进行调整。为了让这种方法适用于多智能体全局协同(globally-coordinated)的情况,我们改进了我们的 critic,使它们可以获得所有智能体的观察结果和动作,如下图所示。

我们的智能体无需在测试的时候有一个中心 critic;它们可以基于它们的观察以及它们对其它智能体的行为的预测来采取行动。因为一个中心化的 critic 是为每个智能体独立学习到的,所以我们的方法也可以在多智能体之间构造任意的奖励结构,包括拥有相反奖励的对抗案例。


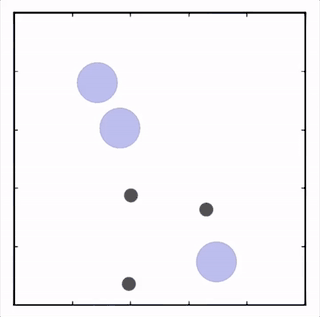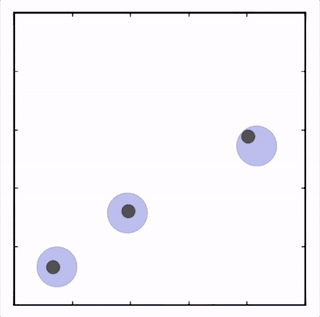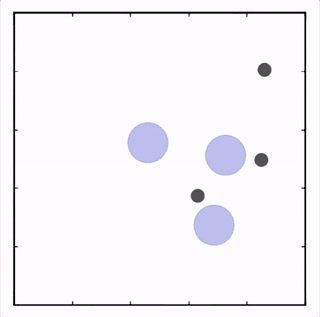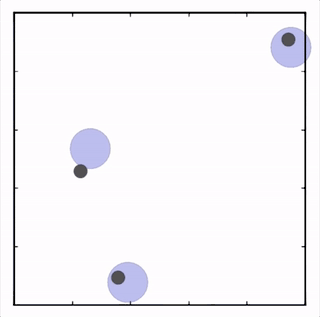
我们在许多不同的任务上对我们的方法进行了测试,其在所有任务上的表现都优于 DDPG。在上面的动画中你可以看到,从上到下:两个 AI 智能体试图到达特定地点,学会了分开行动以向其对手智能体隐藏其目标位置;一个智能体与另一个智能体沟通目标的名称;三个智能体协调,在不碰撞彼此的情况下到达目标。


使用 MADDPG(上)训练的红色智能体表现出了比那些使用 DDPG(下)训练的智能体更复杂的行为。其中,红色智能体试图通过绿色的森林来追逐绿色的智能体,同时绕过黑色的障碍。我们的智能体可以捕捉到更多智能体,而且也看得出来,我们的智能体比 DDPG 方法训练的智能体合作能力更强。
传统强化学习不给力的地方
传统的去中心化强化学习方法(DDPG、actor-critic 学习和深度 Q 学习等等)难以在多智能体环境中学习,因为在每一个时间步,每个智能体都会尝试学习预测其它智能体的动作,同时还要采取自己的行动。有竞争的情形中,尤其如此。MADDPG 使用了一种中心化的 critic 来为智能体提供补充,这些补充信息包括它们同伴的观察和潜在动作,从而可以将一个不可预测的环境转换成可预测的。
使用策略梯度方法会带来进一步的难题:因为这会带来很高的方差,当奖励不一致时很难学习到正确的策略。我们还发现添加 critic 虽然可以提高稳定性,但是仍然不能应对我们的部分环境,比如合作交流(cooperative communication)。似乎在训练中考虑其它智能体的动作对学习合作策略来说非常重要。
初步研究
在我们开发 MADDPG 之前,在使用去中心化技术时,我们注意到如果说话者在表达自己的去处时不一致,那么听话者智能体(listener agent)就常常会学会忽略说话者。然后该智能体会将所有与该说话者的信息关联的权重设置为 0,从而有效地「静音」。一旦这种情况发生,就很难通过训练恢复了;因为缺乏任何反馈,所以该说话者将永远无法知道它说的是否正确。为了解决这个问题,我们研究了最近一个分层强化学习项目(https://arxiv.org/abs/1703.01161)中提出的技术,这可以让我们迫使听话者在其决策过程中整合该说话人的表述。但这个解决方案没有作用,因为尽管其强迫听话者关注说话者,但对说话者了解应该说什么相关内容却毫无助益。我们的中心化 critic 方法有助于解决这些难题,可以帮助说话者了解哪些表述可能与其它智能体的动作相关。更多结果请参看下面的视频:
下一步
在人工智能研究领域,智能体建模(agent modeling)可谓历史悠久,很多场景都已经得到过了研究。过去的很多研究都只考虑了少量时间步骤和很小的状态空间。深度学习让我们可以处理复杂的视觉输入,而强化学习可以给我们带来学习长时间行为的工具。现在,我们可以使用这些能力来一次性训练多个智能体,而无需它们都了解环境的动态(环境会在每个时间步骤如何变化),我们可以解决大量涉及到交流和语言的问题,同时学习环境的高维信息。以下为原论文的摘要:
论文:用于合作-竞争混合环境的多智能体 Actor-Critic(Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments)
论文地址:https://arxiv.org/pdf/1706.02275.pdf

我们探索了用于多智能体域(multi-agent domains)的深度强化学习方法。我们开始分析了传统算法在多智能体案例中的困难:Q 学习(Q-learning)因为环境固有的非平稳性(non-stationarity)而受到了挑战,而策略梯度(policy gradient)则饱受随智能体数量增长而增大的方差之苦。然后我们提出了对 actor-critic 方法的一种调整,其考虑了其它智能体的动作策略(action policy),能够成功学习到需要复杂多智能体协调的策略。此外,我们还引入了一种为每个智能体使用策略集成(ensemble of policies)的训练方案,可以得到更加稳健的多智能体策略。我们表明了我们的方法相对于已有的方法在合作和竞争场景中的能力,其中智能体群(agent populations)能够发现各种物理和信息的协调策略。
原文链接:https://blog.openai.com/learning-to-cooperate-compete-and-communicate/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]
点击阅读原文,查看机器之心官网↓↓↓









