
From 差评
微信号:chaping321
记得上个星期,人民日报被删的那条 Twitter 闹了不小风波。。
 可惜虚晃一枪,什么也没有发生,倒是李彦宏的那条朋友圈很有意思~
可惜虚晃一枪,什么也没有发生,倒是李彦宏的那条朋友圈很有意思~

李总对百度的技术非常有信心,并自认为在中国,凭借技术和创新方面可以打败谷歌,并不担心谷歌入华。
 结果转天就被网友们打脸。。
结果转天就被网友们打脸。。
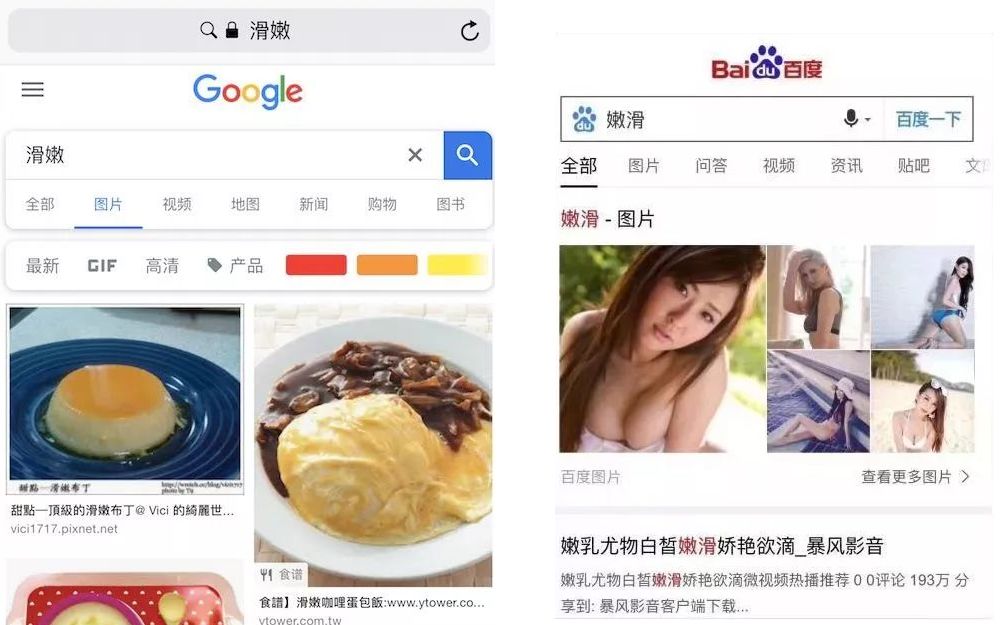
百度上的 “ 滑嫩 ”、“ 鲜嫩 ” 等全是美女图片,而谷歌上搜索这些内容,出现的则是一些美食等。emmm。。高下立判。。
被爆料后,百度程序猿们加班加点,总算是把大家揪出来的敏感词汇处理了。
 可是,今天发生的一件事,让我意识到,不仅仅是搜索算法,谷歌在另外一个方面早就超过了百度。。
可是,今天发生的一件事,让我意识到,不仅仅是搜索算法,谷歌在另外一个方面早就超过了百度。。
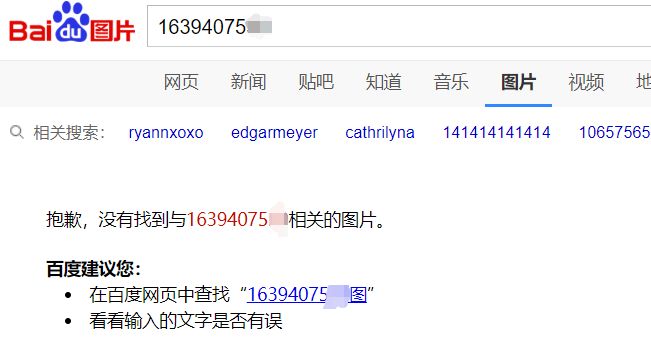
下午我在调查黑产,用百度搜索了一个 QQ 号,网页版的内容基本就是胡乱凑的,而图片搜索空空如也,什么结果也没有。。
不死心的我又用谷歌试了一下,结果。。
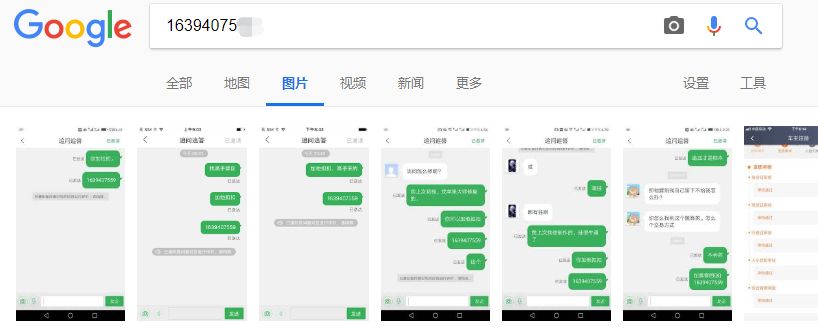
给你们看一下大图。。
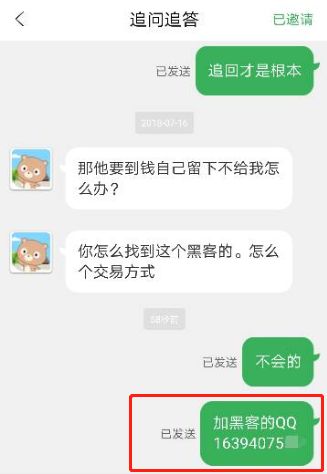
居然真的把我想要的搜索了出来,而且,因为这个 QQ 涉及黑产,所以骗子只把它放在图片里,并没有放到网页上。
也就是说,Google 现在已经开始对互联网上的图片文本做了识别提取,并建立索引!
在我们的印象中,搜索引擎一般会基于图片旁边的文字描述给图片打标签,或者利用神经网络识别图片上的物体,并不会扫描读取图片上的文本内容。

用神经网络给图片分类
所以很多时候你搜索图片上的文本,搜索引擎不会给你返回正确结果。
不知道什么时候,谷歌已经偷摸给自己的搜索引擎升了个级!?
为了看一下谷歌的图片识别文本已经达到什么程度,我开启了疯狂验证模式。。
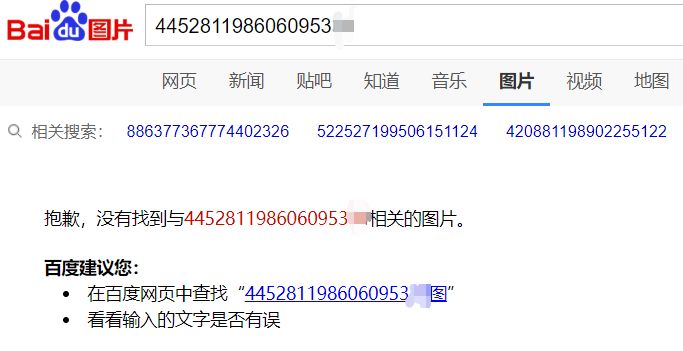
首先,要验证下,是不是图片上数字都可以被识别出来~
Emmm,先搞一个身份证号搜索看看。这个是百度的结果:
再用谷歌搜索一下?
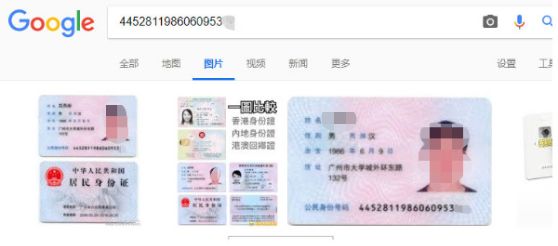
额。。有没有感到一丝丝害怕?!想想自己有没有曾经在网上上传过身份证照片?如果被泄露到互联网上,可以直接通过身份证号获得身份证图片,这后果有点严重。。
 我借用了一个小伙伴的身份证前几位,分别在百度和谷歌上搜索 “ 1201031993 ”,百度依然什么也搜不出来,而谷歌返回了一堆结果。
我借用了一个小伙伴的身份证前几位,分别在百度和谷歌上搜索 “ 1201031993 ”,百度依然什么也搜不出来,而谷歌返回了一堆结果。
这些图片上无一例外的有 1201031993 这几个数字。。
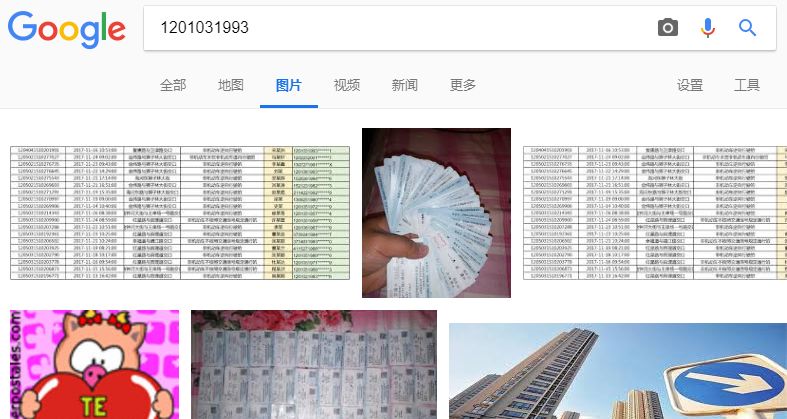
令我意外的是,谷歌在对图片文本提取时,已经不仅仅是用的最简单最基础的图像识别。
像上面第二张图片中那几个数字是竖过来,但谷歌依旧识别正确,说明谷歌的识别算法会自动匹配文本的旋转角度。。

 如果不是纯数字,带上英文呢?只在图片上有,网页上没有出现过的文本还真不好找,最后差评君试了个汽车图片,把车牌号 “ A·K8896 ” 搜了一下。。
如果不是纯数字,带上英文呢?只在图片上有,网页上没有出现过的文本还真不好找,最后差评君试了个汽车图片,把车牌号 “ A·K8896 ” 搜了一下。。
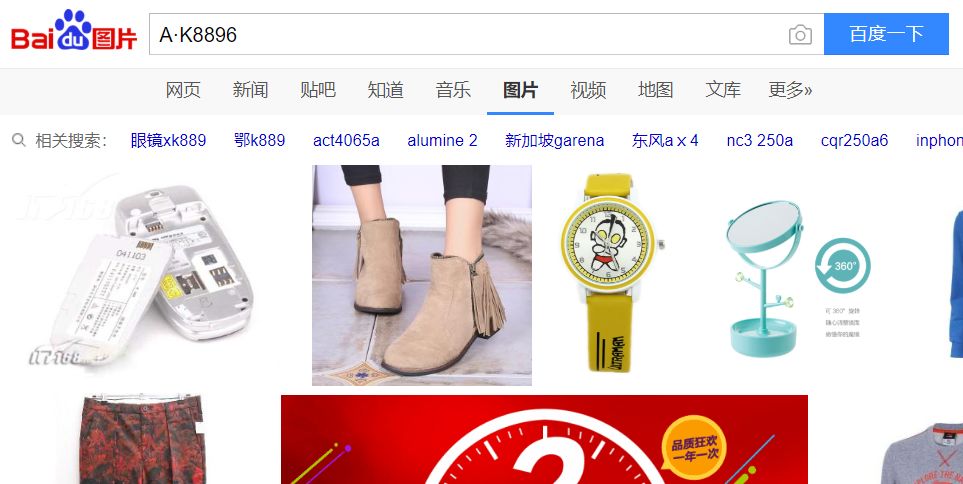
嗯,百度出来的都是八竿子打不着的图片,正常。
那。谷歌呢。。?
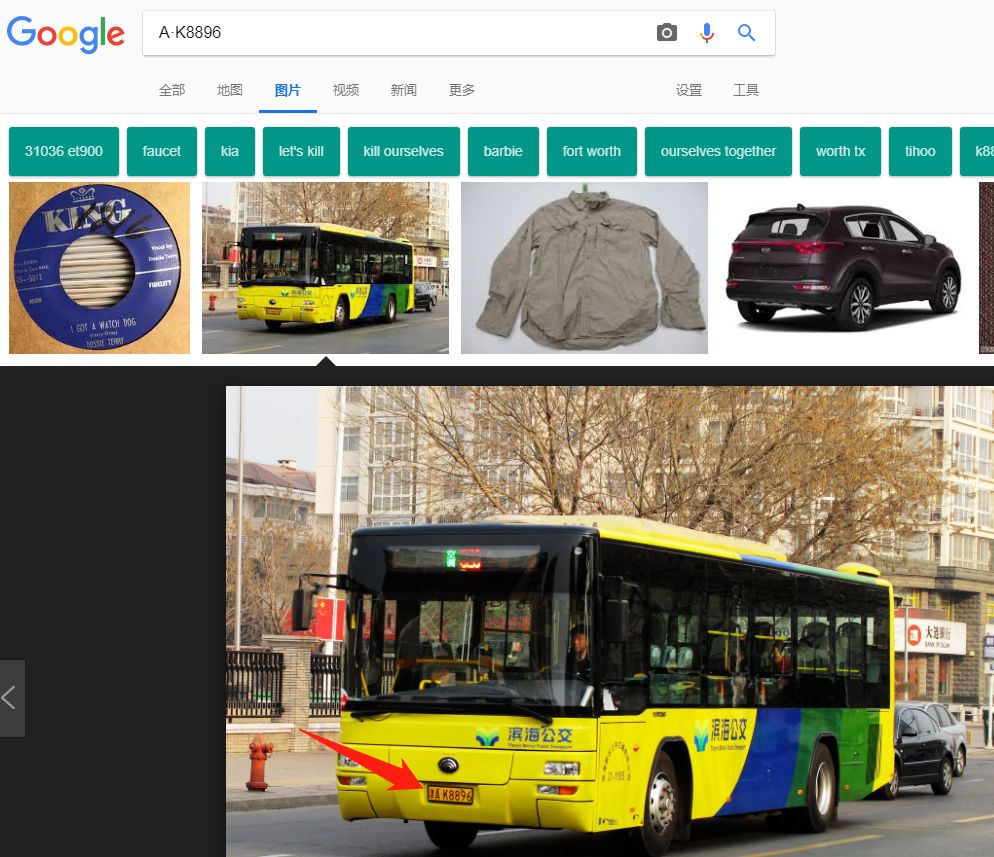
大家也可以试试自家的车牌能不能被搜到
 给,这是我十年份的膝盖,请收下。。
给,这是我十年份的膝盖,请收下。。
这张图片正是我随机找的一张汽车图片,谷歌这项技术,连隐藏在车身下不那么明显的车牌号都揪了出来,够强大。。
最后一个问题,谷歌能不能识别图片中的中文?
 经过试验,还好还好,中文目前还是谷歌图片未攻克的堡垒,目前看来,谷歌只对图片中的字母和数字进行了识别。
经过试验,还好还好,中文目前还是谷歌图片未攻克的堡垒,目前看来,谷歌只对图片中的字母和数字进行了识别。
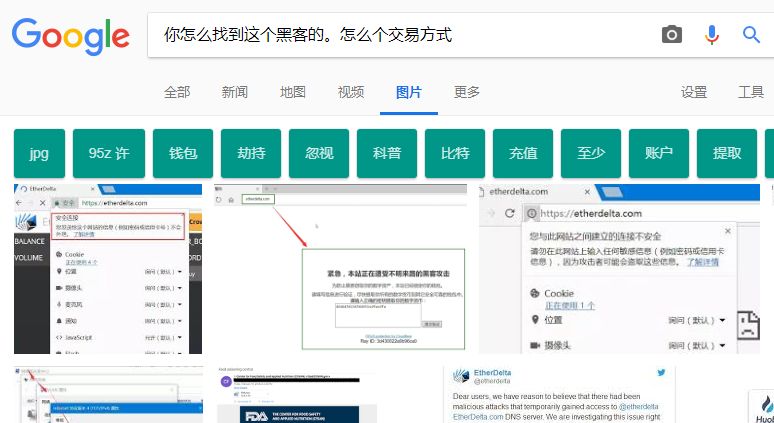
搜索了文中第一个例子中图片的中文,
没有返回该图片
不过我好奇的是,谷歌搜索引擎是什么时候开始识别图片文本的?
谷歌没有给出过官方消息,相关的讨论也寥寥无几,2016 年的时候谷歌的大佬还否认过谷歌在识别图片文本。
 不过在去年 7 月的时候,有一个博客主跟我有相似的发现,所以至少去年谷歌就已经偷偷升了级~
不过在去年 7 月的时候,有一个博客主跟我有相似的发现,所以至少去年谷歌就已经偷偷升了级~

其实,谷歌很早就积累了图片的文本识别相关技术—— OCR ( 光学字符识别 )。
这个技术本身并不难,最早谷歌将 OCR 应用在书籍扫描转换文本上,这样只要你搜索书中的一句话,它就能推给你正确的书籍。
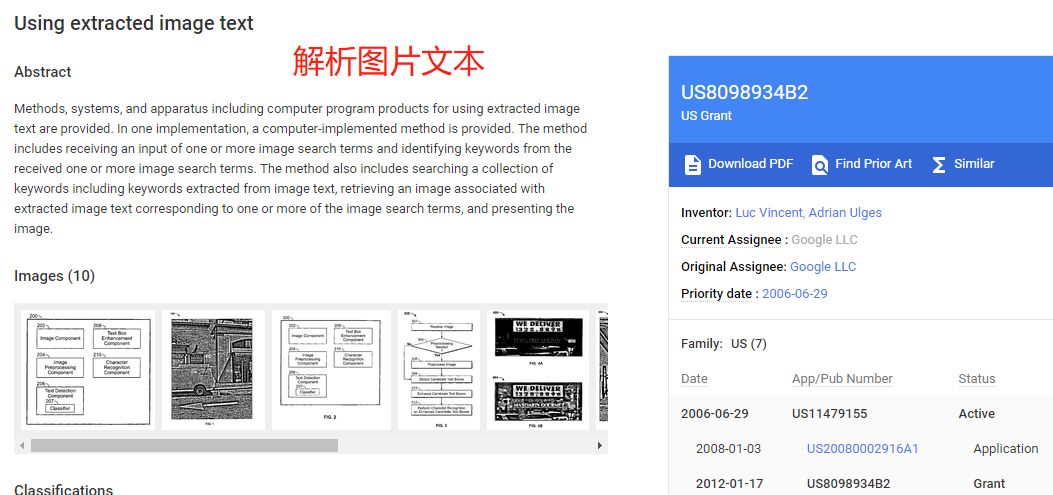
谷歌解析图片文本的专利
现在,谷歌已经将这项技术应用在互联网的所有图片上。
 我之所以感到惊讶,是因为我们每天要产生大量图片,光在 Facebook 和 Instagram 上每天就产生近 4 亿张图片,微博上每天产生1.5 亿张图片,保守估计互联网上每天要多出 8 亿图片。
我之所以感到惊讶,是因为我们每天要产生大量图片,光在 Facebook 和 Instagram 上每天就产生近 4 亿张图片,微博上每天产生1.5 亿张图片,保守估计互联网上每天要多出 8 亿图片。
而谷歌对每张图片都进行 OCR 算法处理,获取里面的文本信息,这是一项海量的工程,消耗太大了。。但谷歌还是做到了。。

Google 实时翻译也是用的 OCR 技术
这样大大提高了大家使用搜索引擎的效率,让大家更容易找到自己想要的结果~
不过在以前,正是因为大家默认搜索不出图片上的文本,才会放心的把一些资料保存成图片放到网上。
 现在随着这项技术的成熟,恐怕图片也不再保险。。谁能想到一个身份证号,就把身份证图片都搜出来了呢?
现在随着这项技术的成熟,恐怕图片也不再保险。。谁能想到一个身份证号,就把身份证图片都搜出来了呢?
如何兼顾技术和隐私,恐怕未来需要谷歌好好处理一下~
本文系授权发布,From 差评,微信号:chaping321,欢迎分享到朋友圈,未经许可不得转载,INSIGHT视界 诚意推荐













