作者简介:坦梅·巴克希(Tanmay Bakshi)年仅13岁,是算法及认知开发员、年轻作者和TEDx演讲者。他将在洛杉矶召开的开源峰会上发表主题演讲,题为“开源赋予的灵感――技术和人工智能的现在与未来”。他还将在技术讨论会(BoF)上探讨DeepSPADE。

本文作者Tanmay Bakshi讨论了DeepSPADE,该系统可用于区分公共社区论坛上的垃圾帖子和非垃圾帖子。

这篇博文介绍了本人构建的一个深度学习系统,名为DeepSPADE(又叫DeepSmokey),并介绍了它如何被用来打造更好的互联网社区。
首先介绍一下DeepSPADE是什么、它有何用途?
DeepSPADE的全称是“深度垃圾内容检测”,基本想法是,机器学习执行自然语言分类任务,以区分公共社区论坛上的垃圾帖子和非垃圾帖子。
Stack Exchange(SE)就是这样一个网站,该网络下面设有超过169个不同的网络论坛,涵盖从编程、人工智能、个人理财到Linux的各种主题!
Stack Overflow(SO)是SE的一个社区论坛,专门介绍编程,它是世界上最受编程人员欢迎的论坛网站。自上线以来的七年间提出的问题超过1450万个,其中650万个问题已回答,由此可见它到底有多受欢迎。
然而,与任何公共网站一样,Stack Overflow充斥着垃圾内容。虽然这个社区的大多数成员对于分享知识或者寻求他人的帮助真正感兴趣,但是有些人试图往网站乱灌垃圾内容。实际上,SO上每天平均新增30多个垃圾帖子。
为了解决这个问题,一群名为Charcoal SE的程序员设计和开发了SmokeDetector系统。SmokeDetector使用大量的正则表达式(RegEx),根据内容试图找出垃圾信息。
我是机器学习的大力支持者,一发现他们将正则表达式用于垃圾内容分类后,立即喊道:“为何不用深度学习?!”这个想法受到了Charcoal社区的欢迎;实际上,他们之前没有采用深度学习的原因是,他们当中谁也没有搞过机器学习。我加入了Charcoal社区,开始开发DeepSPADE,帮助实现他们的使命。
DeepSPADE模型
DeepSPADE结合使用卷积神经网络(CNN)和门控循环单元(GRU)来运行这项分类任务。它用来实际了解被提供的自然语言的词向量(word-vector)是在实际的模型训练开始之前训练的word2vec vector。然而,在模型训练期间,向量经过微调以实现最佳性能。
神经网络(NN)用Keras来设计,使用Tensorflow(TF)后端(相比Theano,TF提供了相当大的性能优势),图1显示了模型本身很长的示意图:
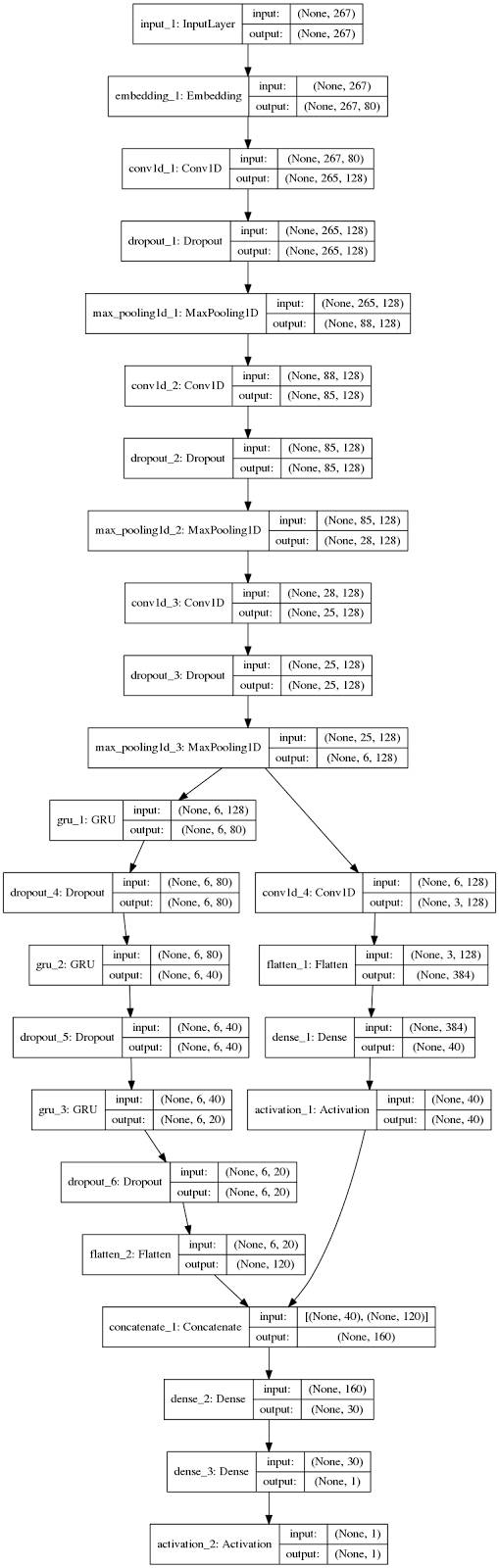
正如你所见,我设计的这个模型很深。事实上,该模型不光很深,还是个平行模型。
不妨先从很多人会有的一个问题入手:为什么要使用CNN和GRU?何不仅仅使用那些层的其中之一?
答案在于这两层的实际工作机理的底层。下面不妨细解:
CNN了解没有时间限制的数据中的模式。这意味着CNN并不以任何特定的顺序查看自然语言,它只是如同查看任何一组数据那样,没有顺序地查看自然语言。要是有一个非常特定的词,我们又知道它几乎总是与垃圾内容或非垃圾内容有关,这大有帮助。
GRU或通常意义上的递归神经网络(RNN)了解按时间序列加以明确排列的数据模式。这意味着RNN了解词的顺序,这有所帮助,因为一些词基于使用方式会传达全然不同的概念。
实际上,为了解释这个组合为何如此强大,不妨看一下DeepScale系统针对16000个测试行的准确性的下列“演变过程”:
65%-卷积神经网络的基准准确性
69%-更深的卷积神经网络
75%-引入了更高数量和质量的数据
79%-对模型作了小幅改进
85%-随CNN模型一并引入了LSTM(无并行机制)
89%-更大的嵌入尺寸(embedding size)、更深的CNN和LSTM
96%-使用GRU而不是LSTM,更多的Dropout正则化,更多的池化(Pooling)和更大的嵌入尺寸
98.76%-使用并行模型和更大的嵌入尺寸
答案再次在于CNN本身是如何工作的:它有很强大的过滤掉噪音、查看某些内容信号的能力,另外,性能(训练/推理时间)比RNN高得多。
所以,一开始3个Conv1D + Dropout + MaxPool组充当过滤器。它们创建数据的诸多表示形式,每个组描述的数据有不同的角度。它们还在保留信号的同时竭力减小数据的大小。
之后,那些组的结果分为两个不同的部分:
为什么使用并行机制?因为两个网络都试图找到不同类型的数据。GRU查找有序数据,而CNN查找“通常的”数据。
一旦收集到两个神经网络的意见,这些意见就串连起来,并通过另一个Dense层来馈送,Dense层了解模式和关系,清楚每个神经网络的结果或意见何时来得更重要。它进行这种动态加权,并馈入到另一个Dense层,从而给出模型的输出。
最后,该系统现在可以添加到SmokeDetector,其自动加权系统可以开始整合深度学习的结果!
此外,该系统完全在Linux服务器上加以训练、测试和使用!当然,Linux对于这类软件而言是个了不起的平台,那是由于实际上没有硬件方面的限制,又由于大多数优秀的开发软件主要在Linux上得到支持(Tensorflow、Theano、MXNet、Chainer和CUDA等)。
与大家一样,我也喜欢开源软件。虽然这个项目目前还不是开源项目,但所有人很快会迎来惊喜!











