作者 | 夕颜、一一
出品 | AI科技大本营(ID:rgznai100)
导读:7 月 31 日晚,自然语言处理领域最大顶会 ACL 2019 在佛罗伦萨进行到了第四天(7 月 29 日-8 月 1 日),当天,组委会最终从提名论文奖项 32 篇候选论文中公布了今年的八个论文奖项,包含 1 篇最佳长论文奖、1 篇最佳短论文奖、5 篇杰出论文奖、1 篇最佳 Demo 论文奖,其中最佳长论文的获奖者被来自中国科学院大学、中国科学院计算技术研究所、腾讯 WeChat AI、华为诺亚方舟实验室、伍斯特理工学院等机构的联合论文所斩获。此外,来自南京理工大学的 Rui Xia 和 Zixiang Ding 获得了杰出论文奖。
此次 8 篇获奖论文的 31 位作者中,有 10 位是华人作者,其中 4 篇的一作都是华人作者。
获奖详情

最佳长论文
标题:
Bridging the Gap between Training and Inference for Neural Machine Translation
作者:
Wen Zhang(中国科学院计算技术研究所), Yang Feng(中国科学院大学), Fandong Meng(腾讯 WeChat AI), Di You(伍斯特理工学院)、Qun Liu(刘群,华为诺亚方舟实验室,
CSDN AI开发者大会在邀演讲嘉宾
)
论文链接:
https://arxiv.org/abs/1906.02448
GitHub 链接:
https://github.com/jasonwu0731/trade-dst
摘要:
神经机器翻译(NMT)以预测以上下文词为条件的下一个词的方式,按顺序生成目标词。在训练时,它以 ground truth 词作为上下文进行预测,而在推理时,它必须从头开始生成整个序列,这种差异导致误差累积。此外,词级训练要求所生成的序列与
ground truth
序列之间严格匹配,这导致对不同但合理的翻译过度校正。
本文中,作者不仅通过
ground truth
序列中,而且还从在训练期间的预测序列中采样上下文词来解决这些问题,其中预测序列是具有句子级别的最优选择。在中英和 WMT'14 英德翻译任务的实验结果表明,他们的方法在多个数据集上有显著效果。

最佳短论文
标题:
Do you know that Florence is packed with visitors? Evaluating state-of-the-art models of speaker commitment
作者:
Nanjiang Jiang、Marie-Catherine de Marneffe(美国俄亥俄州立大学)
论文链接:
https://www.aclweb.org/anthology/P19-1412
摘要:
当一位演讲者问你知道佛罗伦萨挤满了游客吗?我们让她相信佛罗伦萨挤满了游客,但是,如果她问你是否认为佛罗伦萨挤满了游客?推断说话者承诺对于信息提取和问答是至关重要的。本文中,作者通过分析具有挑战性的自然数据集上模型误差的语言相关性,来探索语言缺陷驱动说话者承诺模型的错误模式的假设。他们在 CommitmentBank 上评估了两个最先进的说话者承诺模型。
他们发现,语言学信息模型优于基于 LSTM 的模型,这表明需要语言学知识来捕获这些具有挑战性的自然数据。他们按语言学特征的细分项目揭示了不对称的错误模式:虽然模型在某些类别上取得了良好的表现(例如,否定),但它们无法泛化到自然语言中的各种语言学结构(例如条件语句),作者们突出了改进的方向。
最佳 Demo 论文
标题:
OpenKiwi: An Open Source Framework for Quality Estimation
作者:
Fabio Kepler, Jonay Trenous, Marcos Treviso, Miguel Vera and André F. T. Martins(Unbabel、Instituto de Telecomunicac¸oes)
论文链接:
https://www.aclweb.org/anthology/P19-3020
摘要:
作者介绍了一个基于 PyTorch 的用于翻译质量评估的开源框架OpenKiwi。OpenKiwi支持词级和句子级质量评估系统的训练和测试,实现了 WMT 2015-18 质量评估活动的获奖系统。他们在WMT 2018(英德 SMT 和 NMT)两个数据集上对 OpenKiwi 进行基准测试,在词级任务和句子级任务中展现了最佳性能。
杰出论文

标题:
Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
作者:
Rui Xia,Zixiang Ding(南京理工大学)
论文链接:
https://www.aclweb.org/anthology/P19-1096
本文提出一项有趣的任务,联合学习来识别文本中的情绪及其原因。其次,它提出一个有趣的新模型,两种不同类型的多任务体系结构,一种任务是独立的,另一种是交互的。最后,根据互动的方向,可以改进情绪的精确度或原因的 recall。

标题:
Studying Summarization Evaluation Metrics in the Appropriate Scoring Range
作者:
Maxime Peyrard(洛桑联邦理工学院(EPFL))
论文链接:
https://www.aclweb.org/anthology/P19-1502
本文解决了自动文本摘要任务中一个长期存在的问题:如何衡量摘要内容的合适性?其次,它为“内容重要性”提出了 3-part 的理论模型,此外,它还提出了评价指标并对标准指标和人类判断进行了对比
。

标题:
Transferable Multi-Domain State Generator for Task-Oriented
作者:
Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher and Pascale Fung(香港科技大学、Salesforce 研究院)
论文链接:
https://arxiv.org/abs/1905.08743
本文解决了传统但尚未解决的问题:对话状态跟踪中的不可见状态,证明了可以从用户话语中生成对话状态。其次,论文中提出的新方法可以扩展到大型值集并处理以前不可见的值。除了展示最新的研究成果外,本文还研究了针对新领域的小样本学习。

标题:
Zero-Shot Entity Linking by Reading Entity Descriptions
作者:
Lajanugen Logeswaran, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, Jacob Devlin and Honglak Lee(密歇根大学、谷歌研究院)
论文链接:
https://arxiv.org/
pdf
/1906.0
7
348.pdf
本文提出了一种新的词义消歧系统,并注重提高不常见单词和未见过的单词的表现。其次,sense selection任务被作为一项持续任务对待,并且用到了资源组合。最终的结果具有洞察力,达到了最佳结果。

标题:
We need to talk about standard splits
作者:
Kyle Gorman(纽约市立大学)、Steven Bedrick(俄勒冈健康与科学大学)
论文链接:
http://wellformedness.com/papers/gorman-bedrick-2019.pdf
GitHub链接:
https://github.com/jojonki/arXivNotes/issues/241
本文质疑了评估NLP模型时广泛使用的方法,其次,使用了 POS 标记来阐释问题。还建议提出系统排名应该基于使用随机分组的重复评估方法。
投稿数翻倍,接收率却创新低
据组委会公布的数据显示,本届 ACL 的注册参会人数达到了 3160 人,这比 ACL 2018 的参会人数(1322 人)足足多出两倍多。
在论文数量上,ACL 2019 相比去年也有大幅提高,论文投稿数量达 2905 篇,几乎是 ACL 2018(1544 篇)投稿的两倍。此外,大会共接收 660 篇论文,包括 447 篇长论文、213 篇短论文。
组委会还统计了提交论文数量排名前 15 位的国家(每个国家提交超过 30 份),其中中国共提交 817 篇,接收 155 篇,接受率为19%。
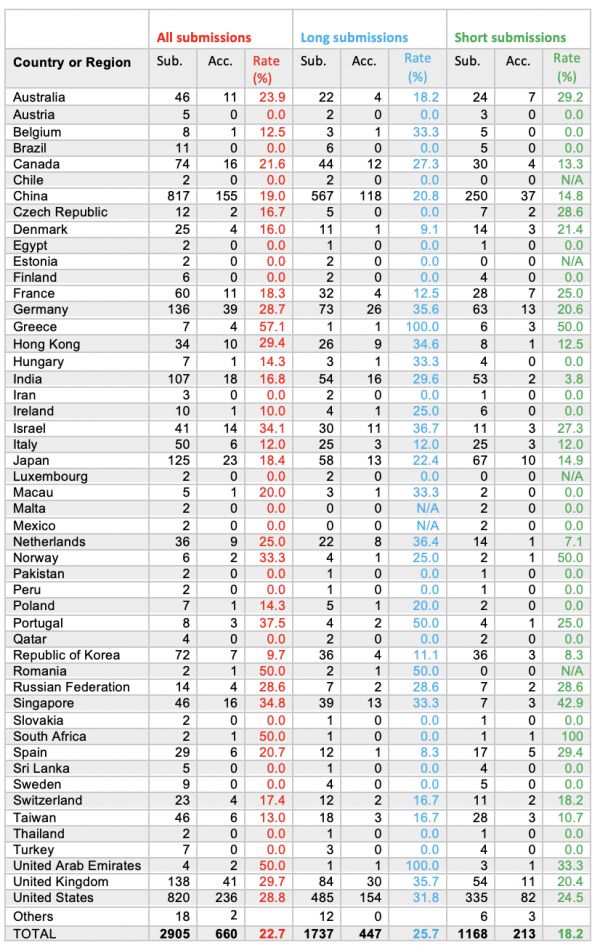
虽然大会接收到的论文投稿增加一倍,但是接收率却创下了三年最低。
2018 年,
ACL 论文
总接收率为 24.9%,2017 年这一数字为 23.3%,而到
2019 年,ACL 论文的总接受率为 22.7%,其中长论文接受率为 25.7%,短论文接受率为 18.2%。
这可能与今年更严格的论文评审制度有关。
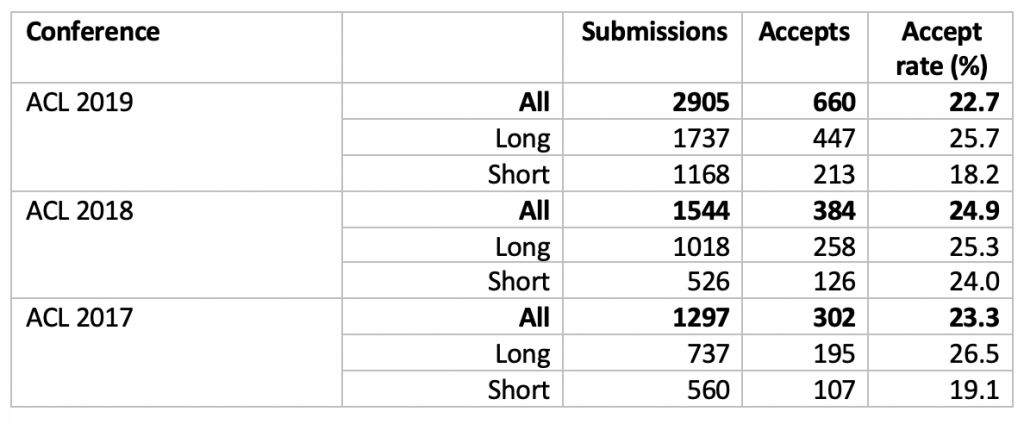
其中,
论文接收率最高的国家和地区分别为新加坡(34.8%),以色列(34.1%),英国(29.7) %),中国香港(29.4%)美国(28.8%)和德国(28.7%)。
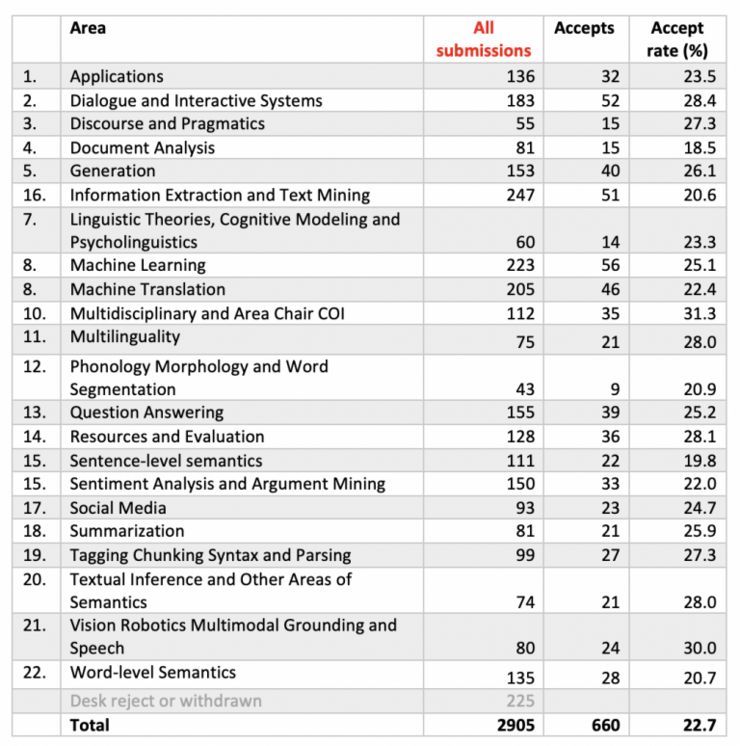
另外,根据组委会公布的数据显示,今年 ACL 不同领域论文的接受率略有区别,其中接收率最低的领域是文档分析(18.5%)、句子级别语义( 19.8%)、信息抽取和文本挖掘(20.6%) 、词级别语义(20.7%) 、音韵学,形态学和单词分割的接收率稍高,为 20.9%。
相比之下,接受率最高的领域是多学科和领域主席 COI(31.3%)。这部分领域包含了资深领域主席审查的与他们自己领域相关的论文。其他接收率相对较高的领域还包括视觉、机器人、多模态语音(30.0%),对话和交互系统(28.4%)和资源与评测(28.1%)。
随着论文投稿数量增长,为了保证审稿的质量,ACL 从 2018 年开始审稿机制也随之发生变化,采用资深领域主席(Senior AC)+领域主席(AC)的双层审评审结构,审稿人的数量也从 1610 人增加到了 2281 人,领域主席(Area Chair)的数量从 61 人增加到了 230 人。
据 ACL 2019 组委会介绍,今年的评审阵容由 46 位 SAC,184 位 AC 组成, SAC 为 AC 分配论文和审稿人,并为对应的领域做出一些整体性的推荐,184 位 AC 中的每位则只负责各自领域内的一部分论文,然后组织审稿人们进行讨论、为审稿意见撰写意见(meta-review),并做出论文选择推荐。
此次 8 篇
获奖
论文的 31 位作者中,大约有 10 位是华人作者。而
在此前的 32 篇提名名单中,共
有 14 篇论文的第一作者是华人学者/学生,其中 9 篇是最佳长文奖候选者,占到一半以上,可以说华人撑起了候选名单中的“半边天”,包括(部分):
1、南京理工大
学,夏睿团
队
ID: 2714 (long, oral 2D, M14:50)