
女主宣言
最近女主在项目中使用到ElasticSearch来做索引。但是对ElasticSearch的一些原理还是比较模糊,所以就梳理了一下ElasticSearch的基本原理,分享给大家。
PS:丰富的一线技术、多元化的表现形式,尽在“
HULK一线技术杂谈
”,点关注哦!
我们首先从ElasticSearch的启动过程开始,逐步了解其工作原理。
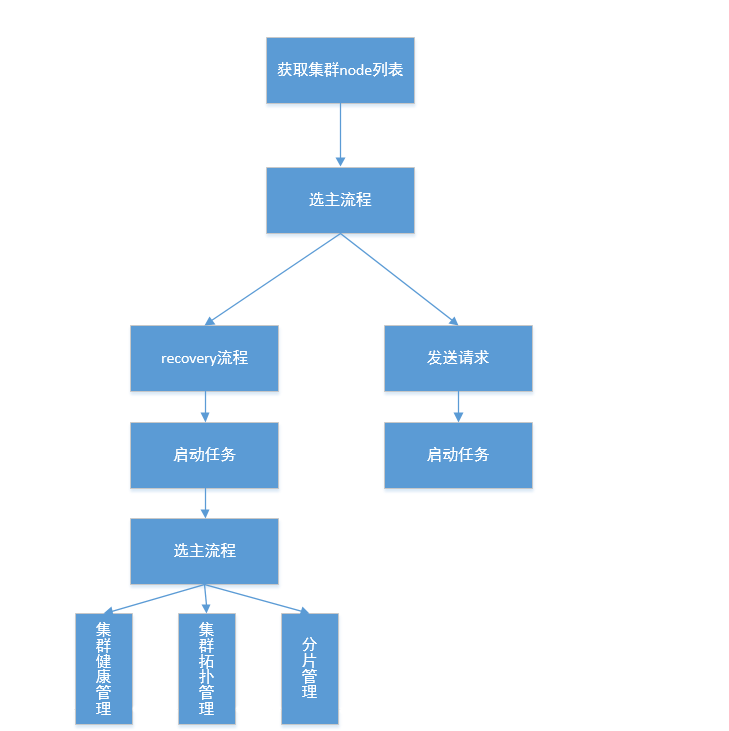
获取集群node列表
在UnicastZenPing构造函数中,向discovery.zen.ping.unicast.hosts配置的节点列表发送请求,获取到DiscoveryNode列表。
选主流程
通过UnicastZenPing发送ping,从response信息中找到master,如果没有master,进入选主流程。
启动任务
选为master节点后,会启动计划任务。
集群管理
集群启动后可以根据API接口进行管理监控。
当ElasticSearch的节点启动后,它会利用多播(multicast)或者单播(如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
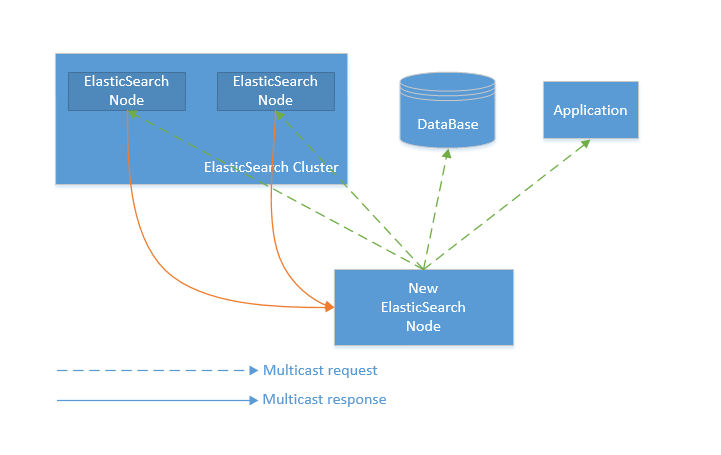
New ElasticSearch Node (新节点)
新节点加入后,会通过多播Multicast request(发出请求),寻找集群其他节点并和集群建立连接。
需要注意的是,从用户的角度来看,主节点在ElasticSearch中并没有占据着重要的地位,这与其它的系统(比如数据库系统)是不同的。实际上用户并不需要知道哪个节点是主节点;所有的操作需求可以分发到任意的节点,ElasticSearch内部会完成这些让用户感到不明觉历的工作。在必要的情况下,任何节点都可以并发地把查询子句分发到其它的节点,然后合并各个节点返回的查询结果。最后返回给用户一个完整的数据集。所有的这些工作都不需要经过主节点转发(节点之间通过P2P的方式通信)。
在正常工作时,主节点会监控所有的节点,查看各个节点是否工作正常。如果在指定的时间里面,节点无法访问,该节点就被视为出故障了,接下来错误处理程序就会启动。集群需要重新均衡——由于该节点出现故障,分配到该节点的索引分片丢失。其它节点上相应的分片就会把工作接管过来。换句话说,对于每个丢失的主分片,新的主分片将从剩余的分片副本(Replica)中选举出来。 以3个Node为例:
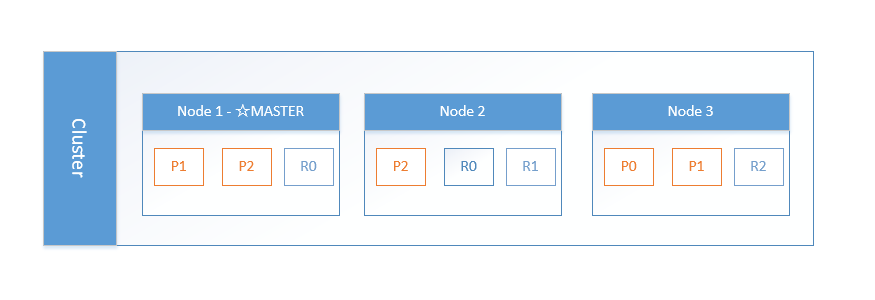
说明:Node1 是master节点,P 为primary 主分片的缩写,R 为replica 副本分片。
当Node1 挂掉的时候,如下:
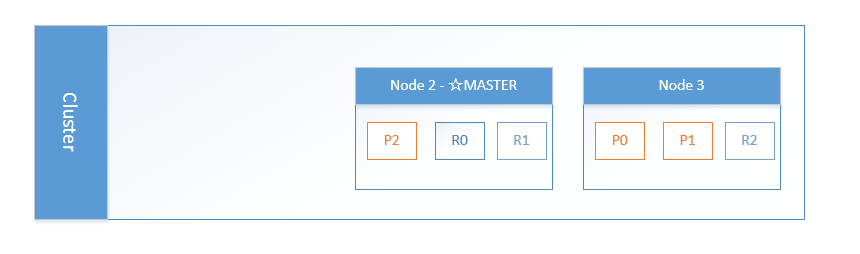
由于一个集群必须要有一个主节点才能使其功能正常,所以集群做的第一件事就是各节点选举了一个新的主节点:Node 2。
主分片1和2在我们杀掉Node 1时已经丢失,我们的索引在丢失主分片时不能正常工作。如果此时我们检查集群健康,我们将看到状态red:不是所有主节点都可用!
幸运的是丢失的两个主分片的完整拷贝存在于其他节点上,所以新主节点做的第一件事是把这些在Node 2和Node 3上的复制分片升级为主分片,这时集群健康回到yellow状态。这个提升是瞬间完成的。
通过管理和监控部分的API,用户可以更改集群的设置。比如调整节点发现机制(discovery mechanism) 或者更改索引的分片策略。用户可以查看集群状态信息,或者每个节点和索引和统计信息。
如:获取集群健康信息 GET /cluster/health 获取集群配置信息 GET /cluster/settings 下图为chrome head插件的集群展示结果:
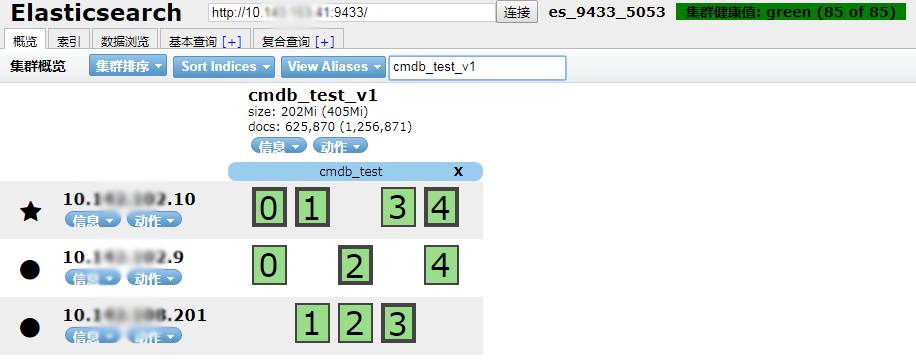
可以看到集群有多少个节点,集群健康值等。
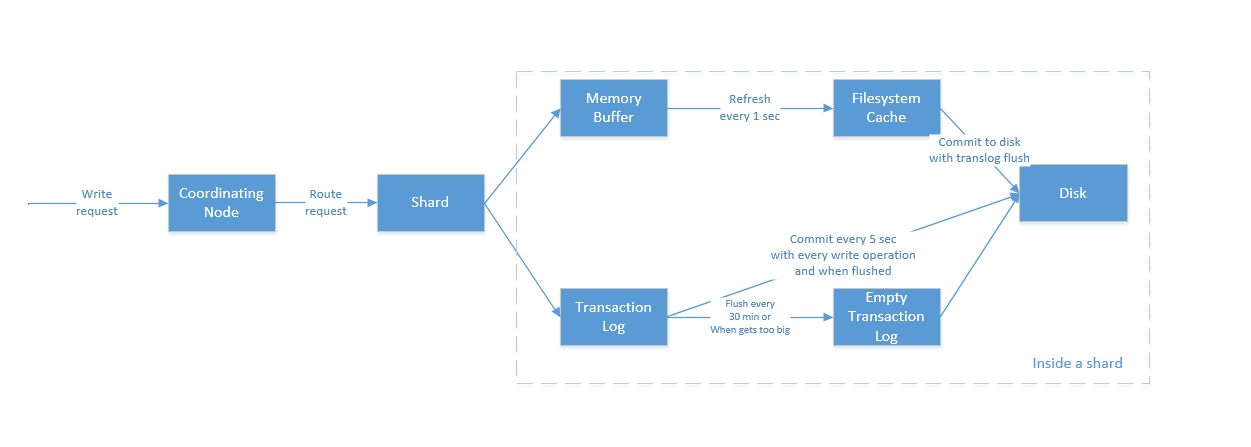
Coordinating Node
协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片。
shard = hash(document_id) % (num_of_primary_shards)
Shard
当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh。
Memory Buffer | Filesystem Cache
当然在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush。
Transaction Log
在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。
flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时。
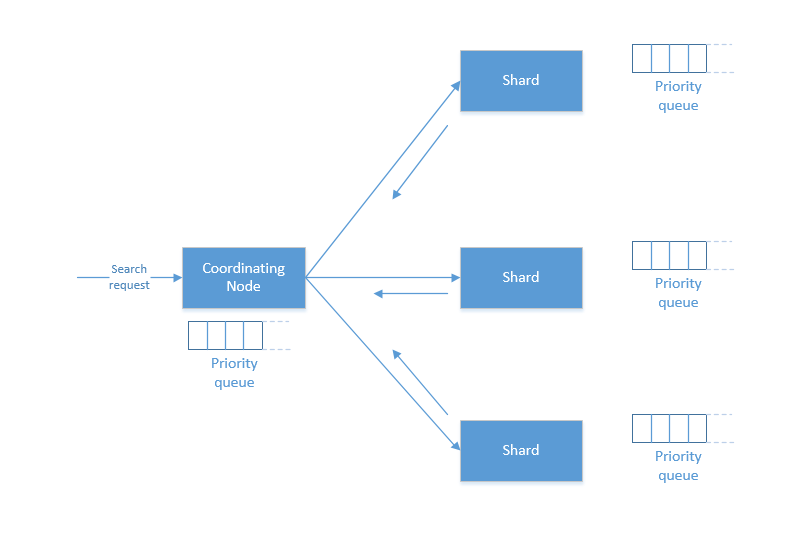
搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
Coordinating Node
在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。










