上次文章中,一张微服务化知识图谱比较模糊,另外是咨询培训流程比较模糊,这里特附上清晰图片,并最后附上知识图谱的详情。
云计算发展至今,从普通的虚拟化到OpenStack再到容器云,解决方案的设计日趋复杂,尤其是容器云和微服务化的解决方案,已经不像传统的解决方案,给客户讲解一下就可以进行招标了,需要和对方技术人员真正地“短兵相接”,了解客户的架构和痛点,以及流程中的问题,并给出建议,才能完成解决方案的工作。
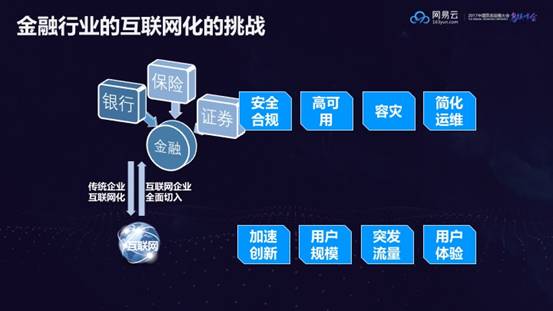
金融行业对安全要求很高,所以传统金融业务对容器云解决方案都是心存疑虑的,但是传统金融行业也在慢慢地互联网化,因为互联网金融企业已经带来了很大的冲击,他们会采取各种策略进行创新性的实验。刘超通过网易云一个真实的金融客户案例,分享了传统金融客户进行创新业务的实践和经验。这个客户有非常强的诉求去尝试创新业务,不但要面临传统金融企业安全、高可用、容灾和简化运维的基本需求,还需要应对互联网化的新挑战,比如系统或应用的快速更新迭代,用户规模的急剧增长,市场活动带来的突发流量,以及互联网对用户体验的极致追求。
比如这个客户的业务之前主要在本省,随着互联网化的发展,希望将业务扩展到更多的地区,但是经过计算发现原来的系统无法支撑未来的业务规划;此外,他们开始举办一些在线秒杀理财产品的活动,突发的流量让他们始料未及。这时微服务架构及相关技术进入了他们的视线,由于缺乏相关技术人才和经验的支持,这个客户开始了和网易云的合作。
网易有很多内部的产品如网易云音乐,云课堂,考拉,严选等都进行过微服务化改造,积累了丰富的经验。在这些内部应用上云的过程中,网易云也积累了丰富的容器化的经验。因而网易云除了提供高性能的容器平台以外,高并发场景下的微服务化和容器化经验,也作为知识体系进行输出。
网易云基础服务架构团队根据多年的实践经验,出版《云原生应用架构实践》一书,详细阐述了云原生应用从初创,到快速成长,到稳定期的架构历程。

网易云解决
方案团队则根据知识体系,结合内部真实案例,输出了如下培训课程与咨询方案。
对于某个特定的客户,网易云有完善的知识输出流程。
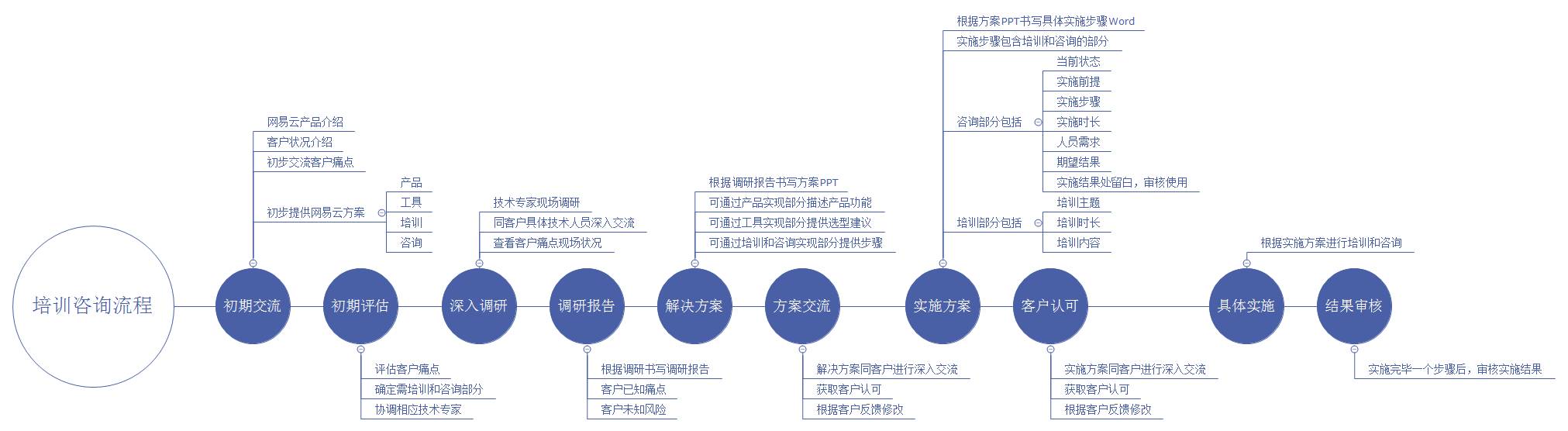
通过和这个客户多次交流,根据客户的实际情况,网易云总结出了针对金融行业的微服务改造方案和规划,在这里分享给大家。
第一步:项目工程化
项目工程化是指整个业务流程和上线流程必须要能够自动化,实现持续集成。如果不能做到这一点,盲目地去拆微服务,是十分危险的。这个客户最初工程化做得不是特别好,仅实现了部分的自动化。
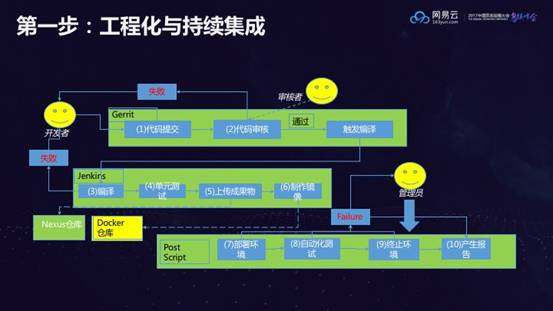
微服务拆分的过程中会进行大规模的代码改动,改动的时候能否遵循代码规范是一个疑问,所以如果没有第二个步骤——代码审核,会使得代码质量失控。另一方面是单元测试的覆盖率太低,而且没有自动化的测试,微服务拆完之后功能还是不是原来的功能,如果没有足够的测试用例,很难证明。要做到自动化,环境部署和自动化部署又会成为一个问题。这个客户目前用脚本实现了自动化部署,在隔离性、端口冲突上都有一些问题。
第二步:框架的选择
目前有两个主流的微服务框架:Spring Cloud和Dubbo。Dubbo诞生较早,所以用的人也更多,而Spring Cloud目前的关注度更高。
刘超认为应该从以下几个角度去考虑技术的选型:
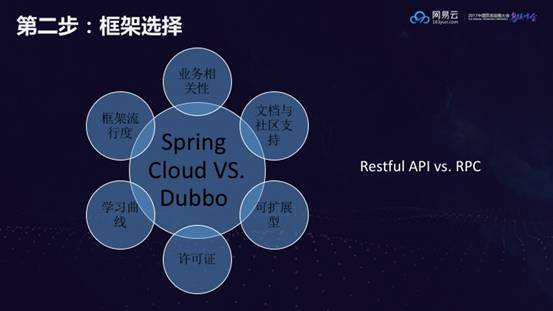
但是这个客户最终还是选择了Dubbo,因为他们的技术负责人对Dubbo很熟悉。刘超也特别强调了这一点:在项目管理中,不论选择哪个开发的框架,都要保证团队中至少有一个人对这个框架很熟,这会大幅度降低风险。
另外,服务间的调用,Spring Cloud采用的是Restful API,Dubbo采用默认的RPC方式。刘超建议用RestfulAPI的方式,因为如果用RPC会存在一个问题:客户端的调用方和被调用方要共享一个Jar包,负责对数据进行封装和解封装。但当微服务拆得非常多的时候,Jar包的维护会变得非常困难,经常出现冲突。而Restful API基于Jason,是一种松耦合的架构方式,相对来说可以比较好的解决Java中Jar包冲突的问题。
第三步:API和UI界面的隔离
可能很多人觉得这是不必要的,实际上更好的设计方式是:
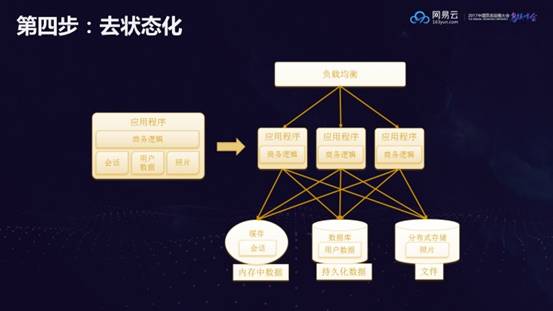
第四步:去状态化
容器化可以解决部署过程中的端口冲突问题,容器化的前提是实现去状态化。刘超拜访了多家金融客户后发现,大部分都已经实现了去状态化,可以直接进行后续的容器化。
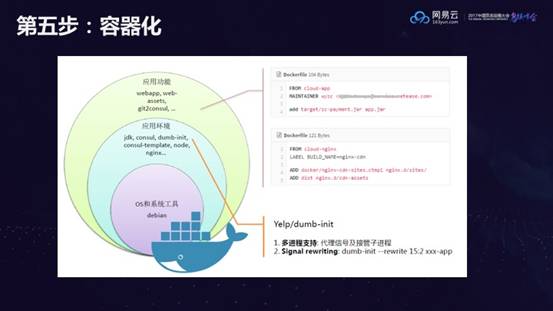
第五步:容器化
容器有一个好处就是镜像可以分层,如果团队也按照分层来进行分工的话,可以提高整个团队的效率。比如,核心人员可以做偏向内核的镜像开发,外层人员基于内层做好的镜像,把Jar放进去就好了。这时只需要核心人员掌握容器的核心技术即可,降低了学习成本。
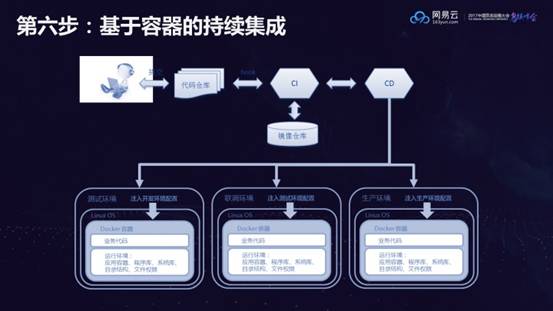
第六步:基于容器的持续集成
这个阶段暂时并不需要一个容器的管理平台,原来是用脚本来部署应用,现在用容器编排的方式来部署,原来在一台机器上启动20个进程,所有端口都是冲突的;现在启动20个容器所有端口都不冲突,每个Tomcat都可以用8080端口,可以相互调用,就可以进行自动化的测试,整个运维也会非常简单。并且容器使得整个开发、测试和生产的环境是一致的。
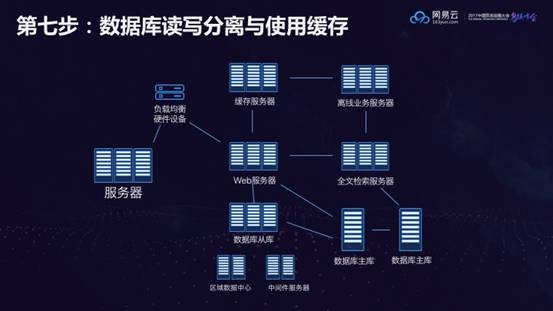
第七步:数据库读写分离与使用缓存
数据库永远是应用最关键的一环,数据库必须要高可用,同时越到高并发阶段,数据库往往成为瓶颈,如果数据库表和索引不在一开始就进行良好的设计,则后期数据库横向扩展,分库分表都会遇到困难。数据库往往写少读多,所以性能优化的第一步就是读写分离。
在高并发场景下,需要通过缓存来减少数据库的压力,使得大量的访问进来能够命中缓存,只有少量的需要到数据库层。由于缓存基于内存,可支持的并发量远远大于基于硬盘的数据库。所以对于高并发设计,缓存的设计时必不可少的一环。
第八步:APIGateway
在拆分之前,建议使用APIGateway,如果有了服务网关,后面的服务不论怎么拆分与合并,对于客户端来讲都是透明的,方便后续的服务拆分。

第九步:服务拆分与服务发现
-
开发独立: 代码耦合度比较高,修改代码通常会对多个模块产生影响,操控难度大,风险高;
-
上线独立: 单次上线需求列表多,上线时间长,影响面大;
-
简化扩容: 由于业务多,每一次扩容需要增加的配置比较杂。一些不起眼的小业务虽然不是扩容的主要目的,也需要慎重考虑;
-
容灾降级:核心业务与非核心业务耦合,在关键时候互相影响。
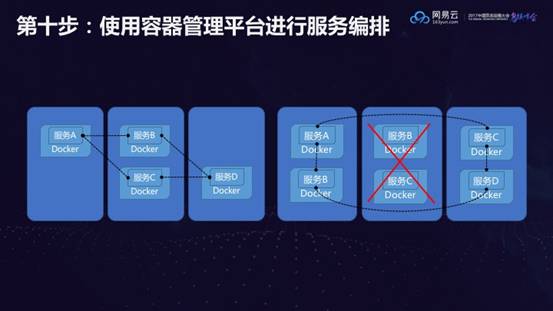
第十步:使用容器管理平台实现服务编排
例如一个应用包含四个服务A,B,C,D,她们相互引用,相互依赖,如果使用了kubernetes,则服务之间的服务发现就可以通过服务名进行了。例如A服务调用B服务,不需要知道B服务的IP地址,只需要在配置文件里面写入B服务服务名就可以了。如果中间的节点宕机了,kubernetes会自动将上面的服务在另外的机器上启动起来。容器启动之后,容器的IP地址就变了,但是不用担心,kubernetes会自动将服务名B和新的IP地址映射好,A服务并无感知。这个过程叫做自修复和自发现。如果服务B遭遇了性能瓶颈,三个B服务才能支撑一个A服务,也不需要特殊配置,只需要将服务B的数量设置为3,A还是只需要访问服务B,kubernetes会自动选择其中一个进行访问,这个过程称为弹性扩展和负载均衡。
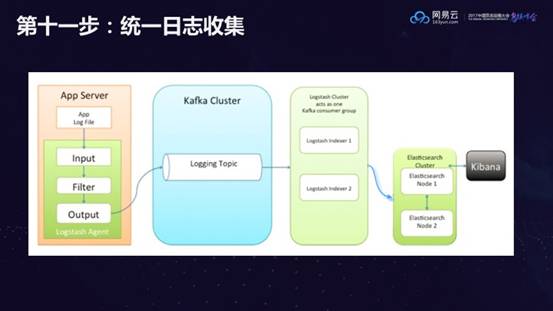
第十一步:统一日志收集
当单体应用拆分为多个微服务之后,不能再单独查看每个服务的日志,因为工作量太大。必须将日志汇集到统一的日志中心进行统一的管理,查询,排错,视图等。
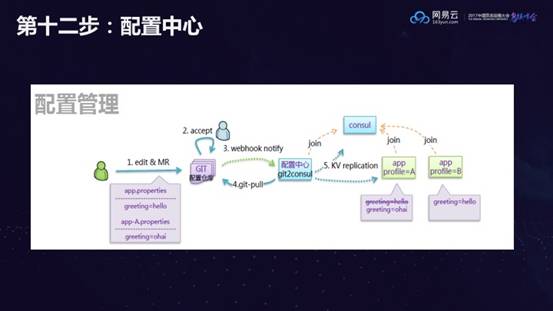
第十二步:配置中心
应用多了就希望实现配置的集中下发,将配置放到统一的consul中,配置只要在代码中提交了,就可以自动下发。
第十三步:水平扩展

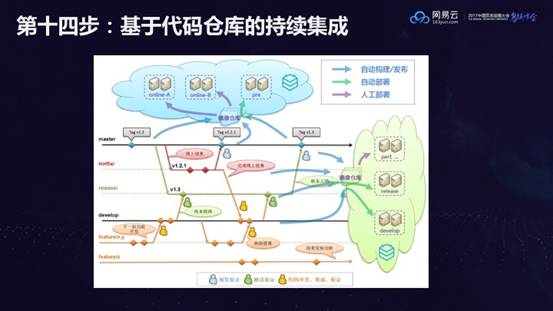
第十四步:基于代码仓库的持续集成
线上的每一个环境都应该对应代码中的一个分支,不提倡也不允许用户在环境中进行手动修改,容易忘也不容易交接,所有操作都应该放在代码中做,通过提交代码,代码做自动发布,自动部署,使得新的配置或新的权限都能发布到新的环境。
第十五步:部署依赖与发布依赖
当单体应用拆分为多个微服务之后,服务的部署,更新,升级,回滚变的非常复杂。网易给出的方案是将编排文件保存在Git里面,在编排文件中维护不同服务之间的部署依赖和发布依赖,例如一次性发布100个应用其中的5个应用,可以通过在修改Git中编排文件中的5个服务进行,并在发现异常的时候,可通过Git回滚一个提交的方式,将5个应用一次性回滚。

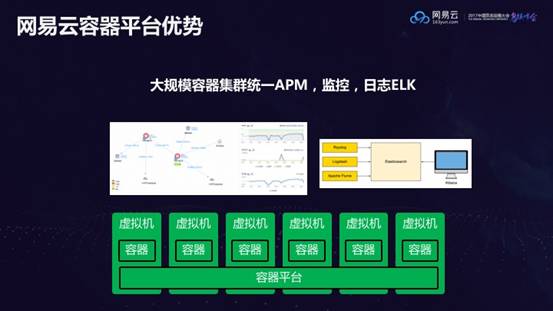
最后,刘超介绍了网易云容器平台的优势:
1.
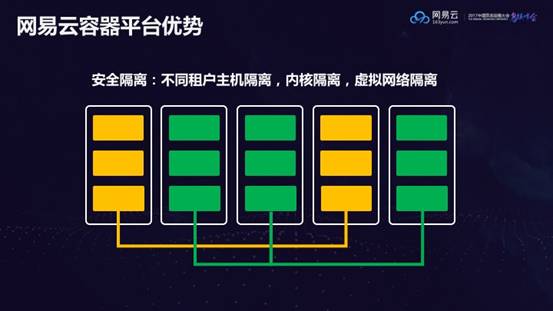
安全隔离:不同租户主机隔离,内核隔离,虚拟网络隔离
2.
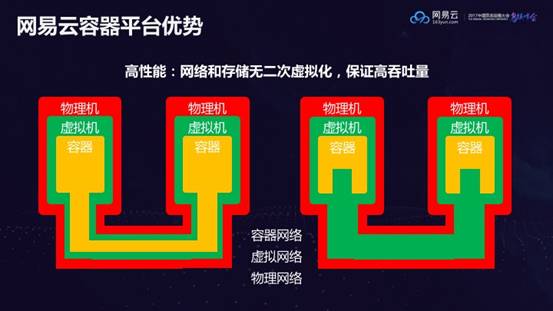
高性能:网络和存储无二次虚拟化,保证高吞吐量
3.
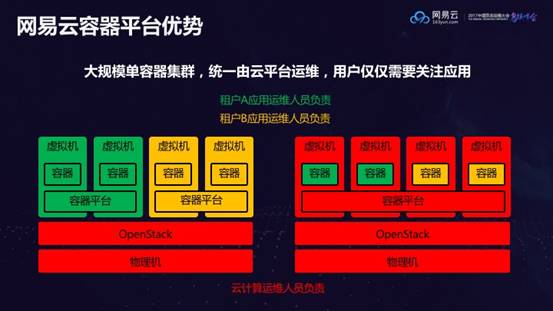
大规模单容器集群,统一由云平台运维,用户仅仅需要关注应用
4.
大规模容器集群统一APM,监控,日志ELK
最后是培训与咨询课程详情
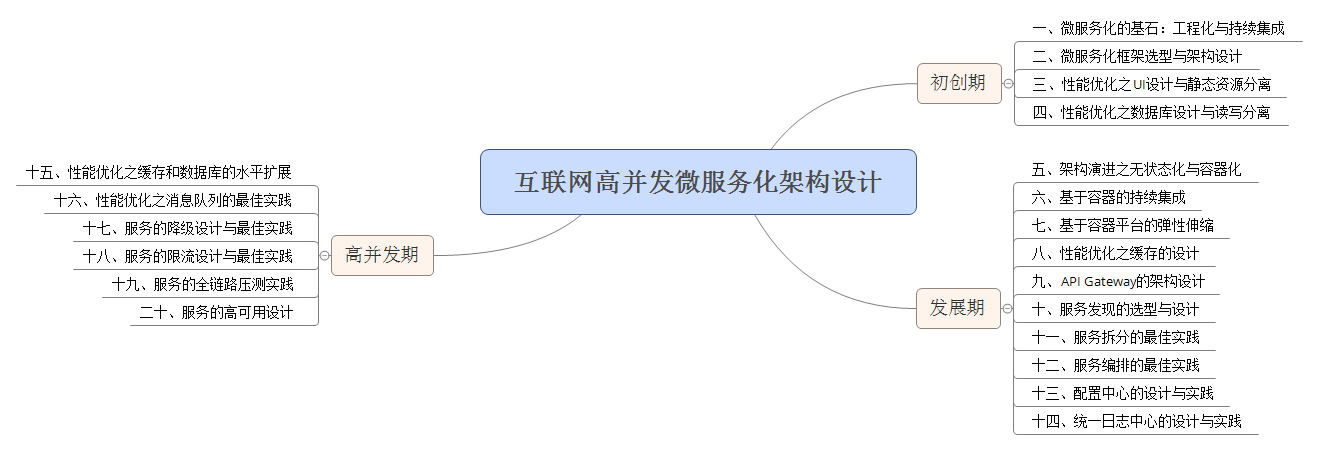
互联网高并发微服务化架构设计
初创期
一、
微服务化的基石:工程化与持续集成
1.1
课程背景
微服务的优势在于管理变更,微服务化在于将经常需要变和遭遇性能瓶颈的部分剥离出来。然而变更意味着风险,如何保证变更后的代码质量,如何保证变更后功能保持不变,如何保证变更后不引入新的
Bug
,是微服务化是否成功的基本问题。不进行工程化和持续集成的微服务化,就像建立地基不稳的高楼,会使得整个工程时刻面临崩溃的风险。
1.2
课程内容
本课程包括
SOLID
设计原则,
Cloud Native
设计原则,代码分层,依赖管理,代码规范与代码审核,代码版本与分支管理,单元测试,配置文件管理,接口文档管理,数据库版本管理,组织与企业文化,敏捷开发流程,自动编译,自动测试,自动部署等方面的理论知识,并通过一个真实的案例展现在网易的实践。
二、
微服务化框架选型与架构设计
2.1
课程背景
项目初期的选型非常重要,初期的良好选型,是此后团队是否能够快速迭代,是否能够快速微服务化,是否能够进行性能优化的决定性因素。初期的技术选型重要性大于后期的重构。真实案例中也存在为了做微服务化,需要重构代码,重新选型的情况。
2.2
课程内容
本课程包括选型所需考虑哪些因素,
Java
框架的选择,数据库框架的选择,
UI
框架的选择,数据库的选择,缓存的选择,非结构化数据存储的选择,大数据平台的选择等,以及基于这些框架的选择进行初期的架构设计的最佳实践。
三、
性能优化之
UI
设计与静态资源分离
3.1
课程背景
很多应用在初创期的时候,并不考虑动态资源和静态资源的分离,然而当访问量大了之后,会出现加载速度慢,带宽占用高,流量消耗大的缺点。因而性能优化的第一步工作应该讲动态和静态资源分离,分离的越早,以后越轻松。
3.2
课程内容
本课程包括哪些资源属于静态资源,哪些资源属于动态资源,哪些资源可以动态资源静态化,如何使用对象存储技术,如何使用
CDN
技术,如何基于对象存储和
CDN
进行静态资源的下发等。并通过一个真实的例子阐述静态资源分离的最佳实践。
四、
性能优化之数据库设计与读写分离
4.1
课程背景
数据库永远是应用最关键的一环,数据库必须要高可用,同时越到高并发阶段,数据库往往成为瓶颈,如果数据库表和索引不在一开始就进行良好的设计,则后期数据库横向扩展,分库分表都会遇到困难。数据库往往写少读多,所以性能优化的第一步就是读写分离。
4.2
课程内容
本课程包括如何进行数据库表结构的设计,如何进行数据库索引的设计,如何保证数据库将来可以横向扩展和分库分表,数据库复制技术,如何检测慢
SQL
语句及优化,如何实现数据库的读写分离等。并通过一个真实实例阐述数据库设计的最佳实践。
发展期
五、
架构演进之无状态化与容器化
5.1
课程背景
容器和微服务是双胞胎,因为微服务会将单体应用拆分成很多小的应用,因而运维和持续集成会工作量变大,而容器技术能很好的解决这个问题。然而在微服务化之前,建议先进行容器化,在容器化之前,建议先无状态化,当整个流程容器化了,以后的微服务拆分才会水到渠成。
5.2
课程内容
本课程包括如何通过剥离
Session
数据,缓存数据,文件数据,结构化数据实现无状态化。并在无状态化后进行容器化,包括
Dockerfile
的书写,镜像的分层与管理,
Entrypoint
和
CMD
,端口,环境变量,
hosts
文件,时区,字符编码,
volume
等所可能遇到的坑及最佳实践。
六、
基于容器的持续集成
6.1
课程背景
在第一节课,在不使用容器的情况下,持续集成流程就应该运行起来,在容器化之后,应该在持续集成流程中加入容器,这样能够使得环境在开发,测试,生产的一致性,极大的提高迭代效率,实现
DevOps
6.2
课程内容
本课程包括在原来持续集成的基础上,融入容器。包括规划容器镜像版本号,
CI
增加容器化打包镜像,自动化创建测试环境,自动化销毁测试环境,
CD
增加容器滚动升级,容器回滚等,以及保证开发,测试,生产环境的代码一致性和数据库,缓存等配置差异性的最佳实践。
七、
基于容器平台的弹性伸缩
7.1
课程背景
当应用容器化之后,不应该再手动的进行容器部署,而是应该通过容器平台将应用管理起来,则容器的调度,自修复,自发现,弹性伸缩,网络的配置,存储的配置等全部交给容器平台,简化容器的运维。
7.2
课程内容
本课程包括容器平台的选型,
Kubernetes
的基本概念
(Pod
,
Service, Deployment
,
Namespace
等
)
,
Kubernetes
的主要组件
(API Server
,
Scheduler
,
Kubelet
,
Kube-proxy
等
)
,
Kubernetes
的网络,
Kubernetes
的存储,
Kubernetes
的监控,以及如何通过
Kubernetes
部署无状态应用和有状态应用,以及基于网易基础服务部署容器,并进行弹性伸缩的最佳实践。
八、
性能优化之缓存的设计
8.1
课程背景
在高并发场景下,需要通过缓存来减少数据库的压力,使得大量的访问进来能够命中缓存,只有少量的需要到数据库层。由于缓存基于内存,可支持的并发量远远大于基于硬盘的数据库。所以对于高并发设计,缓存的设计时必不可少的一环。
8.2
课程内容
本课程包括缓存的选型,多级缓存的使用,分布式缓存的使用,缓存的一致性问题,缓存的并发问题,如何提高缓存命中率,如何处理缓存穿透等高并发场景下的缓存架构设计,并通过一个真实的案例解析缓存使用的最佳实践。
九、
API Gateway
的架构设计
9.1
课程背景
当原来的单体应用不能够支撑高并发访问的时候,需要进行服务的拆分,然而在服务拆分之前,最好前端加上
API Gateway
这一层,这样可以使得后端无论如何拆分和合并,服务之间的
API
怎么变,都能够暴露统一的接口对外服务,减少前端的感知。
9.2
课程内容
本课程包括
API Gateway
的设计,例如
API
如何聚合,身份如何认证,如何加密,如何路由,如何区分内外
API
,如何处理配置的自动更新,如何处理调用失败,如何处理超时,如何水平扩展等问题。并通过一个真实案例解析
API Gateway
的最佳实践。
十、
服务发现的选型与设计
10.1
课程背景
在服务拆分之前,需要确定服务发现的选型,不同的服务发现方法有不同的服务拆分及服务编排的策略,不同的服务发现方法也各有优缺点,一旦确定了,后期很难改变,需要事先通过业务场景了解各自的优势劣势,并选择最为试用的选型。
10.2
课程内容
本课程包括服务发现的各种方法及优缺点,例如
DNS
,
DNS+VIP
,客户端服务发现,服务端服务发现,
Dubbo
,
SpringCloud + Eureka
,
SpringCloud + consul
等,并结合具体的实例解析每种方式下如何实现服务监控,负载均衡,容错功能等,以及网易在不同的产品线选择不同的服务发现方式的最佳实践。
十一、服务拆分的最佳实践
11.1
课程背景
当单体应用不能满足快速变更和高并发请求的时候,可以开始进行服务拆分。服务拆分是个细活,先拆哪个,后拆哪个,如何拆分,如何平滑过渡,这些都没有一定的规则可循,但是网易有拆分了大量高并发业务时的经验可以分享。
11.2
课程内容
本课程包括服务拆分的时机,服务的边界划分,调用约定,接口更新,依赖管理,切换和引流,服务拆分后是否分层,拆分后命名约定,分层调用规则,调用的全链路管理,数据库是否拆分,如何拆分,如何处理分布式事务等,以及通过一个具体的实例解析网易在服务拆分的最佳实践。
十二、服务编排的最佳实践
12.1
课程背景
当单体应用拆分为多个微服务之后,服务的部署,更新,升级,回滚变的非常复杂。需要有一套资源及服务编排系统,通过可编程基础设施,控制服务的整个生命周期及相互之间的关系。
12.2
课程内容
本课程包括如何通过容器编排系统控制容器内应用的生命周期,如何管理容器内应用的相互关系,如何通过资源编排系统控制云主机,数据库,缓存等
PaaS
服务的生命周期,如何管理容器内应用和
PaaS
服务的相互关系,如果使用编排文件,如何对编排文件进行版本化管理,如何一次性发布
100
个应用其中的
5
个应用,并在发现异常的时候,将
5
个应用一次性回滚等方面的设计与最佳实践。
十三、配置中心的设计与实践
13.1
课程背景
当单体应用拆分为多个微服务之后,对于大量微服务的统一的配置成为挑战,不再可能单独管理每个微服务的配置,很难保证如此大量的配置情况下的正确性和稳定性,需要将配置放在一个统一的地方,统一修改,统一下发。
13.2
课程内容
本课程包括配置的分类
(
环境变量,参数,
properties
文件,
xml
文件,
KV
存储
)
及管理,配置的下发方法
(disconf, kubernetes
的
configMap
,
Springcloud
的
config server)
,以及配置中心本身的高可用性设计。并以一个真实的案例解析网易在配置中心的最佳实践。
十四、统一日志中心的设计与实践
14.1
课程背景
当单体应用拆分为多个微服务之后,不能再单独查看每个服务的日志,因为工作量太大。必须将日志汇集到统一的日志中心进行统一的管理,查询,排错,视图等。
14.2
课程内容
本课程包括如何构建一个
ELK
日志中心,如何保证日志中心的高可用性,如何对日志中心进行性能调优,如何评估日志对性能的影响,如何进行日志的格式设计,如何通过日志中心定位错误,如何进行日志订阅等。并以一个真实的案例解析网易在日志中心的最佳实践。
高并发期
十五、性能优化之缓存和数据库的水平扩展
15.1
课程背景
在高并发场景下,服务可以无状态和横向扩展,瓶颈会在缓存和数据库上,因而缓存和数据库也需要横向扩展,使得缓存和数据库也能不成为瓶颈。
15.2
课程内容
本课程包括缓存的水平扩展技术选型,缓存集群的参数及性能调优,分库分表设计,分布式数据库设计,分布式事务设计,幂等设计,事后补偿设计,
TCC
设计,同城复制,异地容灾设计等。以及通过一个具体的实例解析网易分布式数据库使用的最佳实践。
十六、性能优化之消息队列的最佳实践
16.1
课程背景
在高并发场景下,很多关键的操作需要实时得到结果,因而需要同步调用,然而同步调用会给应用很大的压力,也有一些操作可以通过异步的方式进行,可以将任务放在消息队列中,在后台慢慢去做,不阻塞主要的流程,可以达到削峰的目标。
16.2
课程内容
本课程包括消息队列的选型与优缺点
(ActiveMQ
,
RabbitMQ
,
Kafka)
,消息队列的高可用性,如何保证消息的可靠性,消息队列的性能调优,服务的异步化设计,状态机设计,基于事件的设计等。通过一个具体的实例解析网易基于消息队列的异步服务设计实践。
十七、服务的降级设计与最佳实践
17.1
课程背景
在高并发场景下,当请求太多服务响应不过来的时候,需要通过服务降级,牺牲部分次要功能来保证主要功能的稳定性和可用性。
17.2
课程内容
本课程包括客户端服务降级,服务端服务降级,区分强依赖和弱依赖,区分关键业务和非关键业务,数据延迟持久化,展现非实时数据等。通过一个具体的实例解析网易服务降级的设计与最佳实践。
十八、服务的限流设计与最佳实践
18.1
课程背景
在高并发场景下,当请求太多服务响应不过来的时候,需要通过限流的方式,来保护应用不被大量访问压垮,保证重要的请求被正确响应。
18.2
课程内容
本课程包括客户端限流,服务端限流,限制并发数,限制连接数,限制请求数,限制某个时间窗口的请求数,令牌桶,漏桶等主流的限流方法以及限流的实现方法及触发时机。通过一个具体的案例解析网易在服务限流的最佳实践。
十九、服务的全链路压测实践
19.1
课程背景
高并发场景下,必须要对应用进行压力测试,并且根据压力测试的结果,评估系统的承受能力,并在大促的时候,做到心中有数,提前进行资源准备,保证系统顺利通过大促。
19.2
课程内容
本课程包括线下性能测试,线下性能测试工具,性能基线的形成,基于性能测试进行容量规划,引流型线上性能测试,分布式测试源,全链路性能测试,
APM
系统,异常监控,阈值监控等。并通过一个具体的案例解析性能压测和
APM
的设计及最佳实践。
二十、服务的高可用设计
20.1
课程背景
微服务架构需要保持高并发场景下服务的高可用,包括服务之间的高可用,同机房的高可用,同城的高可用,异地的灾备等,需要考虑各种场景下服务的永远在线。
20.2
课程内容
本课程包括服务调用超时处理,断路器,隔离,幂等,容错,全局负载均衡,本地负载均衡,虚拟
IP
地址,应用层高可用,应用层同城双活,数据库高可用,数据库层同城双活,异地灾备等。并通过一个具体的案例解析网易同城双活异地灾备的最佳实践。





