排序可能是日常数据清洗过程中比较高频的应用了,今天这一篇给大家介绍R语言和Python中最为常见的排序函数应用。
R语言:
排序根据对向量排序和数据框的排序要使用不同的函数,以上四个函数中,前三个是针对向量的,最后一个是针对数据框的。
sort
x
sort(x,decreasing=F) #默认是生序排列,其中decreasing参数默认为FALSE。
sort(x,decreasing=T) #降序排列
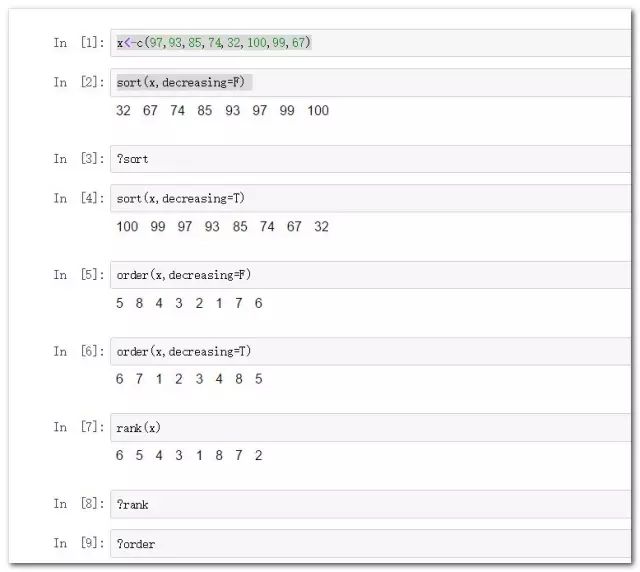
order
order(x,decreasing=F) #变量由小到大在原始数据中的位次(默认升序可无需逻辑参数)
order(x,decreasing=T) #按照由大到小的顺序对应元素在原始向量中的微词。
rank:
#rank函数返回向量的秩,即对应元素在原始向量中排名。
rank(x)
基于
数据框自身的排序:
当针对数据框进行排序时,如同对数据框进行条件索引一样,也可以基于数据框自身的方法来实现。
(mydata
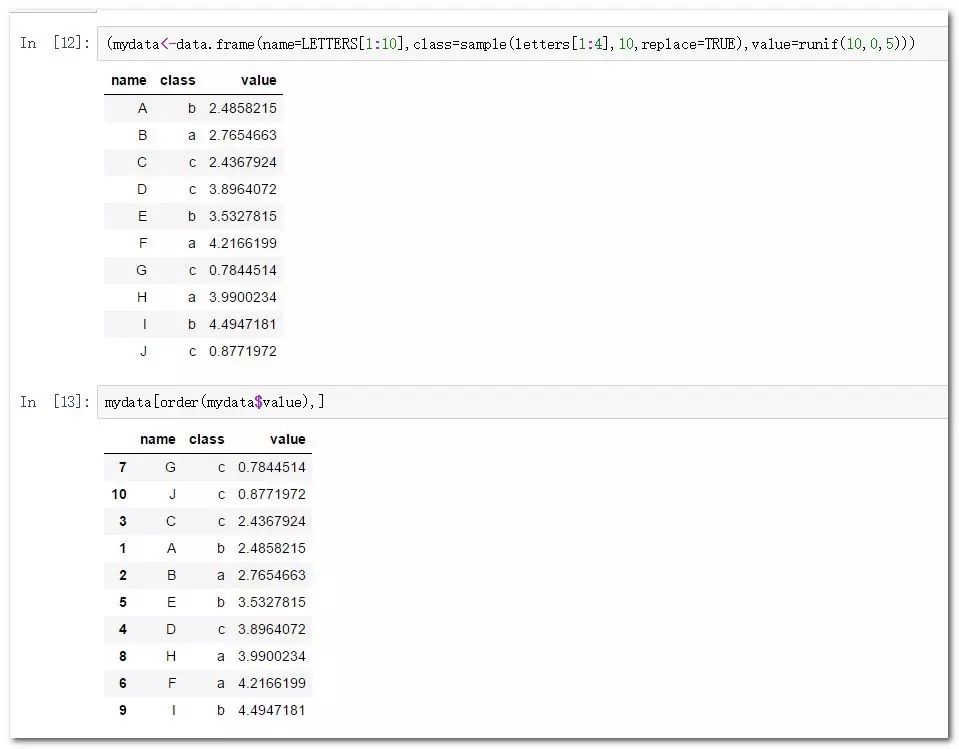
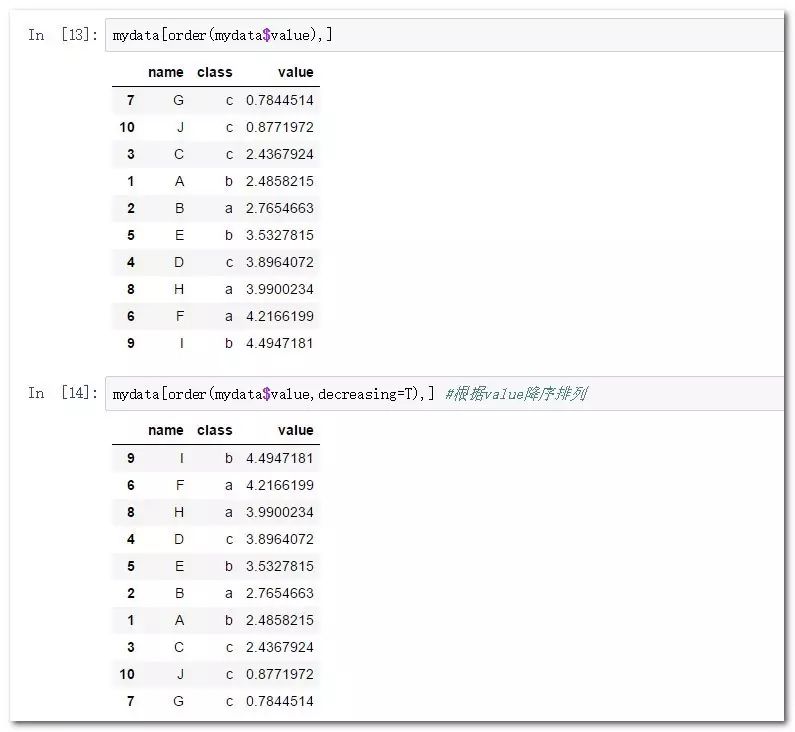
mydata[order(mydata$value),] #默认生序排列
mydata[order(mydata$value,decreasing=T),] #根据value降序排列
以上这种方式通过基于数据框自身的规则,完成了排序工作(实际上是一种布尔索引),但是不够优雅,写了繁琐的变量名,而且只能根据一个字段来排序。
数据框排序-arrange
arrange函数的存在实在是R语言排序大杀器。
library(dplyr)
mydata%>%plyr::arrange(class,value)
mydata%>%plyr::arrange(class,-value)
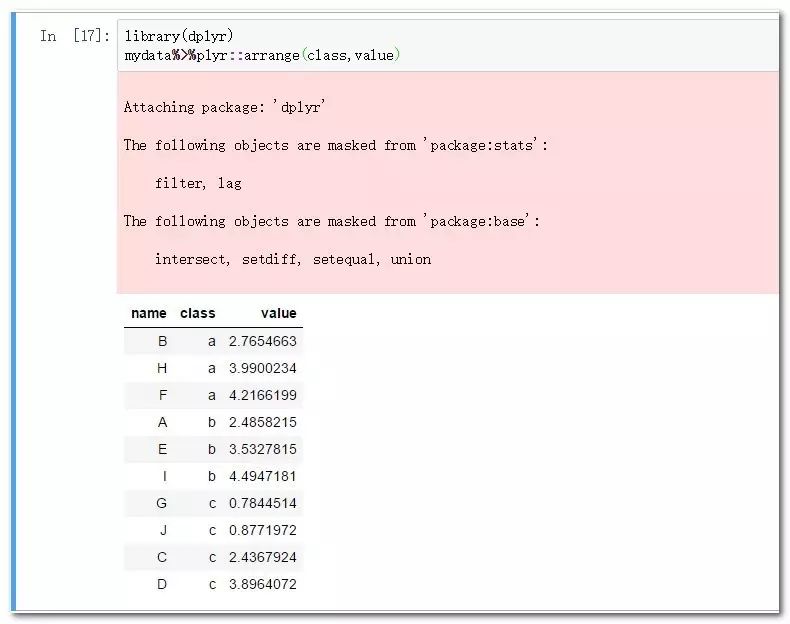
arrange函数不仅可以实现多变量规则排序,而且可以仅以负号指定降序,语法简洁,功能强大,其中多变量时,一般是分类变量在前,连续变量在后,粒度粗的维度排在最前面,分类变量排序粒度依次递减。最后是连续变量。
-------------
Python:
-------------
-
sort
-
sorted
-
.sort_index
-
.sort_value
列表排序方法:
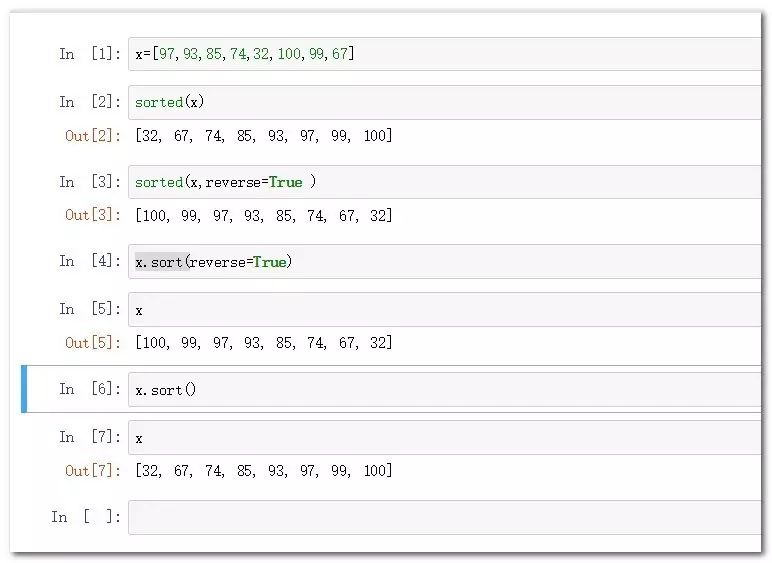
x=[97,93,85,74,32,100,99,67]
针对list的排序,Python提供有全局的sorted函数以及list自身的sort函数可以完成排序功能。
sorted(x) #默认生序
sorted(x,reverse=True) #指定降序
x.sort() #默认生序
x.sort(reverse=True) #指定降序
字典排序方法:
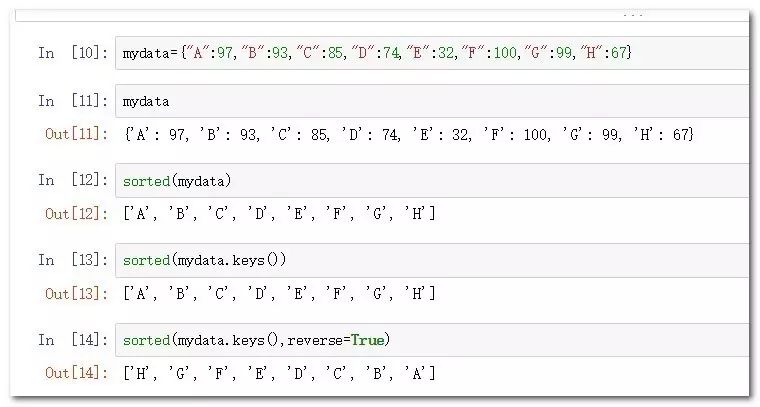
mydata={"A":97,"B":93,"C":85,"D":74,"E":32,"F":100,"G":99,"H":67}
sorted(mydata.keys()) #根据字典的键排序
sorted(mydata.keys(),reverse=True) #根据字典的键逆排序
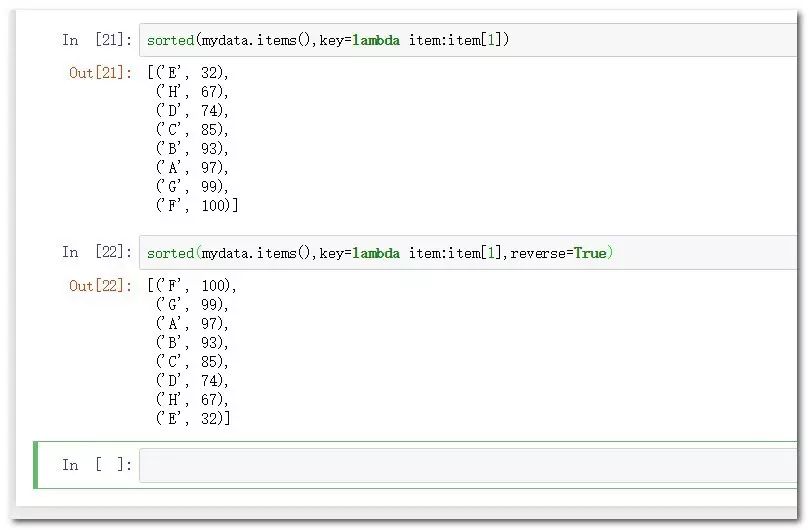
排序时按照键值对:
sorted(mydata.items(),key=lambda item:item[1]) #根据值字段生序排列
sorted(mydata.items(),key=lambda item:item[1],reverse=True) #根据值字段逆序排列
数据框排序:
import pandas as pd
import numpy as np
df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y'],
"m-point":[10,12,20,40,40,40,30,20]})
pandas所生成的数据框同样有sort方法。
根据值排序:
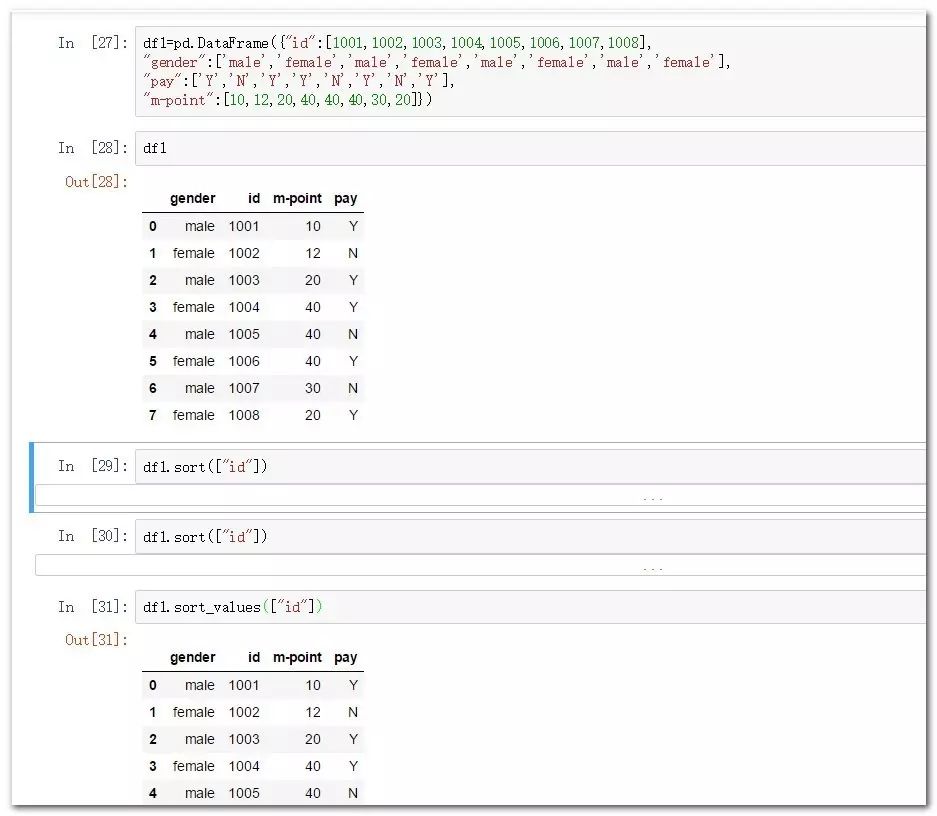
df1.sort_values(["id"]) #使用值进行排序
df1.sort_values(["id"],ascending=False) #降序排列
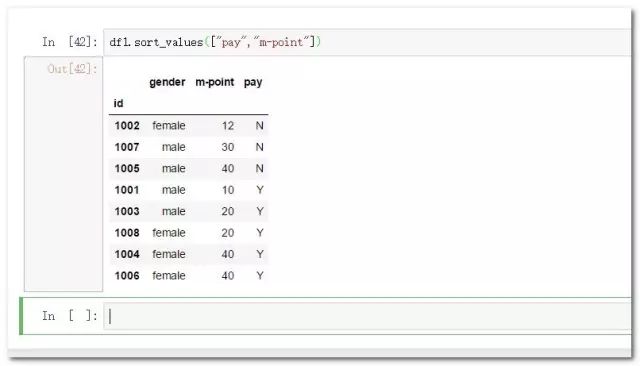
df1.sort_values(["pay","m-point"]) #排序多个字段
索引排序:
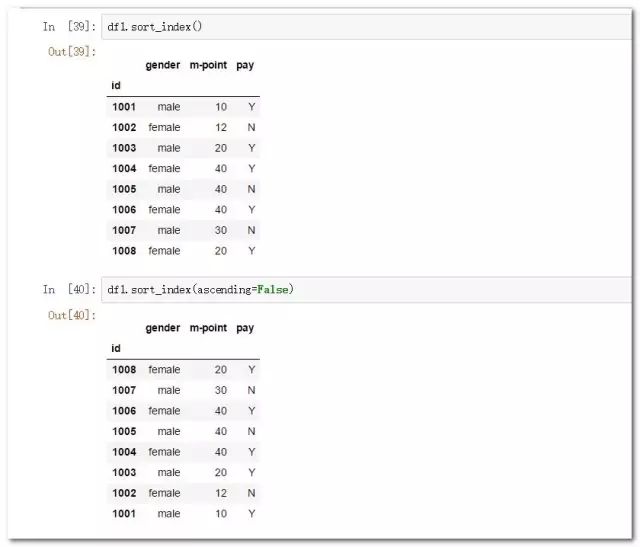
df1=df1.set_index('id') #设置索引列
df1.sort_index() #使用索引进行排序
df1.sort_index(ascending=False) #使用索引列降序排列
--------------
本节小结:
-----------
排序函数:
R语言:
向量:
数据框:
Python:
列表与字典:
数据框:

左手用R右手Python系列(I): 字符串格式化输出
左手用R右手Python系列(II): 数据合并与追加
左手用R右手Python系列(III): 数据塑型与长宽转换
左手用R右手Python系列(IV): 因子变量与分类重编码
左手用R右手Python系列(V): 数据切片与索引
左手用R右手Python系列(VI): 变量计算与数据聚合
如需转载请联系EasyCharts团队!
微信后台回复“转载”即可!
【书籍推荐】
《Excel 数据之美--科学图表与商业图表的绘制》
【手册获取】
国内首款-数据可视化参考手册:专业绘图必备
【必备插件】
EasyCharts --
Excel图表插件
【网易云课堂】
Excel 商业图表修炼秘笈之基础篇







