
7月9日,虽然已是中国计算机学会(CCF)主办,雷锋网和香港中文大学(深圳)承办的第二届CCF-GAIR全球人工智能与机器人峰会的最后一天,但仍然不影响各位童鞋到场学习的激情。机器人专场不仅满座,连走道上都挤满了小伙伴。继Facebook田渊栋结束其演讲之后,阿里妈妈精准展示广告技术总监盖坤作为第二场主题演讲嘉宾,也上台为大家分享了在过去5、6年间阿里巴巴基于互联网大数据做的机器学习模型方面的一些探索,以及一些研究成果背后的思考。
盖坤这次给大家带来的演讲主题是《互联网大数据下的模型结构挑战》,主要分为以下几个部分:
1、互联网数据和经典模型
2、分片线性模型和学习算法MLR模型
3、大规模ID特征+MLR实践
4、深层用户兴趣分布网络
(因为盖坤讲的非常干货,所以这次AI科技评论将其演讲全文和PPT都贴在了下文,以便未能到场的童鞋也能直观的“听”演讲。对原版 PPT感兴趣的同学请在 AI 科技评论后台回复“ 盖坤模型PPT ”)
以下是盖坤本次主题演讲的原文,
AI科技评论
做了不改变原意的编辑:
盖坤:大家好,非常高兴能来到CCF-GAIR的会场。今天想跟大家分享的是过去5、6年间在阿里做的基于互联网数据的机器学习模型方面的一些探索,还有除了研究结果之外背后的一些思考。

这是我今天主题分享的提纲。我会先介绍一下互联网大数据,因为自身主要做电商互联网的用户行为数据。那么,在这个经典业界处理方式下,阿里都做了哪些改进?其中主要包括提出分片线性机器学习算法,也称MLR。之后,我会讲一下大规模ID特征和MLR算法配合在业务里面的应用实践。最后,我会分享这两年,我们在深度学习网络上的一些进展,介绍下深层用户兴趣分布网络。
一、互联网数据和经典模型

典型问题:CTR预估
机器学习可以让互联网数据发挥出巨大价值,而其在工业界应用最早也最成功的一个案例,就是点击率(CTR)预估。CTR预估在广告、推荐、搜索等都是比较重要的业务,对业务指标和收入指标的影响非常巨大。
以CTR预估为例,在此有三种经典做法:
简单线性模型Logistic Regression
稀疏正则L1-Norm特征筛选
处理非线性:人工特征工程
经典方法一:ID特征
ID特征,这里指的是稀疏鉴别式特征。举个例子,假如有1亿个用户,可以把1亿个用户表示为1亿维的01向量,01向量的第一个用户就命中第一维,第二个用户就命中为第二维,所以一种特征可以用这种ID类表示展现成一个非常长的01稀疏向量。如果有很多组特征,就可以把这些向量拼起来,形成一个更长的向量。
就原始特征而言,一般用户量大的公司可能是上亿级,而大的互联网公司,是上亿、上十亿甚至上百亿级的。所以原始ID特征在表示上,可以轻松将其表示成十几亿或者几十亿级。此外,我们还可以做特征的交叉组合,只要工程能力够,可以轻松上千亿,这个特征维度很大。
经典方法二:逻辑回归
逻辑回归是线性模型加上非线性的变换,变成一个概率形式。逻辑回归在工业界使用的方式很不一样。第一,它能处理非常大规模的数据,所以其模型和数据都必须是并行处理的,这对工程和算法上的要求都特别高。第二,对于特别大的特征来讲,通常我们会用稀疏正则L1-Norm特征筛选的方法。
经典方法三:人工特征工程
如果想用这个经典方法将更多有用的信息尤其是非线性的压榨出来,还需要用到人工特征工程的方法。比如刚才说的两个特征,如果两个特征的交互对目标影响很大,那么拼起来的线性模型可能不够,我们就要做交叉等很多特征。
这些方法是我在5、6年前刚进阿里时看到的一个状态,那时候国内大多数公司基本上都在沿用这套方法做研发。但是这里面有
两个问题
:
1、人工能力有限,很难对非线性模式完全挖掘充分。
2、依赖人力和领域经验,方法推广到其他问题的代价太大,不够智能。
Kernel、Tree based、矩阵分解和分解机器模型和其存在的问题

1、Kernel方法:不适用工业界
Kernel方法是当时学术界使用的一些主流的非线性方法。为什么Kernel方法在工业界不怎么用?因为计算不可行。一般Kernel方法,其矩阵是数据量的平方级。当数据量特别大的时候,工业界只能使用线性级别。
2、Tree based方法:在ID特征上表现不够好
Tree based方法在一些低维的强特征上效果特别好,但在ID特征上反而作用不太好。
这里举一个例子:在推荐场景中,需要预估一个用户和一个宝贝的点击率,先不取历史行为就用用户ID和宝贝ID两种特征。有这两个特征,对于协同过滤的方法就已经够了。但是,如果用Tree based方法,要建树就会带来很多麻烦,树根到树叶的路径等价于是否是某个用户和是否是某个宝贝的联合判断。在这种情况下,它已经变成了一个历史记忆。这就是为什么Tree based的方法在稀疏大规模ID数据上表现不行的原因。
Facebook也做了一个方法,就是在强特征上用Tree based方法做数据筛选,再用一些LR聚合类的方法利用弱特征。
3、矩阵分解和分解机器模型:无法处理高阶关系
矩阵分解和分解机器模型,这两类模型其实有点共通。以分解机器模型为例,它主要处理的是有限次关系,经典的方法是二次关系。对于一些高阶关系是没法处理的。
二、分片线性模型和学习算法MLR模型
分片线性模型:优点、使用模型形式和其他
1、优点:可在大规模数据中挖掘推广性好的非线性模式
分片线性模型MLR是2011年我在阿里提出的方法。该模型的优点在于,可将整个数据分成不同的区域,在每个不同区域都用一个简单的模型预测,再将全部信息聚合起来,得到可以比较复杂的分片线性模型。如此一来,就能平衡欠拟合和过拟合的问题,从而在大规模数据中挖掘出推广性好的非线性信息。而其一个基本原则,就在于要使每分片对应足够量的样本。

如上图所示,我们训练了一些数据。其显示为一个菱形的分界面,用MLR模型能够得到一个很好的结果。这里稍微插一句,这个例子只是为了展示,其实这个例子非常不好学。分片线性模型里分片隶属度一般用软的非离散的函数,这种锐角折线而非平滑曲线会使得隶属度在局部变化非常剧烈而在其它地方又很平坦,给学习造成严重的局部极值问题,所以学习到这个结果是挺不容易的。
2、使用的模型形式:分而治之

上图这个模型我们参考了MOE的模型,不过我们的形式更加泛化。借此我们用一个函数做整个空间的区域划分,在其中有参数可以跟进数据自动学习,每个区域划分都含有一个预测器。当区域划分选择Softmax时,区域内则有LR预测,这是我们主要在用的模型之一。还有一种,是MOE&LR级联,这个模型也是我们非常主要使用的模型。
从神经网络的视角看,整个特征会学到表示所有分片隶属度的的向量,也会学到每个预测器的值,不同预测器会组成一个向量,最后是两个向量作为一个内积,变成一个预估值。这其实很像神经网络的Embedding方法,或者基本上可以判断是Embedding 方法的一种。
3、如何学习参数?

一个复杂的模型,实际上对于机器学习而言,重要的是这个模型是否工作,能不能学习?这个学习也和转化形式有关。其实跟逻辑回归一样,对于特别高维度的特征而言,我们希望学习的时候也有稀疏和泛化的作用并能做特征选择,所以选择了L21范数正则做分组稀疏
为什么要分组稀疏?因为每维特征对应一组参数,这组参数在训练的时候要同时为0,这个特征才真的意味着我们在使用的时候不用了,才能做特征选择。如果这个参数里面有任何一个不为0,这个特征是不能被过滤掉的,于是我们用分组稀疏。这是机器学习里面非常经典的方法,经验损失加上正则,用L1和L21范数同时做正则。
4、目标函数分析

存在难度和挑战:非凸、非光滑、高维度
有了这个目标函数,下面最关键的是怎么优化。这里的挑战在于,前面是一个非凸函数,后面的L1范数和L21范数都是非光滑函数,就会导致困难耦合不太好解。而如果是凸问题不可导,数学上凸问题都会有次梯度,可以用次梯度方法。但是这里不是凸问题,所以次梯度不存在。
为什么不用EM算法?
并且,在大规模的互联网大数据的情况下,维度也非常高。我们如何才能找到一个快速的求解方法?EM很经典,为什么不像传统MOE一样使用EM算法?
因为EM算法只适用于概率连乘的模型形式,而我们的方法对非正则部分可导的形式通用。
其实EM算法是用E-Step把一个非凸问题变成一个凸问题,用M-Step来解这个问题,如果容易求解,EM就是合适。如果局限于MOE模型,它就会转化成凸问题,它的正则还是带着的,就变成一个参数量非常大的非光滑的凸问题,维度特别高。然而,超大维度非光滑的凸问题非常不好求解。所以这个非凸问题用EM转化并不比原始问题好求解。我们也就没有用EM,因为其并不能给实际求解带来任何的便利性。
MLR算法的特性和实验

这个算法适用于一般的经验损失加上L21正则再加上1范数正则的函数,在此其中,其关键点在于怎样求解。首先,我们证明了这个函数是处处方向可导的,虽然它可能不是处处可导的,但是它处处方向可导。这种情况下,就可以用这个方法。
为什么处处方向可导?
比如说L21范数在数学上会形成一个圆锥点,圆锥点那个点是没有切面的,所以它不可导。但是从它出发沿任何一个方向都有切线,所以其方向可导,而所有部分都方向可导,叠加起来就是处处方向可导。
这个证明也可以从我们的论文里求证,借此我们就能求出方向可导的最速下降方向。在此用最速下降方向代替梯度,用LBFGS做一个二阶加速。在其中,如OWL-QN,这是LR+L1正则,是微软提出的一个经典方法。我们像它一样进行象限约束,约束一次更新最多到达象限边界,下一次才能跨到这个象限。而Line Search是一个经典方法。我们会对收敛性做一个强保证,如果二阶加速不能下降,会直接用最速下降方向进行补偿搜索,直到两种方法都不能下降的时候才停止。
1、MLR特性:5大特点

结合前文,可将MLR的特点总结如下五点:
分而治之;
分片数足够多时,有非常强的非线性能力;
模型复杂度可控:有较好泛化能力;
具有自动特征选择作用;
可以适用于大规模高维度数据;
实验1:聚类和分类联动
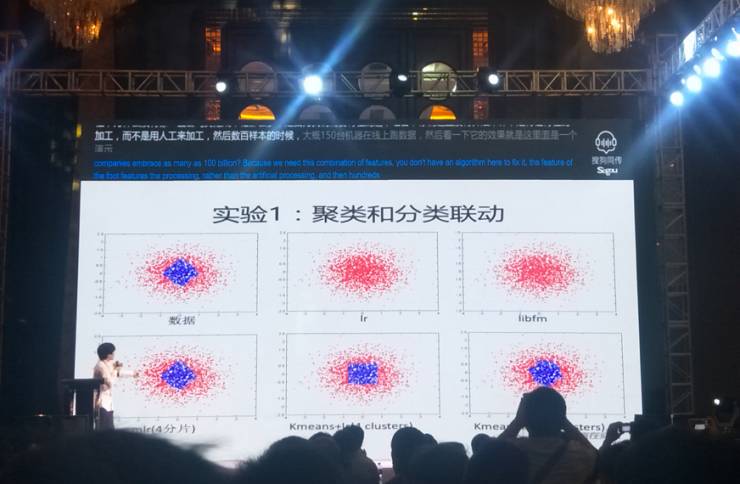
如图,这是演示的一次实验,图中第一张图表示为原始数据。像逻辑回归、二阶方法,对于高度的非线性方法都不太适合,所以基本上其结果没有什么区分能力,但是MLR能够做到非常好的区分。而利用K-means先做聚类再做分类的方法,也没办法做很好的区域划分——我们先给K-means用4分片,但其区域怎么划分和后面怎么预测不联动,所以它就变成上图第二排第二个的分界面。我们再把K-means加上10分片,其实也没有变成一个很完美的分界面。
实验2:高阶拟合
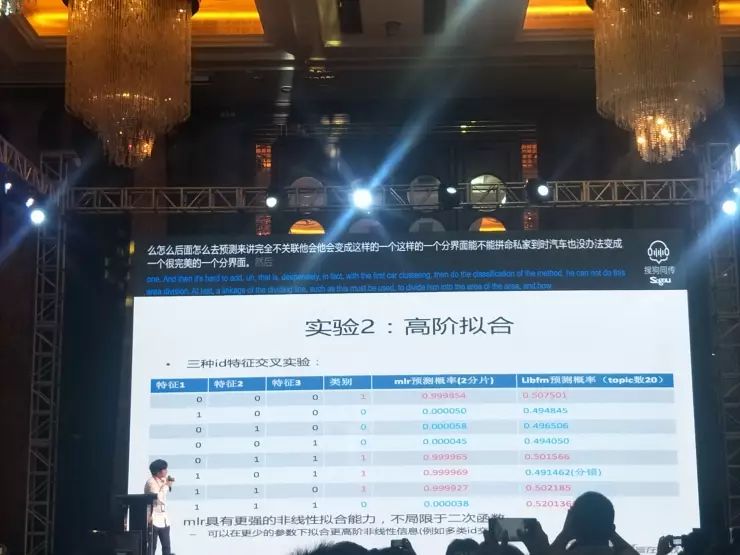
这里是一个高阶拟合应用。我们用了一组数据来验证3个ID组合的方式。3个ID组合时,Libfm是没有办法很好抓住这个组合的特性的,但是借用MLR就可以很好的实现。
2、MLR 和LR 、GBDT模型的对比
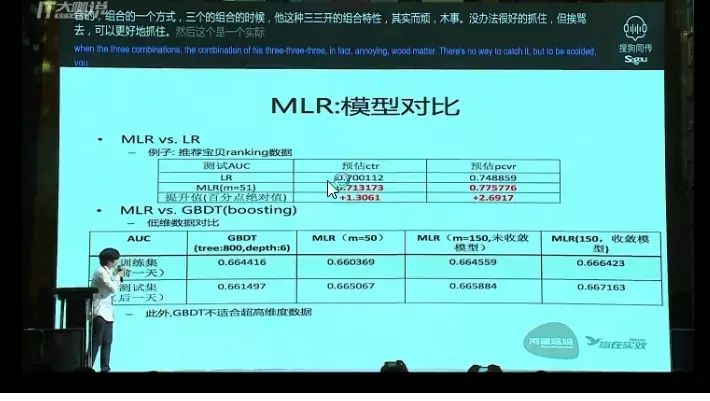
如图,是一个实际业务数据的对比。在推荐场景里,我们的MLR和LR相比而言,在CTR预估和CVR(转化率)预估上的效果都有一个非常明显的提升。和GBDT(雷锋网注:一种迭代的决策树算法)对比,这是一个稠密数据的对比,大概是400多维的稠密数据。小维度稠密数据上GBDT表现还是不错的,到400多维的时候,MLR在预测性能上就已经优于GBDT。我们特意取了MLR还未收敛,训练集准确率和GBDT相同时候的模型,会发现测试集性能已经优于GBDT。
三、大规模ID特征+MLR实践

再来说说具体的实践。当用户用到宝贝维度时,对于阿里来讲是预估一个用户对一个宝贝的CTR或者转化率。在此其中的特征设计,一般设置的是ID特征。对于用户的行为,我们会用这些元素来表示:他访问、收藏、购买过哪个店铺、哪个类目等等,一系列的行为就会变成ID特征,来表示用户行为。用户除了行为之后,还有一个用户属性特征,比如性别、年龄、地域等等。
大规模ID特征:为什么不用用户ID?





