Facebook是世界上少数几个在全球布局分布式服务的公司之一。2016年Facebook正式上线Facebook直播,加入了直播市场。前几天(4月7号)刚好是Facebook直播两周年,今天我们就来谈谈Facebook直播。
正如扎克伯格预测的那样,近年来Facebook上的视频数量直线上升。有一个经典例子就是有人直播往西瓜上套橡皮筋直至西瓜被勒炸,这段直播持续了45分钟,同时观看人数的峰值达到了80万,评论累计30万条。要知道那已经是2年前的数据,最新的数据是Facebook直播上线以来总播放量已经超过35亿次。
作为一个面向全球的产品,Facebook直播必须满足以下几个艰难的挑战:
-
在不崩溃的情况下提供数百万的并发直播流;
-
对于同一个直播流,要能支持数百万的用户;
-
必须考虑到全球观众不同网速和设备的差异;
-
与国内外其他区域性直播产品不同,几乎一直都是高峰期,所以必须保障7*24的高可用性。
-
直播的特点是非常集中的峰值流量,比如在某个名人开了直播,瞬间会有大量用户涌入,产生巨大的流量峰值,一旦直播结束,又会立即出现大量用户退出,呈现脉冲式形状。
如果是你,你会怎么设计?

“全球化”已经成为了Facebook的标签
Facebook直播的早期发展
2015年4月最初版本发布,那时只允许明星通过Mentions(页面已下架)与粉丝进行活动。
起初采用Apple的HTTP LiveStreaming协议,主要是为了使用Apple已有的CDN资源。
但是同时还开始研究基于TCP的RTMP实时消息协议,这个协议支持把流媒体从手机发送到直播流服务器,优点是RTMP可以使主播端和观众端之间的延迟降低到很低的程度,有利于主播与观众互动,缺点是这个协议不是基于HTTP的,需要开发全新的RTMP代理。
另外,Facebook还在研究MPEG-DASH(Dynamic Adaptive Streaming over HTTP,基于HTTP的动态自适应流媒体),优点是相比于HLS,空间利用率提升了15%以及允许自适应比特率,使画面质量可以根据网络状态而变化。
2015年12月Facebook直播开始在数十个国家推广。次年年4月出Facebook正式推、直播功能。
直播的特点和麻烦

上图是直播的流量曲线最开始流量上升曲线陡峭,几分钟内,每秒增加100多个请求,很可能持续到直播结束。然后增长戛然而止,呈现自由落体下降。
直播的特点是流量呈现出脉冲式的变化,这种特点极有可能导致缓存系统和负载均衡系统出现问题。
那这到底会有哪些问题呢?
首先是对缓存系统的冲击。
其次是对负载均衡系统的压力。
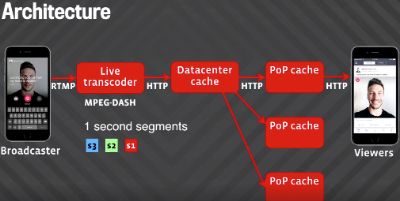
Facebook直播功能的架构图
流程概况
流媒体从主播到观众大致过程如下:
-
主播在终端发起直播
-
主播终端向服务器发起RTMP流
-
服务器对视频进行解码和转码
-
为各个比特率生成长度为一秒的MPEG-DASH片段
-
片段存储在服务器数据中心中,并传输到全球PoP缓存中
-
观众终端从PoP缓存接收一个个片段
支持扩展
所有视频片段都存储在数据中心,但用户并不直接从数据中心获取数据而是从最近的PoP缓存中获取,所以各个PoP缓存都需要支持扩展。每个PoP都有两层结构:
HTTP代理和缓存
。用户通过HTTP代理求数据,代理会检查所请求的片段是否在缓存中,如果在就直接返回,如果不在则会向数据中心发送请求。不同的片段储存在不同的缓存中实现不同缓存之间的负载均衡。
保护数据中心不受惊群效应的影响
比如直播开始的时候,所有缓存都没有直播内容,所有用户同时请求都是第一个片段,就会出现惊群效应。最好的办法就是
合并请求
,PoP在收到大量同样的请求时,只有第一个请求被发送到数据中心。其他请求一直处于阻塞状态直到第一个请求返回PoP后再返回给用户。
为避免代理服务器过载,所有的代理服务器也有另外一层缓存机制,只有第一次请求代理服务器缓存中没有的数据时,请求才会被发送到缓存。
PoP仍然是有风险——全球负载均衡
虽然数据中心已经不受惊群效应的影响,但PoP却仍然是有风险,因为每个PoP具有有限数量的服务器和连接,如果流量增加得太快可能PoP缓存的负载监控数据还没到负载均衡器,PoP缓存就先挂掉了。
我们使用了一套称为Cartographer系统来进行网络和PoP之间的映射。这套系统衡量的是网络和PoP之间的延迟。代理服务器中有计数器用于衡量他们接收的负载量,用于检测总体负载情况,这样将载荷测量延迟从1分半降低到3秒,但对于Facebook直播,3秒的延迟仍然可能是致命的。
所以
就需要对于负载变化的预判
。我们使用历史和当前的负载数据作为参数对未来负载的估算,具体的算法是
三次样条(Cubic splines)
。采用一阶和二阶导数。如果速度为正值,则负载正在增加。如果加速度为负值,则表示速度正在下降,最终将为零并开始下降。这种方法与线性插值相比可以快速预测更为复杂的负载变化。对负载的预判也减少了因数据收集延迟而造成的
震荡
调整,实现了计算资源的高效运用。目前的分析是基于最近3个30秒的数据进行,基本上可以视为瞬间的压力。










