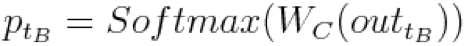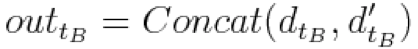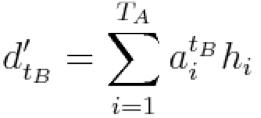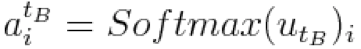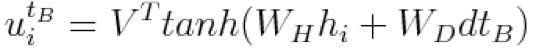生活总是忙碌,习惯的养成绝非朝夕。从本周开始,PaperWeekly 将尝试进行在线
reading group
的活动,希望忙碌着的你们,能和我们一起在阅读和学习中获得不一样的自由,获得独属于自己的乐趣。
我们的第一期阅读小组将一起精读本文,并通过在线协作工具进行交流,参与者需具备当期 topic 的研究背景,并在活动开始前完成论文阅读(活动细则详见文末)。

MAT: A Multimodal Attentive Translator for Image Captioning
文章来源:
https://arxiv.org/pdf/1702.05658.pdf
关键词
Image Captioning
,
Multimodal Translation
,
Attention
问题
针对
image captioning
问题,本文提出了一种多模态翻译模型,并且引入了新的
sequential attention
机制。
模型
1. Formulation
此前,大多数基于
CNN-RNN
的
image captioning
模型都将图像的
CNN feature
作为
RNN
的输入,但是静态的
feature
不能针对
RNN
的序列特性提供足够的信息;另一方面,一些基于
sequence
的
captioning
模型尝试在每一步都输入
CNN feature
,但实际上只是在不断强化同样的概念,并不能提供更多的语境信息。
因此,本文提出了基于
Seq2Seq
的多模态翻译模型:
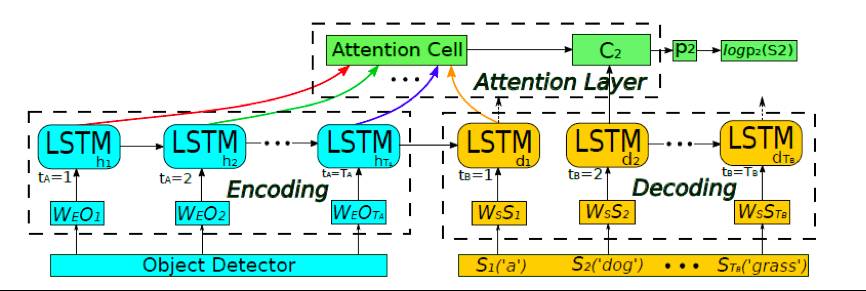
该模型的核心观点:首先对图像进行
object detection
,将检测到的
object
序列逐个输入到
RNN
中,在
decoding
阶段输出单词。图中,
**O**
为检测到的
object representation
,最后还需要输入全图的
CNN feature
作为
global environmental information
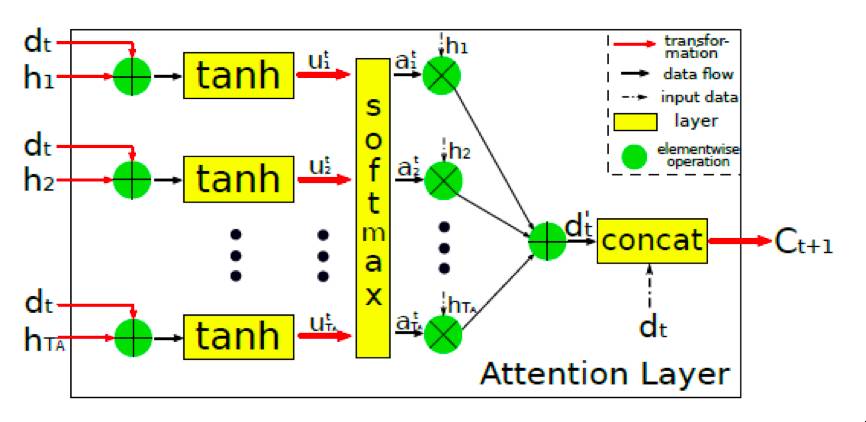
。在生成句子时,结合
encoding
的所有隐状态和
decoding
的当前状态,通过
attention layer
(见后)得出
attention vector **C**
,并在此基础上计算:
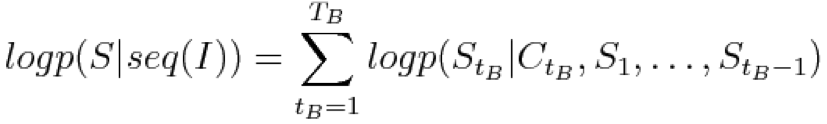
2. Seq2Seq Multimodal Translator
Source sequence representation
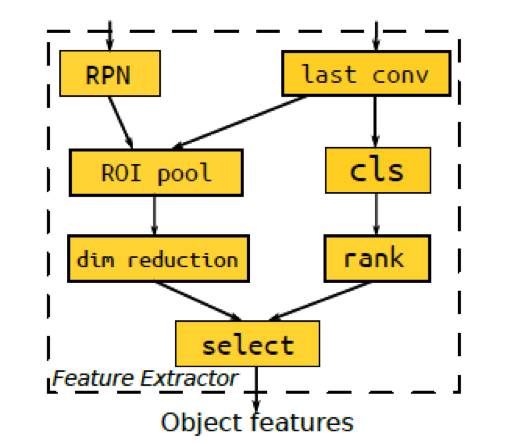
首先利用
Object feature detector
检测
object
并提取其特征,再将这些特征嵌入隐空间中。文中使用了
R-FCN
作为
detector
,并对最后一个卷积层的特征进行
roi pooling
。
Target sequence representation
每个单词都使用长度等于字典大小的
one-hot
向量表示,之后也将其嵌入至前述的隐空间中。
Sequential Attention Layer
在以往
image captioning
研究中,
attention
机制都建立在图像的
feature map
之上,这在一定程度上提高了对图像内容描述的准确度,但是并没有在
encoding
时很好地利用语境信息。
我们可以观察到,在
object sequence
中距离开头非常近的
object
可能和
decoding
时靠后的单词有较大的关联。例如,图片中可能有一只狗的检测分数最高,因而会在
encoding
时排在序列的第一位,但是“
dog”
这个词也许会出现在句子的末尾(
A man is playing with a dog
)。所以在生成单词时,作者使用了
attention layer
计算当前
decoding
状态与所有
encoding
隐状态的相关性。