

继去年AlphaGo完败围棋九段李世乭后,围棋界又迎来了新的威胁。从去年12月29日起,一名神秘棋手Master在网络对弈平台上接连挑战人类顶尖高手,打败了柯洁、朴廷桓、井山裕太等中日韩强者,甚至是有着“棋圣”之称的聂卫平。截至北京时间1月4日18时,Master已经达成56胜。这位Master究竟是谁?TA是如何做到这一切的?


Master的神秘面纱背后是……
棋手Master于去年年底首次亮相网络围棋平台弈城,在一番“大开杀戒”后继续转战野狐围棋网,与人类棋手连续对弈。根据目前的信息,Master的账户国籍为韩国,偏好快棋(30秒以内出一招),能够连续对弈,但似乎网络不太好。
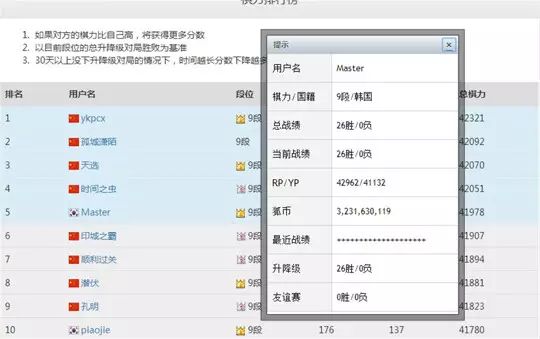
Master的下棋思维也颇为跳脱,被其打败的中国围棋九段选手柯洁和聂卫平都评价其颠覆了围棋落子的思维定式,聂卫平就惊叹,Master“在看似不能出招的地方出招,而且最后证明它的选择都成立,都不是错的!”

根据Master的“手速”和“套路”,围棋界和科技界均判断,TA可能并非人类,而是围棋AI。这让大家瞬间联想到了曾大出风头的谷歌AlphaGo,纷纷猜测这是AlphaGo的升级版,但该AI的开发团队DeepMind却一直未曾出言“认领”。事实上,截至北京时间1月4日16时,没有任何团体或个人宣布自己对Master的归属权。
Master的棋艺是如何养成的?
虽然不知道Master背后的“神秘人”究竟是谁,但我们却可以大致分析出这名“围棋黑马”的棋艺速成方式:AI的深度学习和自我学习。
养成途径1:蒙特卡洛树搜索
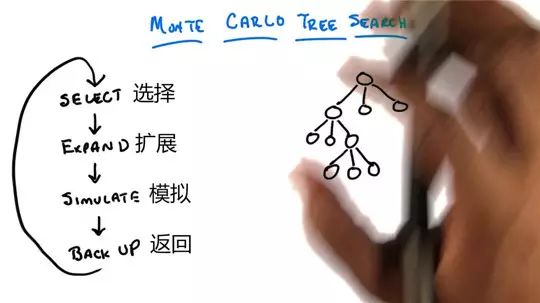
目前最为基础也是各大AI最为常用的学习方法,就是蒙特卡洛树搜索(Monte Carlo Tree Search)。这是一种在人工智能问题中做出最优决策的方法,主要是根据模拟结果,搜索并选择到达的路径,最大的优点是可以适用任何博弈游戏。简单来说,就是只要知道了最基本的围棋规则,即便对围棋定式一窍不通,也能通过蒙特卡洛树搜索达成赢棋的结果。
蒙特卡洛树搜索的算法也很“简单粗暴”,就是通过对搜索区域的随机抽样来不断扩大搜索树,分析出下一步该怎么做才最好。但需要强调的是,蒙特卡洛树搜索得到的路线并非完美路径,而是寻找通向结果的尽量最好的方式。套用一个例子来解释,就是你要从100个苹果中挑出最大的那个,你随机挑了一个,然后和另一个比较,留下最大的,如此循环。这样你每一次都能选出较大的那一个,而拿取次数越多,你拿到最大苹果的可能性就越大。

现在,许多AI都将蒙特卡洛树搜索作为“基底”,将其和其他深度学习手段联合起来,让AI变得更为聪明。
养成途径2:卷积神经网络
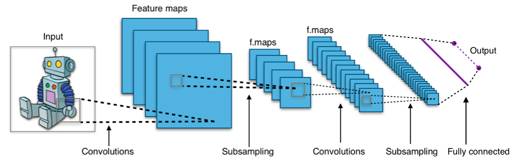
人人都知谷歌有AlphaGo,其实Facebook也同样有自己的围棋人工智能Darkforest。但与谷歌不同,Darkforest采用的是卷积神经网络(Convolutional Neural Network,缩写为CNN)和蒙特卡洛树搜索相结合的技术。卷积神经网络也是一种常见的深度学习架构,受生物自然视觉认知机制启发而来。
卷积神经网络主要的功能是能够高效识别图像,能够配合棋局模式,不断预测下一步的可能性。不过,AI通过卷积神经网络进行深度学习,需要大规模的数据库和巨大的计算能力。即是说,AI需要人工为其构建一个超大容量的图书馆,让它消耗大量时间来进行学习,学习成本比较高。
养成途径3:深度神经网络

2016年3月,世界围棋大师李世乭以1比4不敌AlphaGo,这个由谷歌旗下DeepMind公司研发的人工智能轻松拿下了韩国棋院颁发的围棋荣誉9段。AlphaGo之所以能够比此前的围棋人工智能道高一丈,主要是因为学习方式的升级。

在大数据支持的基础上,AlphaGo采用了一种叫做“深度学习”(Deep Learning)的技术,依赖2种不同的深度神经网络:“策略网络”(policy network)和 “值网络”(value network)作出判断。研发师并不用把正确的或是聪明的策略全部输入电脑中,而是让电脑在研究大量实例的基础上,进行大量博弈练习自行得出制胜策略。
在人类的大脑中,学习就是神经元间形成关系和巩固关系的过程。深度学习技术正是模拟人类脑中的神经网络,通过众多对弈实例来强化刺激系统中的节点和连结,从而对规律进行有效梳理,在大量信息中记住哪些走法和策略是最有效的。这就好像高中时,我们需要不断地通过练习、做题,确保高考时在最短的时间达到最高的正确率。
养成途径4:可微神经网络计算器

2016年10月,谷歌旗下的DeepMind再次实现了人工智能技术的突破。在科学杂志《Nature》上,他们表示已经研发出了一种可以独立学习的可微神经网络计算机(Differentiable Neural Computer,缩写为DNC)。
与AlphaGo的计算方法相比,DNC不但可以模仿神经网络的学习过程,而且能像计算机一样记忆数据。如此一来,DNC就能够通过内部记忆,而不是依靠已经庞大复杂的外部数据和程序发掘出答案。在处理问题的时候,能够进一步缩短思考时间。

目前,这些计算模型已经能够回答有关家谱图、地铁图的问题。以DNC学习家谱图为例,首先输入任意两人之间的关系,在人物关系全部录入后,DNC会自动根据节点和连结推算出答案。找到正确答案后,DNC会把这个答案记录下来,以备下次使用。同样,如果你输入伦敦地铁系统的基本信息,它可以全凭自己找到任意两个站点间的最佳线路,并且发现线路间的复杂关系。
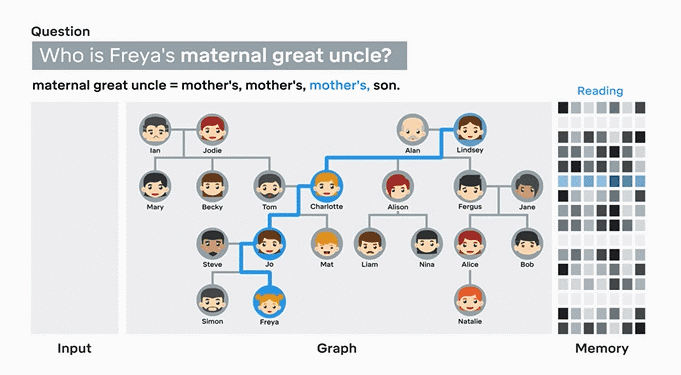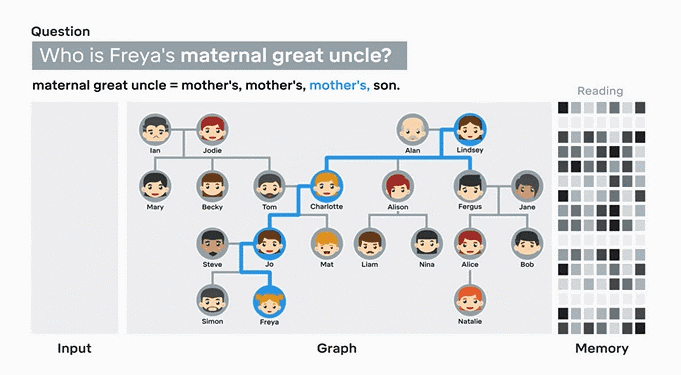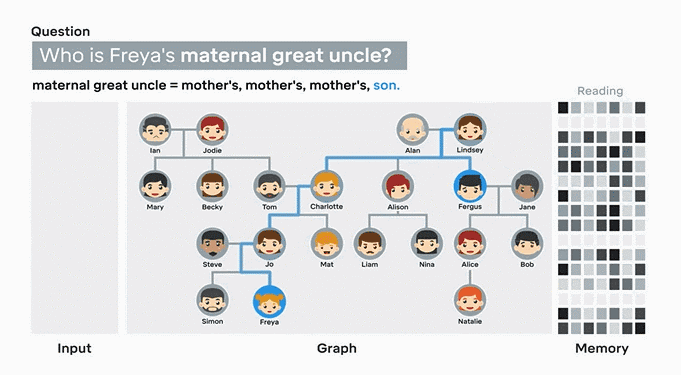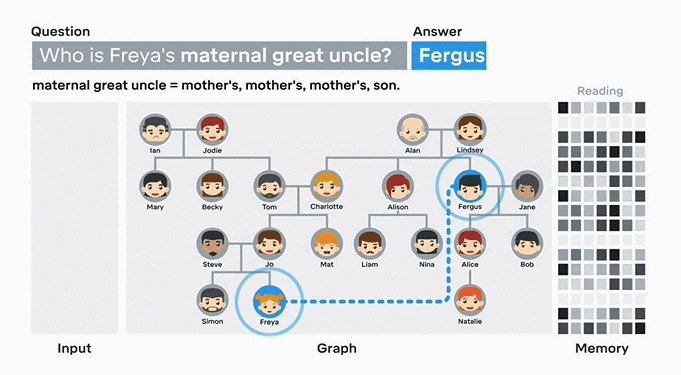
▲在49组人物关系全部输入后,提问“谁是Freya的舅舅”时,DNC能够准确地找到关联性,并得出正确答案。
可微神经网络计算机(DNC)
论学习速度,我们可能真比不过AI
事实上,AI最大的优势并不是它有多聪明,而是它能够学得飞快。通过自我学习,AI能够从一个“游戏小白”迅速成长为“高阶玩家”。比如DeepMind家的DNC,仅用了18个月就学有所成了。
DeepMind还曾研发了电子游戏人工智能Deep Q-network(DQN),令其通过“深度学习”掌握了49种电子游戏。根据开发团队的描述,DQN能够在3局内学会《太空侵略者》(Space Invaders),然后在一整晚内打到游戏排行榜最高分;能够在2小时学会弹球游戏Breakout并轻松应对快速球,4小时后能够完全掌控游戏,并开发出了游戏设计师们也不知道的击球策略。


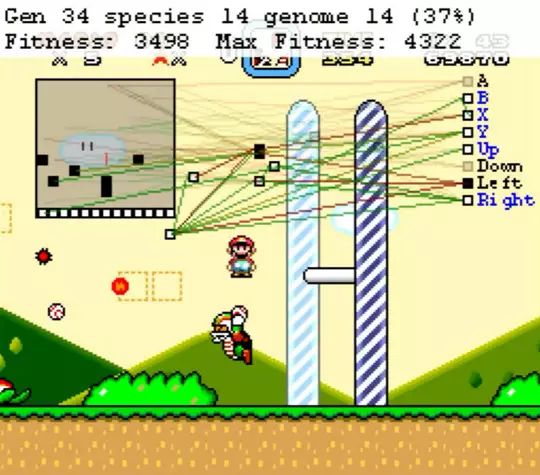
另一款由程序员Seth Bling研发的游戏人工智能MarI/O学得更快,它在进行了34次游戏后就通关了《超级马里奥》(Super Mario World)游戏。而在此之前,MarI/O完全不知道《超级马里奥》的玩法,甚至不知道游戏的终点在右边,完全是靠自我摸索。唯一令人类欣慰的是,MarI/O并不是完美通关而是专注于完成关卡,不像人类玩家,还是有很多金币被AI选手遗漏的。
AI的快速学习能力除了能在游戏等虚拟世界中成为“人生赢家”,在现实生活中也能成为“谋士”,比如说应对棘手的节能问题。2016年,DeepMind利用人工智能,在分析了庞大复杂的能源消耗数据后,成功发现了谷歌数据中心的制冷系统节能新方法。人工智能可以根据谷歌数据中心的温度、电力等不同实时因素,快速选择最有效的制冷方式,使建筑节能达到了15%。如果把这些技术应用在其他更大型的工业系统上,就会节省更多的能源开支从而保护生态环境。
所以,搅动围棋风云的Master真身究竟是谁都不重要,因为新生的AI们将随时出现,凭借他们的“超级大脑”,给人类带来新的挑战。但好在,AI毕竟还是我们人类创造的是不?













